Heat map
La façon la plus simple de comprendre une Heat Map est de penser à un tableau croisé ou à une feuille de calcul, dans lequel les valeurs numériques sont représentées par des cellules colorées au lieu des valeurs mêmes. Le dégradé de couleur par défaut représente la valeur la plus basse de la Heat Map en bleu foncé, la valeur la plus élevée en rouge brillant et les valeurs moyennes en gris léger, avec une transition (dégradé) appropriée entre ces points de repère.
Les Heat Maps sont particulièrement conçues pour la visualisation de nombreuses données multidimensionnelles et peuvent être utilisées pour identifier les clusters de lignes ayant des valeurs similaires car ces derniers sont affichés sous la forme de zones ayant des couleurs similaires.
Exemple
L'exemple ci-dessous illustre la façon dont les valeurs du tableau sont affichées en dégradés de couleur dans les cellules de la Heat Map.
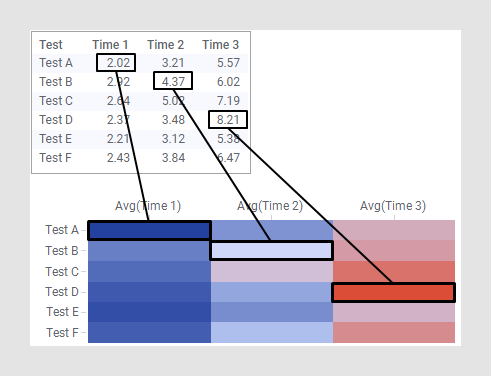
La façon de configurer une Heat Map dépend du format des données, comme illustré dans les exemples ci-dessous.
Données au format long/étroit
Dans cet exemple, les données sont au format long/étroit et chaque ligne de la table de données correspond à une cellule unique dans la Heat Map.
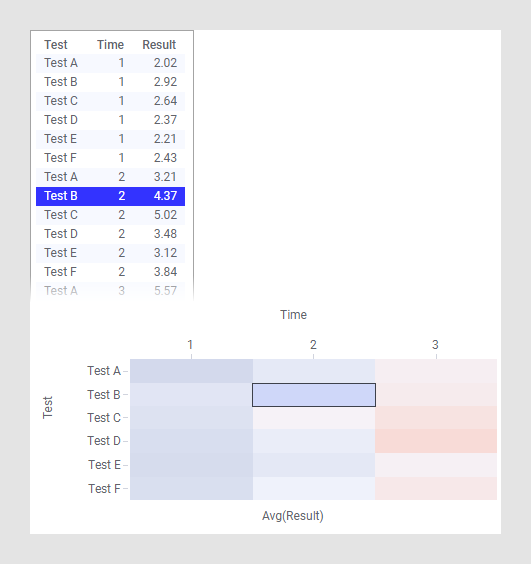
Les colonnes Test et Time sont sélectionnées sur l'axe des Y et l'axe des X, respectivement, et les valeurs de cellule sont définies sur la colonne Result. Comme dans les autres visualisations, la mise en évidence et le marquage dans la Heat Map sont appliqués à une ou plusieurs lignes dans la table de données sous-jacente. En d’autres mots, avec la configuration de cet exemple, le marquage d'une ligne dans la table entraînera le marquage d'une cellule dans la Heat Map.
Données au format court/large
Dans cet exemple, les données sont au format court/large, et chaque ligne de la table de données correspond à une ligne complète dans la Heat Map.
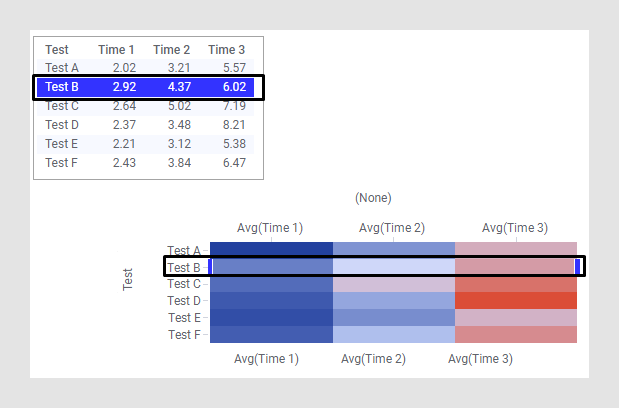
L'axe Y dans cette Heat Map est configuré avec la colonne Test, alors que l'axe X est défini sur (Aucun). Pour les valeurs de cellules individuelles dans la Heat Map, les colonnes Time 1, Time 2, et Time 3 sont sélectionnées. Les colonnes à cellule de valeurs sont toujours agrégées sauf si l'axe Y est défini sur (Numéro de ligne). Cela est dû au fait que de nombreuses tables de données peuvent contenir de nombreuses lignes portant le même nom et que les valeurs de ces lignes doivent être agrégées en une valeur unique pour être affichées dans la Heat Map. Le contenu des données est le même que dans l'exemple du format de données long/étroit, mais le format des données nécessite de configurer la Heat Map d'une certaine façon. Avec des données au format court/large, il s'agit d'une configuration courante pour une Heat Map.
Dendrogrammes
Il est souvent utile de combiner les Heat Maps avec le clustering hiérarchique, qui constitue une façon de trier les éléments selon une hiérarchie basée sur la distance ou sur le degré de similarité entre eux. Le résultat d'un calcul de clustering indique la distance ou la similarité entre les éléments regroupés en cluster selon la mesure de distance sélectionnée.
Vous pouvez regrouper à la fois les lignes et les colonnes en cluster dans une Heat Map. Le résultat d'un calcul de clustering hiérarchique s'affiche dans une Heat Map sous la forme d'un dendrogramme, qui est une hiérarchie à structure arborescente. Les dendrogrammes en ligne montrent la distance (ou la similarité) entre les lignes et indiquent à quel nœud appartient chaque ligne suite au calcul de clustering. Les dendrogrammes en colonne illustrent la distance ou (la similarité) entre les variables (les colonnes à cellules de valeur sélectionnées).
L'exemple montre une Heat Map avec un dendrogramme en ligne sur lequel les distances entre les lignes ont été calculées.

Suite au calcul de clustering, le classement des lignes de la Heat Map a été modifié pour correspondre à ce calcul de clustering. Les lignes Test A et Test E sont regroupées dans le même cluster. Les lignes Test F et Test B sont placées ensemble dans un second cluster. Ce second cluster est associé à la ligne Test C dans un troisième cluster. La ligne Test D n'est inclue dans aucun des ces clusters. Cela signifie que les lignes Test A et Test E sont plus proches l'une de l'autre qu'elles ne sont proches des lignes Test F, Test B, Test C, ou Test D. Cela indique également que la ligne Test D est la ligne la plus distante de toutes les autres lignes.