Contents
- Introduction
- Load and Run the Embedded Publisher Sample
- Publisher Configuration
- Container Connections
- Ease of Table Configuration
- Persistence and Recovery
- Periodic Compression of Recovery Files
- Walk-Through of the ItemsSalesPublisher Adapter
- Creating a New Embedded Publisher
- Modifying the Embedded Publisher Sample
A LiveView embedded publisher is a StreamBase EventFlow application that runs in the context of LiveView and publishes data to one or more data tables in a LiveView project. The embedded publisher can push data to an existing table without the table needing to be reconfigured.
A publisher differs from a data source in that a data source can only publish to one table (although a table can have multiple data sources). This figure shows a simple data-source model:
 |
This figure shows a simple publisher model:
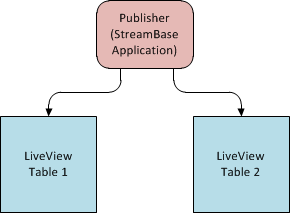 |
Another important difference between these two models is that the data-source has to be configured within the table configuration to which it sends data. A publisher is not mentioned in a table's lvconf file; the publisher itself specifies what table or tables it sends data to.
This page describes the Embedded Publisher sample. TIBCO recommends that you use this sample as a model for developing your own embedded publishers.
First, if you have not already done so, load the Hello LiveView sample. The embedded publisher sample is based on the Hello LiveView sample, so it is useful to have the Hello LiveView sample available for review.
Now, load and run the "Shows an embedded publisher application" sample. Follow these steps:
-
Start in StreamBase Studio, in the SB Authoring perspective.
-
Load the Embedded Publisher sample.
-
Select → from Studio's top-level menu.
-
In the Load StreamBase Projects dialog, open the TIBCO Live Datamart category.
-
Make sure that the Open the selected sample's README file after importing check box is selected.
-
Select the sample whose description is
Shows an embedded publisher applicationand press .
The sample loads into Studio with the project name
sample_lv-publisher. The README file in the sample's top-level folder contains valuable information on the sample and how it works. -
-
In the Package Explorer view, select the name of the project, right-click, and from the context menu, select → . The Console view shows several messages as the LiveView Server compiles the project and starts.
-
When you see message
All tables have been loadedin the Console view, start LiveView Desktop:-
On Windows, run → → → → .
-
On Linux, run the following command:
/opt/tibco/sb-cep/
n.m/liveview/desktop/liveview &
-
-
In LiveView Desktop, connect to LiveView Server with → . Enter your username and the default URL,
lv://localhost:10080
Adding an embedded publisher to LiveView requires a LiveView configuration file describing the publisher. In this sample, the lvconf file called ItemsSalesPublisher.lvconf configures the publisher. The root element of this configuration file is <liveview-configuration>, as is true for all LiveView configuration files.
The <publisher> element contains attributes that specify the embedded publisher name, description, and the location of the StreamBase application writes to the LiveView tables. The publisher element of the ItemsSalesPublisher.lvconf file is shown here:
<!-- This file configures an embedded publisher for the ItemsSales
and Categories tables. -->
<publisher
id="ItemsSalesPublisher"
description="Publishes to the ItemsSales table"
short-description="ItemsSales Table Publisher"
filename="ItemsSalesPublisher.sbapp">
<!-- The LiveView tables this publisher publishes to, in this case
ItemsSales and Categories. -->
<tables>
<table table-ref="ItemsSales"/>
<table table-ref="Categories"/>
</tables>
</publisher>These attributes of the <publisher> element are:
- id
-
Unique string identifier for the publisher (required).
- description
-
A full description of the publisher (optional).
- short-description
-
Optional short descriptive name (optional).
- filename
-
The EventFlow application that writes the data to LiveView tables (required).
The <tables> element is a child of the <publisher> element. This element contains one or more <table> child elements. The
<table> attribute table-ref is the name of the project table to which the publisher sends data. The <tables> element of the ItemsSalesPublisher.lvconf
file is shown here. It will publish to the ItemsSales table and the Categories table.
