To support high-availability configurations and to balance application workload across multiple machines, application objects are organized into partitions.
A partition is identified by a name. Partition names must be globally unique for all nodes in a cluster. Each partition is associated with a node list consisting of one or more nodes. The node list is specified in priority order. The highest priority available node in the node list is the active node for the partition. All other nodes in the node list are replica nodes for the partition. Replica nodes can use either synchronous or asynchronous replication (see the section called “Replication”).
If the active node becomes unavailable, the next highest available replica node in the node list automatically becomes the active node for the partition.
All objects in a partition with replica nodes have a copy of the object state transparently maintained on replica nodes. These objects are called replica objects.

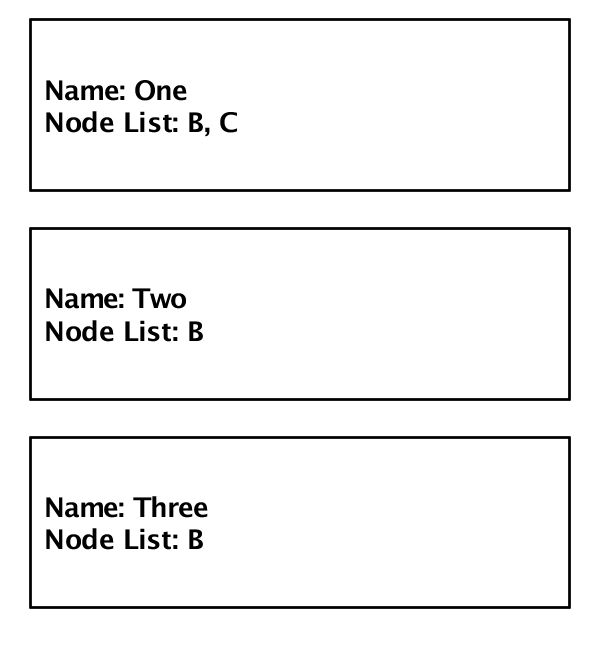
Figure 7.1, “Partition definitions” defines three partitions named
One, Two, and
Three. Partitions One and
Two support replication of all contained objects, with
node B replication done synchronously and node C replication done
asynchronously. Partition Three has only a single node
B defined so there is no replication in this partition.
All objects assigned to partition Three during creation
are transparently created on node B. A node
A failure will cause the active node for partition
One and Two to change to node
B. A node B failure has no impact on
the active node for partition One and
Two, but it causes all objects in partition
Three to be lost since there is no other node hosting
this partition.
Figure 7.2, “Sparse partition” shows three nodes,
A, B, and C,
and a partition P. Partition P is
defined with an active node of A and a replica node
of B. Partition P is also defined on node
C but node C is not in the node
list for the partition. On node C, partition P is considered a
sparse partition.
The partition state and node list of sparse partitions is maintained as the partition definition changes in the cluster. However, no objects are replicated to these nodes, and these nodes cannot become the active node for the partition. When an object in a sparse partition is created or updated, the create and update is pushed to the active and any replica nodes in the partition.
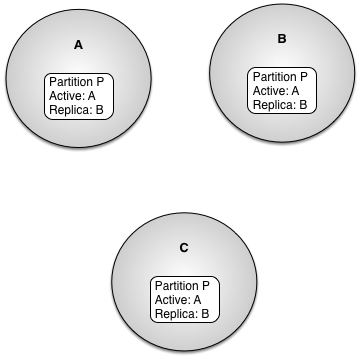
Sparse partition definitions are useful for application specific mechanisms that require a node to have a distributed view of partition state, without being the active node or participating in replication.
Partitions are defined directly by the application or an administrator on a running system. Partitions should be defined and enabled (see the section called “Enabling and disabling partitions”) on all nodes on which the partition should be known. This allows an application to:
immediately use a partition. Partitions can be safely used after they are enabled. There is no requirement that the active node has already enabled a partition to use it safely on a replica node.
restore a node following a failure. See the section called “Restore” for details.
As an example, here are the steps to define a partition P in a cluster with an active node of A and a replica node of B.
Nodes A and B are started and have discovered each other.
Node A defines partition P with a node list of A, B.
Node A enables partition P.
Node B defines partition P with a node list of A, B.
Node B enables partition P.
Partition definitions can be redefined to allow partitions to be migrated to different nodes. See the section called “Migrating a partition” for details.
The only time that node list inconsistencies are detected is when object re-partitioning is done (see the section called “Updating object partition mapping”), or a sparse partition is being defined.
Once, a partition has been defined, it must be enabled.
Enabling a partition causes the local node to transition the partition
from the Initial state to the
Active state. Partition activation may include
migration of object data from other nodes to the local node. It may also
include updating the active node for the partition in the cluster.
Enabling an already Active partition has no
affect.
