Contents
![]() A Union operator accepts two or more input streams and produces one output stream in the order the tuples arrive. With the
default Loose union setting, The ordering of tuples by a Union operator is not sensitive to the values of fields arriving on its input ports.
If you want to order tuples based on field values (such as sequence IDs), consider using a Merge operator.
A Union operator accepts two or more input streams and produces one output stream in the order the tuples arrive. With the
default Loose union setting, The ordering of tuples by a Union operator is not sensitive to the values of fields arriving on its input ports.
If you want to order tuples based on field values (such as sequence IDs), consider using a Merge operator.
Let's say that you have installed StreamBase in a store with 20 checkout lines. After each sale each cash register outputs onto a stream a tuple that contains the amount, the number of items, and the cashier's name. Your StreamBase application must take all of the data from all of the streams and sum up all of the sales so that the store can track the total amount of sales every hour of each day. The Union operator is used to join all of the cash register streams into one stream so that a single Aggregate operator can be used to sum all of the data from each of the cash registers.
You can choose between three levels of schema compatibility:
- Loose union
-
By default, tuples arriving on different input ports can have different schemas, as long as all fields with the same name are of the same data type. When an input tuple on one stream is missing fields that exist on another input port, the union fills them in with null fields. With this setting, field order is not considered, including the order of sub-fields of tuple fields.
For example, it is possible to perform a loose union of two input streams whose schemas have these fields:
Input Port 1 Schema Input Port 2 Schema string Symbol string Symbol double Price
The following two events show the output when data arrives on each port:

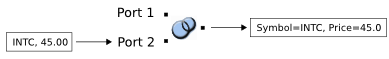
- Strict union
-
In a strict union, schemas must have the same fields with the same data types, and the fields must be in the same order. Typechecking fails if the input streams do not have equivalent schemas. Strict unions are possible only in EventFlow applications; In the StreamSQL language, all unions are loose.
Tip
One way to make schemas equivalent is by using a Map operator before the Union operator to reorder fields.
- Declared schema
-
You can declare the exact schema that tuples must have as they exit the operator.
The Union operator does not try to order tuples on its input ports based on field values, but only considers tuple arrival order. Thus, the output directly reflects the sequence of arriving tuples on the input streams. For example, consider the union of two streams with the same schema consisting of a single int field. Notice that tuples are output in first-in, first-out order without regard to the value in the int field:
 |
 |
 |
Drag an arc from an upstream component to the bottom left edge of a Union operator. When a small gold plus appears, release the cursor and drop the onto the operator. This creates a new input port automatically and increments the count of input ports on the Union Settings tab of the Properties view.
When you delete an arc entering a Union operator, or you delete the component immediately upstream of such an arc, the corresponding input port is automatically removed from the Union operator, and the count of input ports on the Union Settings tab is decremented.
Name: Use this field to specify or change the component's name, which must be unique in the application. The name must contain only alphabetic characters, numbers, and underscores, and no hyphens or other special characters. The first character must be alphabetic or an underscore.
Enable Error Output Port: Select this check box to add an Error Port to this component. In the EventFlow canvas, the Error Port shows as a red output port, always the last port for the component. See Using Error Ports and Error Streams to learn about Error Ports.
Description: Optionally enter text to briefly describe the component's purpose and function. In the EventFlow canvas, you can see the description by pressing Ctrl while the component's tooltip is displayed.
The Union Settings tab has two controls:
-
In the Number of input ports control, specify the number of streams that will participate in the union operation.
-
In the Schema matching control, select one of the options described in the following table:
Setting Effect on the schema of this output stream Union all input fields Select this option to specify the default loose typechecking of the schemas of incoming tuples. With loose typechecking, the schema of this operator's output port represents the union of all fields on all input ports. If any fields are different, nulls are filled in when an input tuple on one port does not have that field on another port. It is still a typecheck error if more than one input port's schema has a field with same field name but different data types. Require strictly matching schemas Select this option to specify strict typechecking of the schemas of tuples arriving on the operator's input ports. Strict typechecking means the field names, data types, and field order of all fields on one input port must exactly match the field names, order, and types on all other input ports. Require this schema Select this option to declare the exact schema that you expect tuples to have as they exit this Union operator. By declaring an expected output schema, you ask StreamBase to compare the schemas received by this operator to the specified schema, and to report any discrepancies as typecheck errors. Selecting this option opens a standard schema fields grid that lets you specify a private schema field by field, or select a named schema from the drop-down list, or copy a schema from another component. This option is best used with a named schema that specifies the same schema for this Union operator and for all upstream operators that feed into this Union.
Use the Concurrency tab to specify the use of parallel regions for this instance of this component. Consider selecting the parallel regions check box if this component instance is long-running or compute-intensive, can run without data dependencies on other StreamBase components, and would not cause the containing module to block while waiting for a thread to return. In this case, you may be able to improve performance by selecting this option. This option directs StreamBase Server to process this component concurrently with other processing in the application. The operating systems supported by StreamBase automatically distribute the processing of threads across multiple processors.
Caution
The parallel regions setting is not suitable for every application, and using this setting requires a thorough analysis of your application. For details, see Execution Order and Concurrency, which includes important guidelines for using the concurrency options.