<tables> <table table-ref="ItemsSales"/> <table table-ref="Categories"/> </tables>
The publisher configures the input and output streams for publication in the project tables. When LiveView Server starts it
establishes the connections between the project containers so that data is published in the selected tables. You can see how
this works by looking at how the project containers are connected. To do this, open a StreamBase command-line prompt. The
sbc list -C ItemsSalesPublisher container-connections command shows all container connections to the ItemsSalesPublisher container (in the example below, long lines wrap to the
next line for legibility):
>sbc list -C ItemsSalesPublisher container-connections container-connections Categories.DataIn=ItemsSalesPublisher.PublishToCategoriesOut container-connections Categories.QueryTheLastGoodRecord=ItemsSalesPublisher. QueryTheLastGoodRecordOut container-connections ItemsSales.DataIn=ItemsSalesPublisher.PublishToItemsSalesOut container-connections ItemsSales.QueryTheLastGoodRecord=ItemsSalesPublisher. QueryTheLastGoodRecordOut container-connections ItemsSalesPublisher.ServerStatusIn=default.ServerStatus container-connections ItemsSalesPublisher.TheLastGoodRecordIn=Categories.TheLastGoodRecordOut container-connections ItemsSalesPublisher.TheLastGoodRecordIn=ItemsSales.TheLastGoodRecordOut
The container-connections connect destination streams to source streams. So, for example, the statement:
ItemsSales.DataIn=ItemsSalesPublisher.PublishToItemsSalesOut
assigns the output stream PublishToItemsSalesOut to the ItemsSales table stream DataIn. Every LiveView table receives data from a DataIn stream.
An embedded publisher can publish data to tables without those tables being configured to call the publisher. This means that the lvconf files for individual tables do not need to have data-sources individually configured. Compare ItemsSales.lvconf from the Hello LiveView sample to ItemsSales.lvconf in the publisher sample. In the publisher sample, the ItemsSales table gets data from the configured publisher. The table's lvconf file does not have a data-source configured:
<data-table id="ItemsSales"
table-space-ref="PersistentTableSpace"
short-description="Quantity and last-sold prices"
description="Live view of all items, the quantity in stock
and the last sold price">
<fields>
<field name="transactionID" type="long"/>
<field name="transactionTime" type="timestamp"/>
<field name="Item" type="string"/>
<field name="category" type="string"/>
<field name="quantityRemaining" type="int"/>
<field name="lastSoldPrice" type="double"/>
</fields>
<primary-key>
<field ref="transactionID"/>
</primary-key>
</data-table>In contrast, the ItemsSales table in the Hello LiveView sample receives data from a data-source, in this case, an application called from the project folder ItemsDataSource. The Hello LiveView ItemsSales.lvconf file looks like this:
<data-table id="ItemsSales"
short-description="Sales transactions"
description="Live view of all items sold over time, the quantity in stock
and the last sold price">
<fields>
<field name="transactionID" type="long"/>
<field name="transactionTime" type="timestamp"/>
<field name="Item" type="string"/>
<field name="category" type="string"/>
<field name="quantityRemaining" type="int"/>
<field name="lastSoldPrice" type="double"/>
</fields>
<primary-key>
<field ref="transactionID"/>
</primary-key>
<data-sources>
<data-source>
<application application-ref="ItemsSalesDataSource" output-stream="DataOut"/>
</data-source>
</data-sources>
</data-table>Live Datamart supports both peer-based and log-based persistence and recovery options, as explained below.
You can configure peer-based recovery for a LiveView server to either recover from a service interruption, or to add a new LiveView server to an existing group of already-running servers. Peer recovery is configured per table, and each table can have the same or a different list of recovery partners. In order for a configured peer to participate in recovery:
-
It must be in the READY state.
-
It must have the exact same table configuration as the table in question.
-
Both the recovering and peer servers are configured to be published to with the same data from the same persistent message bus.
