Varias tablas de datos en una visualización
En ocasiones, los datos que quiere analizar en Spotfire se encuentran en tablas de datos diferentes. Trabajar con visualizaciones que combinan datos de varias tablas de datos no es muy distinto a trabajar con datos de una sola tabla de datos. Puede elegir la visualización que mejor se adapte a sus datos, puede filtrar, marcar y profundizar en sus datos. Sin embargo, un par de conceptos son importantes al configurar y trabajar con una visualización que combina datos de diferentes tablas de datos.
La tabla de datos principal
En una visualización que combina datos de diferentes tablas, la tabla de datos principal desempeña un papel fundamental. Una visualización siempre tiene una única tabla de datos principal, que es el punto de anclaje de los datos para la visualización. Define qué es una fila en una visualización sin agregar y las columnas de la tabla de datos principal son las que pueden usarse para agrupar la visualización de diferentes maneras. Por consiguiente, las columnas de la tabla de datos principal controlan aquello que se convierte en un elemento (como un indicador de un gráfico de dispersión o una barra en un gráfico de barras) en una visualización agregada.
Cuando marca elementos en una visualización, los detalles se mostrarán únicamente para las columnas de la tabla de datos principal. La tabla de datos principal es también aquella a la que hacen referencia todas las expresiones de forma predeterminada, a menos que se especifique de forma explícita que una expresión debe hacer referencia a otra tabla de datos de la visualización mediante el nombre de columna cualificado, [Nombre de tabla de datos].[Nombre de columna]. (Por ejemplo: Sum([Sales Previous Year].[Sales]) donde "Sales Previous Year" es el nombre de la tabla de datos y "Sales" es el nombre de la columna.)
Para aprovechar al máximo sus datos, piense qué tabla de datos es la más adecuada para ser la tabla de datos principal antes de comenzar a configurar la visualización.
Puede seleccionar la tabla de datos principal en la sección Datos de las Propiedades de la visualización o en el selector de tablas de datos de la leyenda. En la imagen siguiente, el nombre de la tabla de datos principal es "Sales 2017":
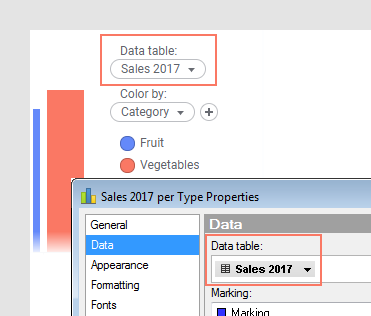
Tablas de datos adicionales
Es posible usar columnas de otras tablas de datos que no sean la principal en los ejes de agregación de la visualización, pero no en los ejes que agrupan la visualización.
Para agregar una columna de otra tabla de datos, puede usar la opción de arrastrar y colocar del menú flotante Datos del análisis o del panel Filtros, o bien seleccionar una columna desde el selector de columnas. Abra el selector de columnas y elija la tabla de datos que le interese; el selector de columnas cambiará para mostrar las columnas de la tabla de datos seleccionada. Solo si tiene varias tablas de datos en el análisis podrá ver el selector de tablas de datos y si hay coincidencias de columnas disponibles (véase a continuación). Las coincidencias de columnas solo se pueden editar con el cliente instalado, pero cuando existen, puede agregar otra tabla de datos a una visualización desde el cliente web.
Asociar columnas
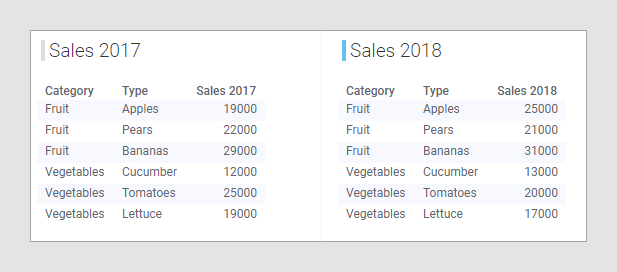
Otro concepto importante que debe conocer es el de coincidencia de columnas. Para que una visualización muestre datos de varias tablas de datos, al menos una columna de las que vaya a usar para agrupar la visualización de alguna forma debe coincidir con una columna correspondiente en las demás tablas de datos de la visualización. Una columna es coincidente si contiene el mismo tipo de datos. Si las columnas contienen valores del mismo tipo de datos y tiene nombres de columna idénticos, estas se asociarán automáticamente. Por ejemplo, en las dos tablas de datos siguientes ("Sales 2017" y "Sales 2018"), las columnas "Category" y "Type" coinciden en las dos tablas. Una regla básica al configurar una visualización es que todas las categorías que se vayan a usar en ella deben existir en todas las tablas de datos. De esta forma, será fácil asociar las columnas. Sin embargo, hay algunas excepciones a la regla. Para obtener más información al respecto, consulte la sección Faltan coincidencias de columnas en Asociaciones de columnas.
