통계 함수
목록에는 표현식에 사용할 수 있는 통계 함수가 나와 있습니다.
| 함수 | 설명 |
|---|---|
Avg(Arg1, ...)
| 인수의 평균(산술 평균)을 반환합니다.인수 및 결과는 실수 형식입니다.인수를 한 개 지정한 경우 결과는 모든 행의 평균이 됩니다.인수를 여러 개 지정한 경우 결과는 각 행의 평균이 됩니다.Null 인수는 무시되므로 평균값에 영향을 주지 않습니다. 예:
|
ChiDist(Arg1) | 인수의 (위 꼬리) 카이제곱 p 값을 반환합니다. 예:
|
ChiInv(Arg1) | 인수의 (위 꼬리) 카이제곱 변위치 값을 반환합니다. 예:
|
Count(Arg1) | 인수 컬럼에서 비어 있지 않은 값 수를 계산합니다. 인수를 지정하지 않은 경우 행의 총수를 계산합니다. 예:
|
CountBig(Arg1) | 인수 컬럼에서 비어 있지 않은 값 수를 계산합니다. 인수를 지정하지 않은 경우 행의 총수를 계산합니다.이 함수는 LongInteger를 반환합니다. 예:
|
Covariance(Arg1,
Arg2)
| 인수로 지정된 두 컬럼의 공분산을 계산합니다. 예:
|
FDist(Arg1) | 인수의 위 꼬리 F p 값을 반환합니다. 예:
|
FInv(Arg1) | 인수의 위 꼬리 F 변위치 값을 반환합니다. 예:
|
First(Arg1)
| 인수 컬럼에서 데이터 행의 물리적 순서를 기반으로 첫 번째 유효 값을 반환합니다. 예:
|
GeometricMean()
| 기하학적 평균 값을 계산합니다.입력 값이 음수이면 결과는 "비어 있음"입니다.입력 값이 0이면 결과는 0입니다. 예:
|
IQR(Arg1)
| 값 차이 Q3-Q1 또는 75번째 백분위수 - 25번째 백분위수를 계산합니다.IQR을 H 분포라고도 합니다. 예:
|
L95(Arg1)
| 95% 신뢰 구간의 하위 끝점을 계산합니다. 주: 이 함수에서 사용하는 고정 t-값 1.959964는 큰 샘플 크기( n >= 40)에 맞춰 조정된 것입니다.샘플 크기가 이보다 작은 경우에는 다음 표현식을 대신 사용합니다.
예:
|
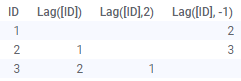
Lag(Arg1,
Arg2) | 컬럼의 값을 지정된 단계 수만큼 아래로 전환합니다.첫 번째 인수는 전환할 컬럼입니다.두 번째(선택 항목) 인수는 단계 수입니다.기본값은 1입니다. 음수의 단계 수를 사용하면 아래 이미지처럼 값이 반대 방향으로 전환됩니다. 예:
Lag 함수는 데이터가 로드된 순서에 따라 데이터 적용됩니다. 즉, 함수는 시각화의 정렬을 고려하지 않으며, 데이터의 변경(예: 다시 로드 도중)으로 여러 행의 값이 달라질 수 있습니다. |
Last(Arg1) | 인수 컬럼에서 데이터 행의 물리적 순서를 기반으로 마지막 유효 값을 반환합니다. 예:
|
LastValueForMax(Arg1,
Arg2) | column 1의 최대값에 대한 column 2의 값을 반환합니다. 컬럼 1 최대값이 둘 이상인 경우 결과는 마지막 최대 행의 값이 됩니다. 예:
|
LastValueForMin(Arg1,
Arg2)
| column 1의 최소값에 대한 column 2의 값을 반환합니다. 컬럼 1 최소값이 둘 이상인 경우 결과는 마지막 최소 행의 값이 됩니다. 예:
|
LAV(Arg1) | 인접한 하위 값을 계산합니다. 예:
|
Lead(Arg1,
Arg2)
| 컬럼의 값을 지정된 단계 수만큼 위로 전환합니다.첫 번째 인수는 전환할 컬럼입니다.두 번째(선택 항목) 인수는 단계 수입니다.기본값은 1입니다. 음수의 단계 수를 사용하면 아래 이미지처럼 값이 반대 방향으로 전환됩니다. 예:
Lead 함수는 데이터가 로드된 순서에 따라 데이터 적용됩니다. 즉, 함수는 시각화의 정렬을 고려하지 않으며, 데이터의 변경(예: 다시 로드 도중)으로 여러 행의 값이 달라질 수 있습니다. |
LIF(Arg1)
| 하위 내부 펜스를 계산합니다.Q1 - (1.5*IQR)에 있는 임계값입니다.예:
|
LOF(Arg1)
| 하위 외부 펜스를 계산합니다.Q1 - (3*IQR)에 있는 임계값입니다.예:
|
Max(Arg1, ...)