Live Datamart iterates through the peer recovery list until it finds a peer that meets the requirements. A server with peer recovery configured on one or more tables fails to start if successful recovery cannot be completed from a peer.
There are some limitations on how and when peer based recovery should be used. A recovering peer based server makes one StreamBaseClient connection for each configured snapshot-parallelism to the selected recovery partner. All the data for each snapshot-parallel region is transferred over the network. This requires very high network bandwidth between recovery partners.
Servers configured to be recovery partners must have extra heap memory allocated to accommodate the demand surge that may accompany a recovery request. An initial estimate is to add between one half and up to one times the size of each table that may be recovered.
TIBCO strongly recommends increasing the max-client-pages setting in the server's page-pool element. An initial estimate is to set (TableSize/snapshot-parallelism) / 4096.
It is essential that you stress-test your peer-based recovery configurations in conditions and sizes that exceed expected production conditions and sizes. Misconfigured systems can result in servers being unable to recover from a peer and can also cause the recovery partner to fail.
In addition to the peer-based option described above, LiveView tables can be configured for persistence such that their contents are saved to disk in log-based files and recovered from these files after a crash or server restart. Part of the recovered data is the table’s publisher sequence number. During initialization, an embedded publisher typically retrieves the sequence number for each persistent table and resumes publishing at that point, to avoid overwriting previously written, recovered records.
For publisher initialization, the publisher interface has an Input stream name ServerStateIn that Live Datamart uses to inform the publisher of the server state during initialization. This stream has two fields:
-
Name (string) — can be ignored.
-
CurrentState (int):
-
0 = Recovery in progress; the publisher may begin querying the server on the
QueryTheLastGoodRecordOutport and begin its recovery procedure. -
1 = Recovery complete for all publishers.
-
2 = Server recovery has failed. By default, the server shuts down.
-
The publisher interface has an Output stream named PublisherStateOut that publishing applications must use to inform the server that they have completed recovery, whether successfully or unsuccessfully.
The PublisherStateOut stream has the same fields as ServerStateIn, with these definitions:
-
Name — Must be the name of the publisher
-
CurrentState :
-
0 = Recovery in progress
-
1 = Recovery completed successfully and normal publishing has begun
-
2 = Recovery has failed
-
Ideally, publishers report recovery complete when they finish catching up to the current real time data from their data source. Reporting complete before this time (for example reporting complete as soon as an adapter has connected to the data source) means that clients might connect and issue queries to Live Datamart and not see up-to-date data.
For publishing EventFlow applications that do not wish to implement recovery at all, use a Map operator between ServerStateIn and PublisherStateOut. In that operator, set the Name field to the name of the publisher, with the CurrentState field set to 1.
The embedded publisher interface provides two streams for retrieving the publisher sequence number:
-
QueryTheLastGoodRecordOut — An embedded publisher emits a tuple on this output stream to request sequence number information for a specific table. This stream has the following schema:
-
CQSConnectionID (string) — An embedded publisher-provided value that is echoed in the response, allowing the publisher to match requests with responses.
-
PublisherID (string) — The ID of the embedded publisher that was used to publish the existing records to the LiveView table prior to the crash or restart. A null requests sequence number information for all previous publishers of the table.
-
Tablename (string) — The name of the LiveView table for which sequence number information is being requested. A null requests sequence number information for all the tables this publisher is publishing to.
-
-
TheLastGoodRecordIn — Responses to the query on the last good record requests arrive on this data stream. If the PublisherID was null in the request, a response is received for each publisher of the LiveView table. This stream has the following schema:
-
CQSConnectionID (string) — The value echoed from the query of the last good record.
-
PublisherID (string) — The ID of the publisher for which sequence number information is provided. This value is normally echoed from the query of the last good record. If the PublisherID was null in the request, a response is received for each previous table publisher. A null in this field identifies this as a punctuation tuple, which indicates all recovery information has been returned for the specified table.
-
LowestPublishedSN — The lowest published sequence number available across all the parallel regions comprising the LiveView table.
