Since transactions are running simultaneously, it is possible to have deadlocks in applications. TIBCO BusinessEvents® Extreme automatically detects deadlocks and handles them in the following manner:
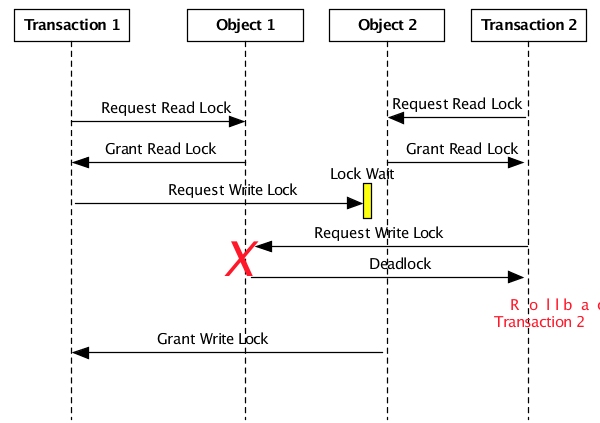
Figure 5.6, “Deadlock detection” shows a deadlock caused by these actions:
Transaction 1 requests, and is granted, a read lock on Object 1.
Transaction 2 requests, and is granted, a read lock on Object 2.
Transaction 1 requests, but is not granted, a write lock on Object 2. The write lock is not granted because of the read lock held on Object 2 by Transaction 2. Objects cannot be modified while other transactions are reading the object.
Transaction 2 requests, but is not granted, a write lock on Object 1. This is a deadlock because both transactions would block indefinitely waiting for the other to complete. Transaction 2 is chosen as the victim and rolled back.
Transaction 1 is granted the requested write lock on Object 2 because Transaction 2's read lock on Object 2 was released when Transaction 2 was rolled back.
Notice that both transactions are attempting to promote a read lock to a write lock. This deadlock can be avoided by taking the write lock initially, instead of promoting from a read lock. See the TIBCO BusinessEvents® Extreme Java Developer's Guide for details on how to use explicit locking to avoid lock promotion deadlocks.
Deadlock detection and resolution is transparent to the application programmer, but deadlocks are expensive in both responsiveness and machine resources so they should be avoided.
Local transactions detect deadlocks immediately in the execution path. There is no timeout value associated with local transactions.
Distributed transactions use a configurable time-out value to detect deadlocks. If a lock cannot be obtained on a remote node within the configured time-out period, the distributed transaction is rolled back, releasing all locks. The transaction is then restarted.
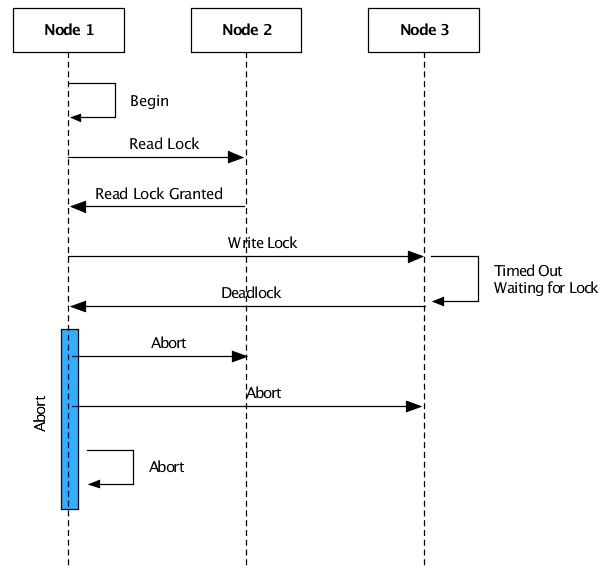
Because distributed deadlock detection is based on a time-out, applications with distributed deadlocks will perform poorly because the configured time-out has to be large enough to ensure that there are never any false deadlocks reported during normal application processing.