Si no se encuentran coincidencias automáticas, puede agregar coincidencias manualmente. Para obtener más información sobre cuándo y cómo hacer coincidir las columnas manualmente, consulte Asociaciones de columnas, Agregar coincidencias de columna manualmente y los temas siguientes.
Aunque generalmente no es necesario definir una relación entre tablas de datos además de una coincidencia de columna, en ocasiones, puede ser de gran utilidad. Con una relación entre dos tablas de datos, el marcado y filtrado de una puede propagarse a la otra. Para obtener más información sobre cómo especificar cómo debe funcionar el filtrado en tablas de datos relacionadas, consulte Filtrado en tablas de datos relacionadas.
Ejemplo básico
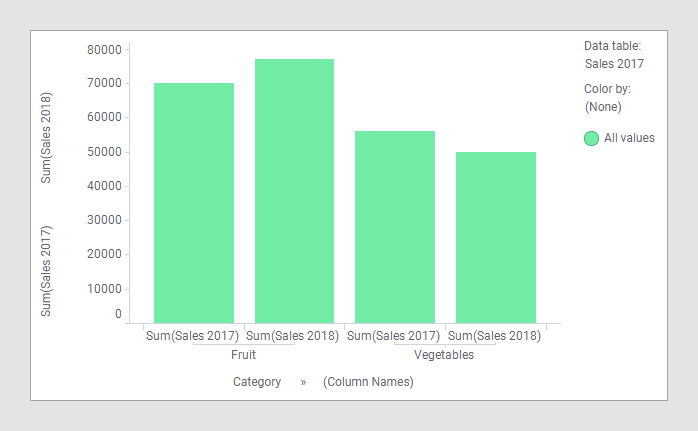
La comparación de los datos en las dos tablas de datos indicadas arriba en un gráfico de barras no requiere ningún ajuste especial. Solo debe cargar las dos tablas de datos en Spotfire, crear el gráfico de barras, seleccionar una de las columnas por categorías en el eje de categorías y, a continuación, seleccionar las dos columnas (es decir, "Sales 2017" y "Sales 2018") en el eje de valores.
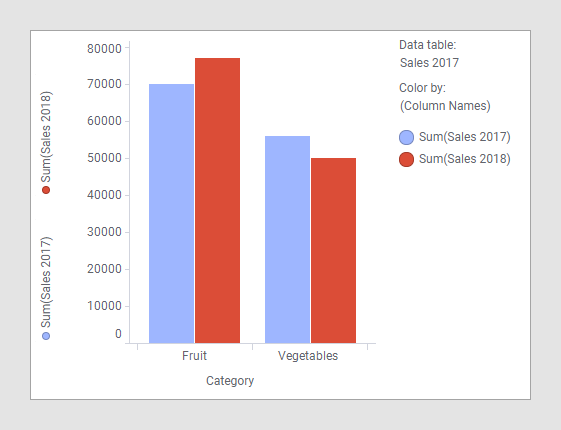
Dado que las columnas "Category" y "Type" en las dos tablas de datos tienen nombres idénticos y contienen valores del mismo tipo de datos, estas ya se asociaron automáticamente. Como muestran las imágenes, la tabla de datos principal es "Sales 2017" y, por lo tanto, la columna usada en el eje de categorías proviene de dicha tabla. En este ejemplo, cualquiera de las dos tablas de datos podría haberse usado como tabla de datos principal, ya que las columnas por categorías son las mismas en ambas. Como siempre, cuando se usan varias columnas en el eje de valores de un gráfico de barras, se debe usar (Nombres de columna) para agrupar la visualización. En la imagen anterior, la opción (Nombres de columnas) se usa para aplicar el color, pero usarla para aplicar el enrejado o, como en la imagen más abajo, para agregarla al eje de categorías son otras de las posibilidades.