| 최대값을 계산합니다.인수를 한 개 지정한 경우 결과는 전체 컬럼의 최대값입니다.인수를 여러 개 지정한 경우 결과는 각 행의 최대값이 됩니다.인수 및 결과는 실수 형식입니다.Null 인수는 무시됩니다. 예:
|
MeanDeviation(Arg1, ...)
| 평균 편차 값(평균 절대 편차, AAD)을 계산합니다.인수를 한 개 지정한 경우 결과는 모든 행의 평균 편차가 됩니다.인수를 여러 개 지정한 경우 결과는 각 행의 평균 편차가 됩니다. 예:
|
Median(Arg1)
| 인수의 중앙값을 계산합니다.인수를 한 개 지정한 경우 결과는 모든 행의 중앙값이 됩니다.인수를 여러 개 지정한 경우 결과는 각 행의 중앙값이 됩니다. 예:
|
MedianAbsoluteDeviation(Arg1,
...) | 중앙값 절대 편차(MAD)를 계산합니다.인수를 한 개 지정한 경우 결과는 모든 행의 중앙값 절대 편차가 됩니다.인수를 여러 개 지정한 경우 결과는 각 행의 중앙값 절대 편차가 됩니다. 예:
|
Min(Arg1,
...) | 최소값을 계산합니다.인수를 한 개 지정한 경우 결과는 전체 컬럼의 최소값입니다.인수를 여러 개 지정한 경우 결과는 각 행의 최소값이 됩니다.인수 및 결과는 실수 형식입니다.Null 인수는 무시됩니다. 예:
|
NormDist(Arg1) | 인수의 (위 꼬리) 일반 p 값을 반환합니다.이 값을 지정하지 않으면 결과는 평균=0, 표준 편차=1이 됩니다. 예:
|
NormInv(Arg1)
| 인수의 (위 꼬리) 일반 변위치 값을 반환합니다.이 값을 지정하지 않으면 결과는 평균=0, 표준 편차=1이 됩니다. 예:
|
NthLargest(Arg1,
Arg2)
| n번째 가장 큰 값입니다.첫 번째 인수는 분석할 컬럼이며 두 번째 인수는 n의 값입니다. n이 컬럼의 값 수보다 큰 경우 가장 작은 값이 반환됩니다. 예:
|
NthSmallest(Arg1,
Arg2)
| n번째 가장 작은 값입니다.첫 번째 인수는 분석할 컬럼이며 두 번째 인수는 n의 값입니다. n이 컬럼의 값 수보다 큰 경우 가장 큰 값이 반환됩니다. 예:
|
Outliers(Arg1) | 외부 값 계산.상위 인접한 값보다 크거나 하위 인접한 값보다 작은 값의 개수를 계산합니다. 예:
|
P10(Arg1)
| 10번째 백분위수는 데이터 값의 10%가 값보다 작거나 같은 값입니다. 예:
|
P90(Arg1)
| 90번째 백분위수는 데이터 값의 90%가 값보다 작거나 같은 값입니다. 예:
|
PctOutliers(Arg1) | 외부 값 백분위수.상위 인접한 값보다 크거나 하위 인접한 값보다 작은 값의 비율을 계산합니다. 예:
|
Percent(Arg1,
Arg2)
| 백분율은 값 범위(최대값 - 최소값) 내에서 최소값을 초과하는 특정 비율을 계산한 값입니다.첫 번째 인수는 분석할 컬럼이며 두 번째 인수는 백분율입니다. 예:
|
Percentile(Arg1,
Arg2)
| 백분위수는 데이터 값의 특정 비율이 값보다 작거나 같은 값입니다.첫 번째 인수는 분석할 컬럼이며 두 번째 인수는 백분율입니다. 예:
|
Q1(Arg1) | 첫 번째 사분위수를 계산합니다. 예:
|
Q3(Arg1)
| 세 번째 사분위수를 계산합니다. 예:
|
Range(Arg1) | 컬럼에서 가장 큰 값과 가장 작은 값 사이의 범위입니다. 결과는 인수의 데이터 형식에 따라 실수 또는 시간대로 반환됩니다. 예:
|
StdDev(Arg1)
| 표준 편차를 계산합니다. 예:
|
StdErr(Arg1)
| 표준 오차를 계산합니다. 예:
|
TDist(Arg1) | 인수의 (위 꼬리) t p 값을 반환합니다. 예:
|