Disabling a partition causes the local node to stop hosting the partition. The local node is removed from the node list in the partition definition on all nodes in the cluster. If the local node is the active node for a partition, the partition will migrate to the next node in the node list and become active on that node. As part of migrating the partition all objects in the partition on the local node are removed from shared memory.
When a partition is disabled with only the local node in the node list there is no impact to the objects contained in the partition on the local node since a partition migration does not occur. These objects can continue to be read by the application. However, unless the partition mapper is removed, no new objects can be created in the disabled partition because there is no active node for the partition.
When a partition is defined, the partition definition is
broadcast to all discovered nodes in the cluster. The
RemoteDefined status (see the section called “Partition status”) is used to indicate a partition
that was remotely defined. When the partition is enabled, the partition status
change is again broadcast to all discovered nodes in the cluster. The
RemoteEnabled status (see the section called “Partition status”) is used to indicate a partition
that was remotely enabled.
While the broadcast of partition definitions and status changes can eliminate the requirement to define and enable partitions on all nodes in a cluster that must be aware of a partition, it is recommended that this behavior not be relied on in production system deployments.
The example below demonstrates why relying on partition broadcast can cause problems.
Nodes
A,B, andCare all started and discover each other.Node
Adefines partitionPwith a node list ofA,B,C. Replica nodesBandCrely on the partition broadcast to remotely enable the partition.Node
Bis taken out of service. Failover (see the section called “Failover”)changes the partition node list toA,C.Node
Bis restarted and all nodes discover each other, but since nodeBdoes not define and enable partitionPduring application initialization the node list remainsA,C.
At this point, manual intervention is required to redefine
partition P to add B back as a
replica. This manual intervention is eliminated if all nodes always
define and enable all partitions during application
initialization.
A partition with one or more replica nodes defined in its node list will failover if its current active node fails. The next highest priority available node in the node list will take over processing for this partition.
When a node fails, it is removed from the node list for
the partition definition in the cluster. All undiscovered nodes in the
node list for the partition are also removed from the partition
definition. For example, if node A fails with the
partition definitions in Figure 7.1, “Partition definitions” active, the
node list is updated to remove node A leaving these
partition definitions active in the cluster.
Once a node has been removed from the node list for a partition, no communication occurs to that node for the partition.
A node is restored to service by defining and enabling all partitions that will be hosted on the node. This includes partitions for which the node being restored is the active or replica node. When a partition is enabled on the node being restored partition migration occurs, which copies all objects in the hosted partitions to the node.
To restore node A to service after the failure
in the section called “Failover”, requires the following
steps:
define and enable partition
Onewith active nodeAand replicasBandC.define and enable partition
Twowith active nodeAand replicaB.
After these steps are executed, and partition migration completes,
node A is back online and the partition definitions
are back to the original definitions in Figure 7.1, “Partition definitions”.
Partitions can have one of the following states:
Table 7.1. Partition states
Figure 7.4, “Partition state machine” shows the state machine that controls the transitions between all of these states.
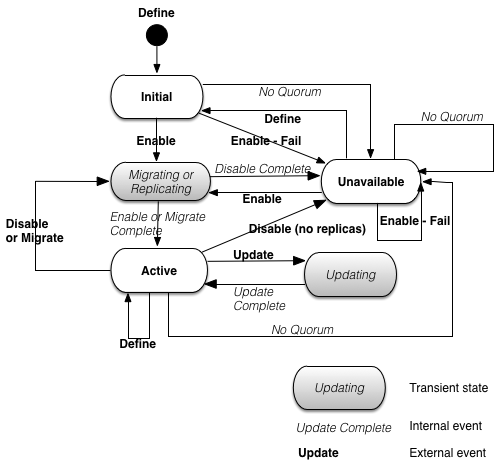
The external events in the state machine map to an API call or an administrator command. The internal events are generated as part of node processing.
Partition state change notifiers are called at partition state transitions if an application installs them. Partition state change notifiers are called in these cases:
the transition into and out of the transient states defined in Figure 7.4, “Partition state machine”. These notifiers are called on every node in the cluster that has the notifiers installed and the partition defined and enabled.
the transition directly from the
Activestate to theUnavailablestate in Figure 7.4, “Partition state machine”. These notifiers are only called on the local node on which this state transition occurred.
Partitions also have a status, which defines how the local definition of the partition was done, and whether it has been enabled. The valid states are defined in Table 7.2, “Partition status”.
Table 7.2. Partition status
All of the partition status values are controlled by an
administrative operation, or API, on the local node except for the
RemoteEnabled and RemoteDefined
statuses. The RemoteEnabled and
RemoteDefined statuses occurs when local partition
state was not defined and enabled on the local node, it was only updated
on a remote node.
If the local node leaves the cluster and is restarted, it must redefine and enable a partition locally before rejoining the cluster to rejoin as a member of the partition. For this reason it is recommended that all nodes perform define and enable for all partitions in which they participate, even if they are a replica node in the partition.