Distintos niveles de detalle
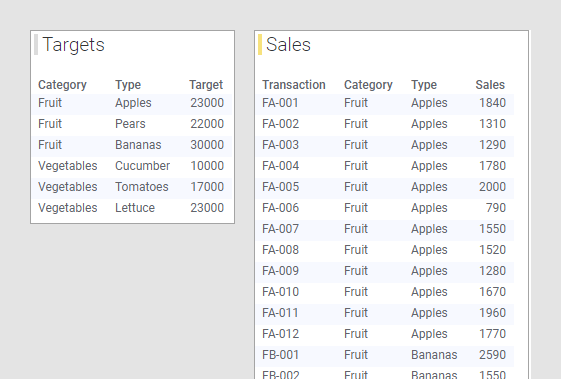
En el ejemplo anterior, las tablas de datos tenían más o menos las mismas columnas; "Category", "Type" y una columna con cifras de ventas. También es posible comparar los datos de tablas con datos de distintos niveles de detalle en una visualización. Por ejemplo, tal vez quiera comparar destinos de ventas de un año concreto con las ventas reales para el año vigente. Quizá dispone de una tabla de datos con destinos de ventas de frutas y verduras. Para cada tipo de fruta y verdura, una sola fila representa el destino, como se aprecia en la tabla de datos "Targets" a continuación. En otra tabla de datos, puede que tenga los datos de venta reales para el año vigente, como se puede ver en la tabla de datos "Sales" abajo. En esta tabla de datos, cada transacción de ventas está representada por una fila, lo que significa que para cada tipo de fruta y verdura, hay varias filas de cifras de ventas.
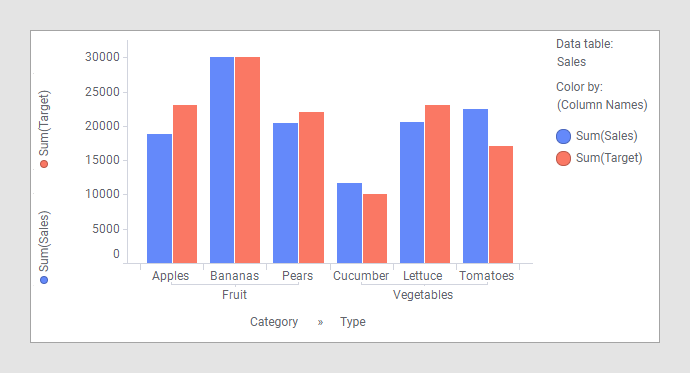
Al combinar datos de esas dos tablas en un gráfico de barras, puede ver las frutas y verduras que han alcanzado sus destinos este año:
Flujo de trabajo recomendado
Si no está seguro sobre cómo configurar una visualización que combina columnas de diferentes tablas de datos, quizá le resulte útil este flujo de trabajo recomendado.
1. Seleccionar la tabla de datos principal
Comience echando un vistazo a los datos de las diferentes tablas de datos y trate de responder a un par de preguntas. ¿Qué datos contienen? Según esos datos ¿qué desea visualizar? Una tabla de datos con categorías por las que le gustaría agrupar su visualización es una buena opción para convertirse en tabla de datos principal. Por ejemplo, puede que quiera agrupar por región, departamento, vendedor, tipo de producto o algo similar.
2. Configuración de la visualización solo con la tabla de datos principal
Agregue una visualización del tipo que desee utilizar y, a continuación, configure todo lo que pueda de dicha visualización únicamente con columnas de la tabla de datos principal. Seleccione cómo y con qué columnas agrupar la visualización y, si la tabla de datos principal también contiene columnas que quiera mostrar como agregadas, agréguelas a los ejes adecuados.
3. Agregar las mediciones de agregación
Cuando se ha configurado la visualización todo lo posible solo con la tabla de datos principal, puede comenzar a agregar columnas agregadas de las otras tablas de datos.