-
LowestPersistedSN — The lowest persisted sequence number available across all the parallel regions comprising the LiveView table. In recovering after a server restart, an embedded publisher typically resumes publishing from this value.
-
HighestPublishedSN — The highest published sequence number available across all the parallel regions comprising the LiveView table.
-
HighestPersistedSN — The highest persisted sequence number available across all the parallel regions comprising the LiveView table.
-
Tablename (string) — The name of the LiveView table for which sequence number information is provided. This value is normally echoed from the query of the last good record. If the Tablename was null in the request, a response is received for each LiveView table being published to.
-
The publisher, in requesting last good record information, has the option of specifying:
-
A table name,
-
A publisher ID,
-
Both a table name and a Publisher ID, or
-
Neither a table name nor a publisher ID.
Specifying a null table name in the request retrieves information for all tables being published to, while specifying a null publisher ID requests the last good record for all previous publishers to the table(s).
In response to a “query the last good record” request, LiveView Server returns one or more tuples for each table specified in the request. If the table name is null in the request, the server returns responses for all tables being published to; otherwise it returns responses for just the specified table.
The last response tuple returned by LiveView Server for each table is a punctuation tuple, which does not carry last good record information (all sequence number fields are null) and is identified by a null in the
PublisherID field. All tuples returned by the server, including punctuation tuples, have a non-null Tablename field.
Thus, in response to a “query the last good record” request, the publisher should expect either one punctuation tuple, if
the Tablename field was non-null in the request, or one punctuation tuple per table the publisher is configured to publish to, if the Tablename field was null in the request. The number of tables the publisher is configured to publish to is equal to the number of top-level
fields present in the PublishSchemasIn input stream's schema.
The following example presents a publish scenario followed by the recovery activity for each of the four “query the last good record” request combinations.
Published tuples:
(Publisher A, 1) -> Table-X (Publisher A, 2) -> Table-Y (Publisher B, 3) -> Table-X (Publisher B, 4) -> Table-Y (Publisher C, 5) -> Table-X (Publisher D, 6) -> Table-Y
If publisher sends request with PublisherID == null, Tablename == null, server returns:
(Publisher A, Table-X, 1) (Publisher B, Table-X, 3) (Publisher C, Table-X, 5) (null, Table-X, null) <- punctuation table for Table-X (Publisher A, Table-Y, 2) (Publisher B, Table-Y, 4) (Publisher D, Table-Y, 6) (null, Table-Y, null) <- punctuation table for Table-Y
If publisher sends request with PublisherID == Publisher A, Tablename == null, server returns:
(Publisher A, Table-X, 1) (null, Table-X, null) (Publisher A, Table-Y, 2) (null, Table-Y, null)
If publisher sends request with PublisherID == null, Tablename == Table-X, server returns:
(Publisher A, Table-X, 1) (Publisher B, Table-X, 3) (Publisher C, Table-X, 5) (null, Table-X, null) <- punctuation table for Table-X
If publisher sends request with PublisherID == Publisher A, Tablename == Table-X, server returns:
(Publisher A, Table-X, 1) (null, Table-X, null)
Note
When responding to query the last good record requests for multiple tables (Tablename is null) the response tuples for the tables are generated in parallel and can therefore be interspersed. However, the punctuation
tuple is always the last tuple returned for a specific table.
By default, LiveView persistence log files roll every 12 hours, or when they reach 100 MB in size. The following system properties configure the roll time and size, with their default values shown:
liveview.store.rollinterval.s=43200 liveview.store.file.max.mb=100
The roll size limit is the compressed size of one of the snapshot-parallelism regions. This generally makes correlating the amount of data published to the table with the size of the log file imprecise. Use the following formula to obtain an approximate log size value:
(published data size) / (snapshot-parallelism * 2)
During recovery from a service interruption, LiveView Server reads all log files and recovers data to the state it was in at the time of the interruption, as described in the previous section. No additional log file maintenance is likely to be needed for sites that cycle LiveView Server periodically — perhaps daily — and, before the server is restarted, delete all log files, such that the new day's LiveView table is started empty.
