Workflow integration
Workflow users tasks
Beyond configuring the add-on to make it responsible for creating workflows (see process policy), it is possible to design and integrate any bespoke workflow. These workflows are then based on user tasks and scripts provided with the add-on.
To get samples of workflow please contact our professional service team.
Special notation: | |
|---|---|
| Please refer to the online documentation in the EBX® workflow modeling domain to get further information about the parameters available to configure the workflow users tasks and scripts. |
(Full) Data quality stewardship
User task | Overview |
|---|---|
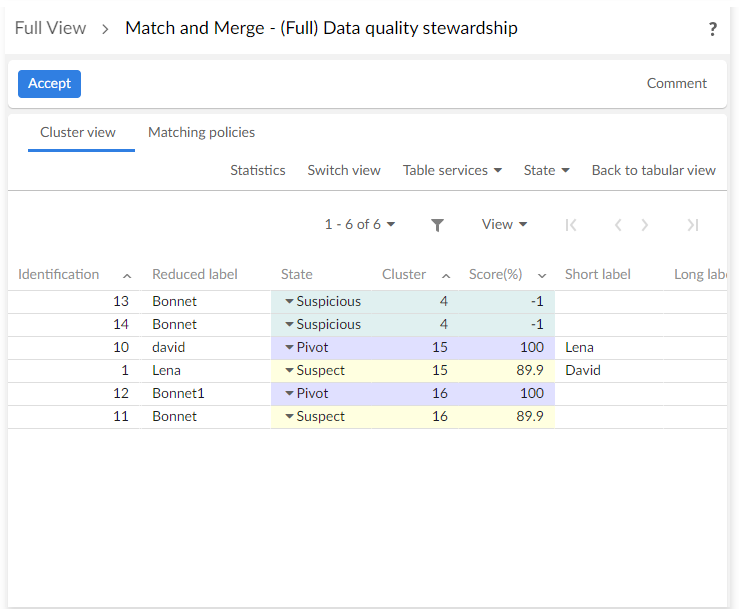
(Full) Data quality stewardship task |
|
Data context | |
Branch (dataspace), instance (dataset), xpath (table), selectClusterId, selectRecord | |
Use | |
For experimented. Provide all matching operations. |
(Light) Data quality stewardship
User task | Overview |
|---|---|
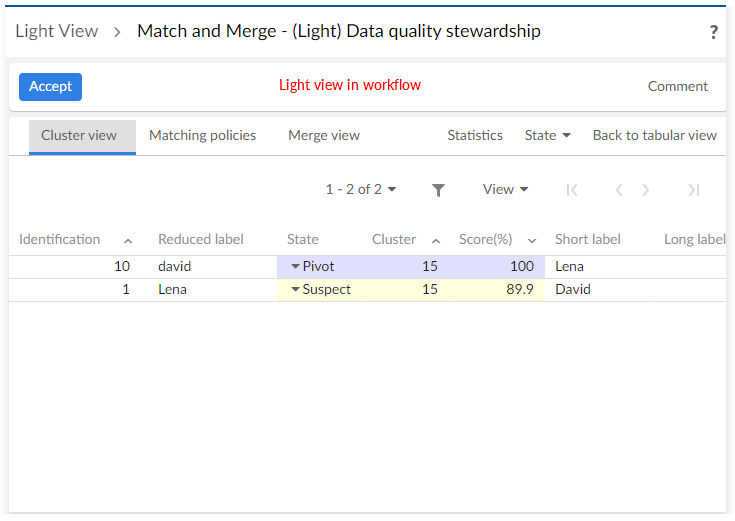
(Light) Data quality stewardship task Note that when creating and configuring this type of task, an OR operation applies to the Cluster to select and XPath predicate of record to select options. If both options are configured, priority is given to the cluster. Also, when you configure the XPath predicate of record to select option, all records in the cluster display—not just the selected record. |
|
Data context | |
Branch (dataspace), instance (dataset), xpath (table), selectClusterId, selectRecord | |
Use | |
To manage a list of suspect records in a cluster. |
Simple matching
User task | Overview |
|---|---|
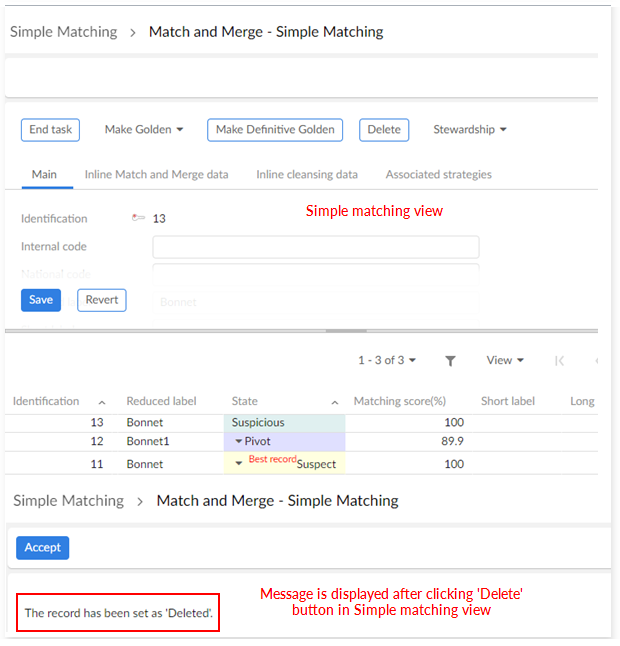
Simple matching task |
|
Data context | |
Branch (dataspace), instance (dataset), xpath (table and record ID) | |
Use | |
To manage a suspicious record against a list of potential suspect records. |
Merge view
User task | Overview |
|---|---|
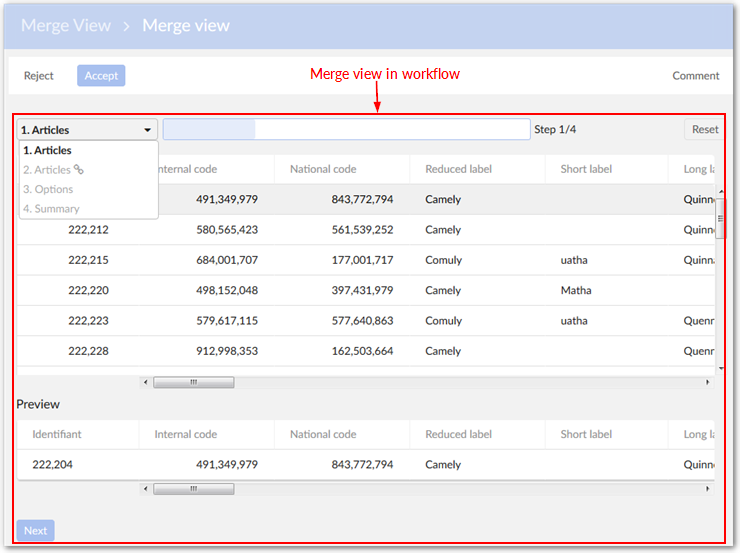
Merge task |
|
Data context | |
Branch (dataspace), instance (dataset), xpath (table and record ID) | |
Use | |
For users managing a set a suspect records. |
Search before create
User task | Overview |
|---|---|
Search before create |
|
Data context | |
Branch (dataspace), instance (dataset), xpath (table) | |