TERR_Binary | TIBCO Enterprise Runtime for R 엔진을 호출하여 함수 이름에 의해 입력과 같은 수의 행을 포함하는 지정된 데이터 형식의 출력을 반환합니다. 첫 번째 인수는 스크립트이며 그 다음의 인수는 스크립트에 대한 인수입니다. 반환되는 컬럼은 입력과 동일한 수의 행을 포함해야 합니다.스크립트 이외의 인수가 하나 이상 필요합니다.입력은 예:
|
TERR_Boolean | 위의 TERR_Binary를 참조하십시오. |
TERR_DateTime | 위의 TERR_Binary를 참조하십시오. |
TERR_Integer | 위의 TERR_Binary를 참조하십시오. |
TERR_Real | 위의 TERR_Binary를 참조하십시오. |
TERR_String | 위의 TERR_Binary를 참조하십시오. |
TERRAggregation_Binary | TIBCO Enterprise Runtime for R 엔진을 호출하여 지정된 데이터 형식의 출력을 반환합니다.첫 번째 인수는 스크립트이며 그 다음의 인수는 스크립트에 대한 인수입니다. 스크립트는 집계된 단일 값을 반환해야 합니다.스크립트 이외의 인수가 하나 이상 필요합니다.입력은 예:
|
TERRAggregation_Boolean | 위의 TERRAggregation_Binary를 참조하십시오. |
TERRAggregation_DateTime | 위의 TERRAggregation_Binary를 참조하십시오. |
TERRAggregation_Integer | 위의 TERRAggregation_Binary를 참조하십시오. |
TERRAggregation_Real | 위의 TERRAggregation_Binary를 참조하십시오. |
TERRAggregation_String | 위의 TERRAggregation_Binary를 참조하십시오. |
TInv(Arg1) | 인수의 (위 꼬리) t 변위치 값을 반환합니다. 예:
|
TrimmedMean(Arg1,
Arg2) | 잘라낸 평균값(잘라낸 평균)을 계산합니다.첫 번째 인수는 분석할 컬럼이고 두 번째 인수는 계산에서 제외할 값의 수(%)입니다.자르기 값을 10%로 설정한 경우 가장 큰 5%의 값과 가장 작은 5%의 값이 계산된 평균에서 제외됩니다. 예:
|
U95(Arg1) | 95% 신뢰 구간의 상위 끝점을 계산합니다. 주: 이 함수에서 사용하는 고정 t-값 1.959964는 큰 샘플 크기( n >= 40)에 맞춰 조정된 것입니다.샘플 크기가 이보다 작은 경우에는 다음 표현식을 대신 사용합니다.
예:
|
UAV(Arg1) | 인접한 상위 값을 계산합니다. 예:
|
UIF(Arg1) | 상위 내부 펜스를 계산합니다.Q3 + (1.5*IQR)에 있는 임계값입니다.예:
|
UniqueCount(Arg1) | 인수 컬럼에서 비어 있지 않은 고유한 값의 수를 계산합니다. 예:
|
UOF(Arg1) | 상위 외부 펜스를 계산합니다.Q3 + (3*IQR)에 있는 임계값입니다. 예:
|
ValueForMax(Arg1,
Arg2)
| column 1의 최대값에 대한 column 2의 값을 반환합니다. 컬럼 1 최대값이 둘 이상인 경우 결과는 첫 번째 최대 행의 값이 됩니다. 예:
|
ValueForMin(Arg1,
Arg2)
| column 1의 최소값에 대한 column 2의 값을 반환합니다. 컬럼 1 최소값이 둘 이상인 경우 결과는 첫 번째 최소 행의 값이 됩니다. 예:
|
Var(Arg1)
| 분산을 계산합니다. 예:
|
WeightedAverage(Arg1,
Arg2)
| 두 컬럼의 가중 평균을 계산합니다.Arg1은 가중 컬럼이고 Arg2는 값 컬럼입니다. 예:
|

팁:DISTINCT 키워드를 사용하면 고유한 값만 사용하여 결과를 반환할 수 있습니다.예를 들어 Avg(DISTINCT[Column])는 지정된 컬럼에 있는 모든 값의 평균이 아니라 고유한 값의 평균을 반환합니다.UniqueCount([Column])는 Count(DISTINCT[Column])와 같습니다.
함수를 참조하십시오.