For sites where continuous LiveView Server uptime is required, and the published data is updated and/or deleted as a normal part of LiveView operations, log file disk space consumption may become an issue. For these use cases, there is a command named lv-store-vacuum that you can run on the directory that contains the table's log files. Running this command is an external administrative operation, and should be run at an off peak time. LiveView Server can be running while the command proceeds, but does not have to be.
The lv-store-vacuum command traverses all rolled log files in the persistence log directory and preserves only current data in a temporary log
file. That is, the command reads all .restore files in that directory (but not the currently in-use .db file), then dumps all deleted rows to a new, temporary log file and consolidates all updated rows into a single entry in
the temporary log. This preserves only the most recent row value from the table in the temporary log file. When the command
finishes, the previously rolled log files are moved to a backup directory, and the just-created single temporary log file
is renamed such that it will be used for the next recovery event.
LiveView administrators must periodically purge old rolled log files from the specified backup directory, following your site's backup and log storage policies.
The LiveView embedded publisher sample consists of a StreamBase application, ItemsSalesPublisher.sbapp, whose key component is an embedded input adapter, ItemsPublisher.java. The adapter source code is provided with the sample and is intended to be used as a starting point for LiveView customers
creating their own embedded publishers.
Double-click the application name in Package Explorer view to open this application in the EventFlow editor.
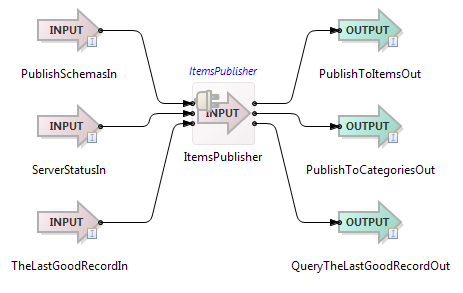 |
The adapter has three input streams and three output streams corresponding to streams of the LiveView-created interface for the publisher. The first input stream, PublishSchemasIn, has two fields of type tuple that convey the schemas of the adapter’s first two output ports. No tuples flow through this stream; it is used strictly to convey schema information, allowing the adapter to set the schemas of its first two output ports, which are used to publish to the ItemsSales and Categories tables.
The second input stream, ServerStatusIn, allows the adapter to determine when the LiveView server is ready to accept published tuples. Its single input field, IsReady, contains true when the LiveView server is ready.
The third input stream and third output stream are used to retrieve sequence numbers during recovery, as described above.
The adapter emulates the data source used by the Hello LiveView sample. It creates a fixed set of 33 SKUs for which price and volume information is published to the ItemsSales table. The adapter’s Tuples per Second property determines the rate at which tuples are published. To illustrate multi-table publishing, the adapter publishes to a second table, Categories, a mapping of category names to descriptions. A second property, Log Level, controls the adapter’s verbosity of logging.
During initialization, the adapter’s typecheck() method validates its property values and the schemas of its input ports, sets the schemas of its output ports, and creates
cached tuples for publishing to the ItemsSales and Categories tables. The adapter’s init() method then generates the 33 SKUs used for publishing to the ItemsSales table and registers its run() method, which executes once the adapter completes initialization.
The adapter’s processTuple() method is invoked when a tuple is received on one of its input ports. When a server status tuple arrives indicating the LiveView
server is ready, the adapter sets a flag that signals its run() method to begin publishing.
The adapter’s run() method executes once initialization is complete. It polls the LiveView server ready flag used to commence publishing, sleeping
in between to avoid a CPU spin loop. Once LiveView is ready, the adapter emits a tuple on its QueryTheLastGoodRecordOut port
to retrieve the ItemsSales table’s sequence number at which to resume publishing. The ItemsSales table, being persistent,
might contain previously-written, recovered records that should not be overwritten. The response to the “query the last good
request” comes in via a tuple to the adapter’s processTuple() method on its TheLastGoodRecordIn port. The lowest persisted sequence number from this table is saved and subsequently used
by the run() method in publishing to the ItemsSales table. The adapter’s run() method publishes once to the (static) Categories table a mapping of names to descriptions.
