히트맵
히트맵을 이해하는 가장 쉬운 방법은 값 자체가 아닌 숫자 값이 색상 셀로 표시되는 크로스 테이블 또는 스프레드시트를 생각하는 것입니다. 기본 색 그라데이션에서는 히트맵의 최소값을 진한 파랑으로, 최대값을 연한 빨강으로, 중간 범위 값을 연한 회색으로 설정하고, 양쪽 극값 사이에 해당 전환(또는 그라데이션)을 적용합니다.
히트맵은 대량의 다차원 데이터를 시각화하는 데 매우 적합하고 유사한 값이 있는 행의 클러스터가 유사한 색으로 표시되므로 이러한 행 클러스터를 식별하는 데 사용할 수 있습니다.
예
아래 예에서는 테이블의 값이 히트맵 셀에 색 그라데이션으로 어떻게 표시되는지를 보여 줍니다.
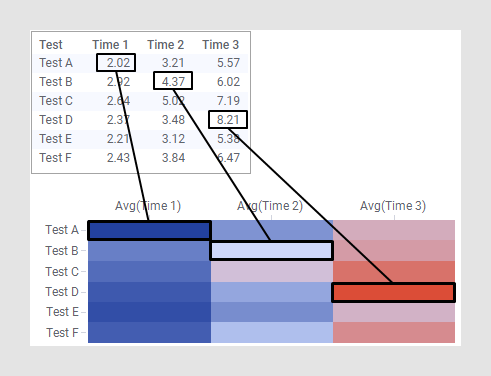
아래 예에 나오는 대로 히트맵을 구성하는 방법은 데이터 형식에 따라 다릅니다.
길고 좁은 형식의 데이터
이 예에서 데이터는 길고 좁은 형식이고 각 데이터 테이블 행은 히트맵의 단일 셀에 해당합니다.
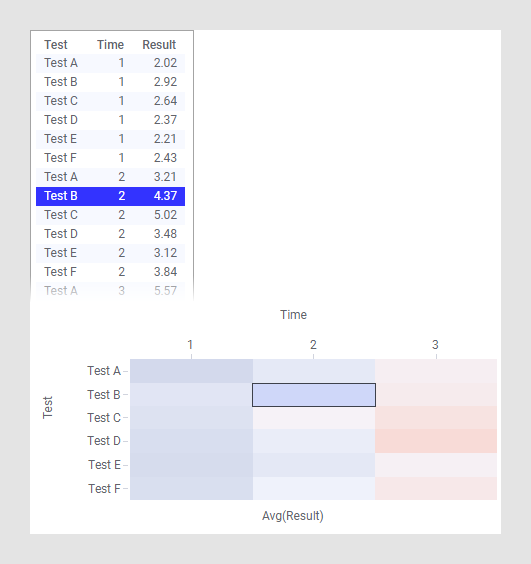
Y축에서 테스트 컬럼을 선택하고, X축에서 시간을 선택하며, 셀 값은 결과 컬럼으로 설정합니다 다른 시각화에서와 같이, 히트맵의 강조 표시 및 마킹은 기본 데이터 테이블에 있는 하나 이상의 행에 적용됩니다. 즉, 이 예에 나온 구성으로 테이블에 있는 행을 마크하면 히트맵의 셀이 마크됩니다.
짧고 넓은 형식의 데이터
이 예에서는 데이터가 짧고 넓은 형식이고, 데이터 테이블의 각 행이 히트맵의 전체 행에 해당됩니다.
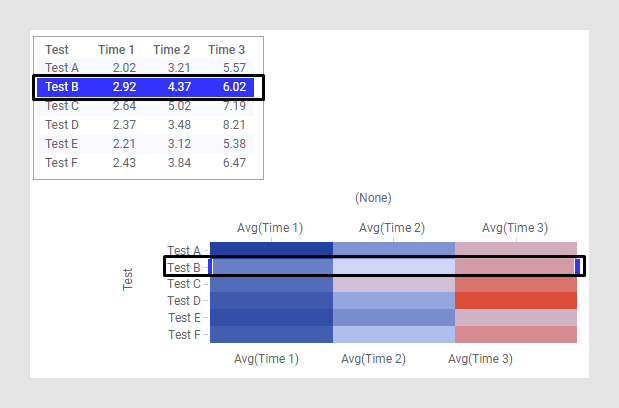
히트맵의 Y축은 테스트 컬럼에서 설정되는 반면에, X축은 (없음)으로 설정됩니다. 히트맵의 각 셀 값의 경우, 시간 1, 시간 2, 시간 3 컬럼이 선택됩니다. Y축이 (행 번호)로 설정되지 않는 한, 셀 값 컬럼은 항상 집계됩니다. 이는 데이터 테이블에 동일한 이름을 사용하는 행이 많고, 해당 행의 값이 하나의 값으로 집계되어 히트맵에 표시되기 때문입니다. 데이터 내용은 길고 좁은 형식으로 표시된 데이터가 포함된 예와 동일하지만, 데이터 형식으로 인해 히트맵을 다른 방법으로 구성해야 합니다. 짧고 넓은 형식의 데이터를 사용하여 히트맵을 구성하는 일반적인 방법입니다.
계통수
항목 간의 거리 또는 유사성을 기반으로 계층에서 항목을 정렬하는 방법인 계층적 군집분석에 히트맵을 결합하는 것이 좋은 경우도 있습니다. 선택한 거리 측정에 따라, 군집분석 계산 결과는 클러스터링된 항목 간의 거리 또는 유사성으로 제공됩니다.
히트맵에서 행과 컬럼을 모두 군집분석할 수 있습니다. 계층적 군집분석 계산의 결과는 히트맵에 계통수로 표시됩니다. 계통수는 계층의 트리 구조입니다. 행 계통수는 행 사이의 거리 또는 유사성을 표시하며 각 행이 속하는 노드는 군집분석 계산의 결과입니다. 열 계통수에서는 변수(선택한 셀 값 컬럼) 사이의 거리 또는 유사성을 표시합니다.
아래 예제에는 행 간 거리가 계산된 행 계통수가 포함된 히트맵이 표시됩니다.

군집분석 계산의 결과로 히트맵의 행이 군집분석 계산과 일치하도록 다시 정렬되었습니다. 테스트 A와 테스트 E는 동일한 클러스터에 배치됩니다. 테스트 F와 테스트 B는 다른 클러스터에 함께 배치되며, 이 클러스터는 테스트 C와 함께 다른 클러스터를 형성합니다. 테스트 D는 어느 클러스터에도 포함되지 않습니다. 즉, 테스트 A와 테스트 E는 테스트 F, 테스트 B, 테스트 C 또는 테스트 D와의 거리보다 서로 더 가까이 있습니다. 또한 테스트 D는 다른 모든 행으로부터 가장 멀리 있습니다.