Use | |
This task allows users to search for a record before potentially duplicating a record. |

Workflow scripts and conditions
This section describes workflow scripts and conditions bundled with the add-on.
Feed data context with metadata from a record
This script is run to feed a data context with a record's matching metadata: state, score, cluster, and a custom label.
Remove all workflow metadata for the current workflow
By default, the add-on avoids creating duplicate workflows on the same record. In other words, a record cannot have more than one active workflow at a time. To ensure this rule, a matching metadata is used to state if a workflow has been created on a record.
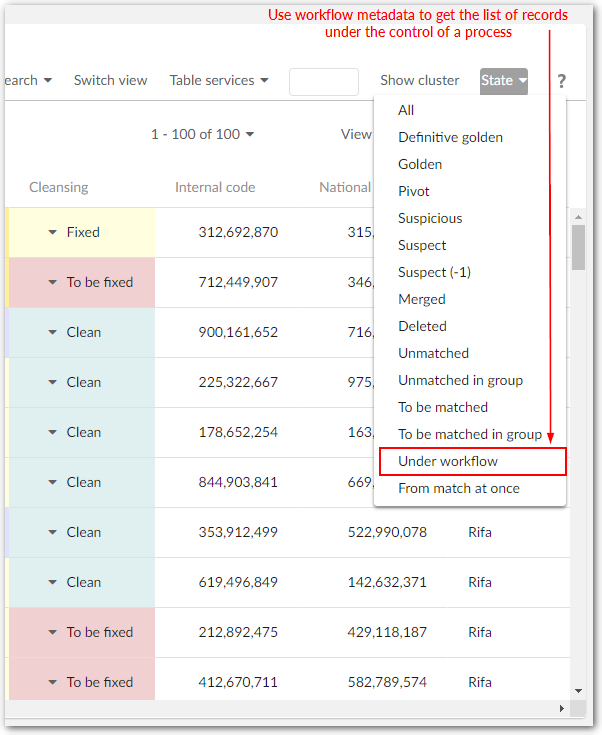
This is the responsibility of the workflow to reset this metadata, and then to allow a new workflow creation. This reinitialization is executed by the 'Remove all workflow metadata for the current workflow' script.
This metadata is also used by the 'Under workflow' service to get the list of all records under the control of a process.
Feed workflow metadata
A workflow not initiated by the add-on can feed the workflow metadata of a record using this script. Therefore the record will be known as 'under workflow' by the add-on. This metadata has to be removed at the end of the workflow using the script described above 'Remove all workflow metadata for the current workflow'.
Change state of a record to suspicious
The record state moves to the 'Suspicious' state.
Simulate the match table operation
The result is a list of all records that match without changing their states. The list is empty if no match.
Check if a record is in a given state
Condition. The result is a boolean.
Align foreign keys
All foreign keys related to the table managed by the add-on are checked. The check includes foreign keys in the table on which the service is executed (in case of self-referencing relationships). The scope of the services includes all related dataspaces and datasets. When a foreign key is linked to a merged record, the add-on automatically updates it with the correct target record in the appropriate dataspace and dataset. For more information on service behavior, see Align foreign keys of all merged records.