The adapter then begins publishing to the ItemsSales table. The adapter publishes at the rate specified by its Tuples per Second property. During each one-second interval, it attempts to spread the publishing of tuples evenly across the remaining time in this interval. For example, if the adapter is configured to publish 10 tuples per second, it sleeps approximately 100 ms between publishing each tuple. The sleep time is adjusted during the interval to account for the time spent doing the actual publishing.
Creating an embedded publisher involves the following three steps:
-
Create an embedded publisher .lvconf file
This can be accomplished in StreamBase Studio or with any standard text editor. If done in Studio, content assistance is available.
-
Create an embedded publisher interface file.
The embedded publisher .lvconf file should be placed in the new LiveView project’s top-level directory. The embedded publisher interface file is then generated with the command:
lv-server compile
path-to-lv-project-dir -
Create a StreamBase application that implements the interface. An embedded publisher application that implements the new interface is created in Studio’s SB Authoring perspective as follows:
-
The directory containing the new interface file must be on the project’s module search path. Right-click the project folder and select → .
-
Select → → from the top-level menu.
-
Select the check box.
-
Click .
-
Click
-
Browse to the interface file created above.
-
Add one or more StreamBase operators that connect the input and output streams and perform the actual publishing.
-
This section shows you how to modify the embedded publisher sample application by having it publish to a third LiveView table. It assumes you have loaded the sample in Studio, as described above.
-
Add a new LiveView configuration file for the additional table you intend to publish to. Follow the steps shown here. For example, right-click the project folder in the Package Explorer view, select → , and enter
MyTable.lvconfin the LiveView Configuration file name field. -
Add a data-table tag to the MyTable.lvconf file and enter values for the table-space-ref and id attributes as follows:
<data-table table-space-ref="PersistentTableSpace" id="MyTable"> <fields> <field name="pkey" type="string" /> <field name="val" type="string" /> </fields> <primary-key> <field ref="pkey"/> </primary-key> </data-table>These values represent a minimum configuration for a new table.
-
Open the embedded publisher LiveView configuration file, ItemsSalesPublisher.lvconf, in the LiveView Configuration File Editor.
-
In the
<tables>section, add a new XML element<table>that references the new table you named in step (1):<tables> <table table-ref="ItemsSales"/> <table table-ref="Categories"/> <table table-ref="MyTable"/> </tables> -
From a StreamBase Command Prompt or terminal window, generate an interface for the new table with a command like the following:
lv-server generate --type tableschemas \ --tables MyTable <path-to-embedded-publisher-sample>
-
From a StreamBase Command Prompt or terminal window, update the publisher interface to include the new table with a command like the following:
lv-server generate --type publisher \ --tables ItemsSales,Categories,MyTable \ --force <path-to-embedded-publisher-sample>
-
From a StreamBase Command Prompt or terminal window, recompile the embedded publisher project using a command like the following:
lv-server compile <path-to-embedded-publisher-sample>
When the message "LiveView compiled configuration is available at ..." appears on the screen, the project has recompiled successfully.
-
In Studio, open
ItemsSalesPublisher/ItemsSalesPublisher.sbapp, right-click the canvas and select -
Click the Definitions tab. In the Manage Interfaces pane, click Add Missing Items… and click .
-
In the Editor tab, connect the fourth output port of the ItemsSalesPublisher input adapter to the PublishToMyTableOut output stream and save the result.
-
Run the modified sample. Right-click its top-level folder in the Package Explorer and select → .
When LiveView Server starts, the ItemsSales table will receive data. If this happens, you have successfully created a new output port and table for the project.
-
When done, stop LiveView Server in Studio by clicking the red square Terminate button (
 ) in the Console View's toolbar.
) in the Console View's toolbar.
You can now open the ItemsSales Publisher input adapter source module, ItemsPublisher.java, and add code to the run method to publish to the MyTable LiveView table by emitting tuples on the new output port.