Correspondances de colonnes
Dans une visualisation, lorsque vous combinez des données issues de plusieurs tables de données, vous devez tenir compte de la façon dont les colonnes sont mises en correspondance dans les tables. Gardez à l'esprit que toutes les colonnes que vous voulez utiliser dans la visualisation doivent exister dans chacune des tables de données. Par exemple, il peut s’agir des colonnes qui définissent un marqueur dans un nuage de points, des colonnes que vous voulez paramétrer sur l'axe catégoriel d'un histogramme ou bien des colonnes selon lesquelles subdiviser ou colorer les données dans la visualisation. Des données bien structurées simplifient la configuration de la visualisation et la mise en correspondance des colonnes. Dans certains cas, il est possible que certaines colonnes de la table de données principale n'aient pas de correspondance dans toutes les tables. En outre, bien que les données soient configurées de la manière recommandée, des modifications manuelles peuvent parfois être nécessaires.
Correspondance automatique des colonnes
Lorsque vous ajoutez plusieurs tables de données à une analyse (dans un client Spotfire), Spotfire met automatiquement en correspondance les colonnes qui ont le même le nom et le même type de données. Par exemple, si vous chargez les tables de données présentées ci-dessous, Spotfire détectera une correspondance entre les colonnes intitulées « Product » :
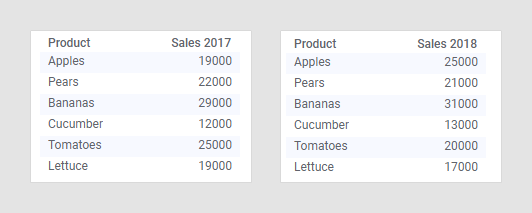
Lorsque la correspondance de colonne est disponible, vous pouvez utiliser les données des deux tables dans une seule visualisation, comme décrit dans la section Plusieurs tables de données dans une visualisation.
Correspondance manuelle des colonnes
Si les tables de données que vous souhaitez utiliser ne contiennent pas directement une correspondance de colonne exacte, vous pouvez ajouter et modifier des correspondances de colonne à l'aide du client installé. Cela peut être nécessaire si les colonnes que vous voulez faire correspondre ont des noms ou des types de données différents, ou si les valeurs des colonnes utilisent une casse différente.
Pour plus de détails, consultez la section Ajout manuel de correspondances de colonnes et les exemples qui suivent cette rubrique.
Affichage des correspondances de colonnes actuelles
Lorsque des correspondances ont été ajoutées, elles sont affichées dans l'onglet Correspondances de colonnes de la boîte de dialogue Propriétés de table de données (client installé uniquement). Cliquez sur une table de données pour en voir les correspondances actuelles :
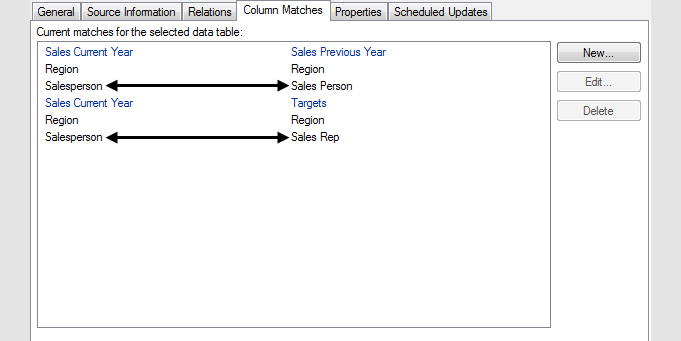
Les noms de table des données sont affichés en bleu et les noms de colonne en noir. La table de données sélectionnée est toujours affichée dans la partie gauche.
Vous pouvez également afficher les colonnes correspondant à une visualisation spécifique dans la section Données des propriétés de visualisation :
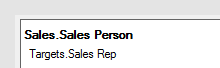
S'il manque des correspondances, cela est indiqué ici et vous pouvez en ajouter une au besoin. Si une colonne a plusieurs correspondances dans une autre table, sélectionnez la correspondance que vous voulez utiliser dans cette visualisation spécifique.
Correspondances de colonnes manquantes
Comme nous l'avons mentionné, il est essentiel que toutes les colonnes servant à regrouper les données dans la visualisation doivent figurer dans toutes les tables de données. Cependant, il arrive que la visualisation soit valide même si les colonnes utilisées n'ont aucune correspondance avec les colonnes des autres tables de données. Les exemples ci-dessous illustrent ce cas de figure.
La visualisation est valide
Si vous savez qu'une catégorie est unique, vous pouvez l'utiliser sur un axe de regroupement même si la colonne n'existe que dans la table de données principale. La table de données à gauche, ci-dessous, contient des informations sur les employés d'une entreprise : leur nom, leur sexe et l'emplacement de leur bureau. La table de données de droite contient les ventes totales réalisées par chaque personne.
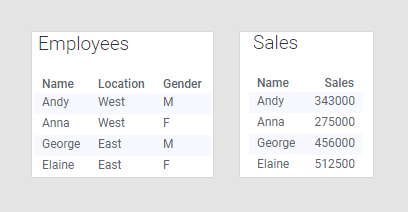
La colonne « Name » est la seule qui existe dans les deux tables de données, ce sera dont la seule qui pourra être mise en correspondance. La table de données « Employees » contient uniquement des catégories alors que la table de données « Sales » contient les chiffres de ventes que voudrez probablement comparer. En fusionnant ces deux tables de données, vous pouvez analyser les données en vous basant sur l'emplacement ou le sexe ou tout simplement comparer les chiffres de vente de plusieurs employés. Comme chaque employé de cet exemple s’identifie à un seul genre et travaille à un seul emplacement, vous pouvez effectuer un regroupement de toutes les colonnes dans cette table de données. Pour cela, vous devez sélectionner « Employees » comme table de données principale, comme l'illustre l'histogramme ci-dessous :
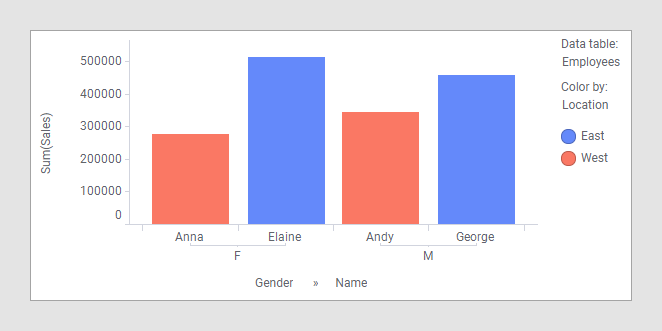
Les colonnes « Gender » et « Name » définissent l'axe Catégorie et la colonne « Location » définit la couleur des barres.
Si vous voulez effectuer un regroupement à partir de colonnes sans correspondance, assurez-vous que les catégories sont uniques. Dans le cas contraire, les données affichées dans la visualisation seront incorrectes, comme le démontre l'exemple suivant.
La visualisation n'est PAS valide :
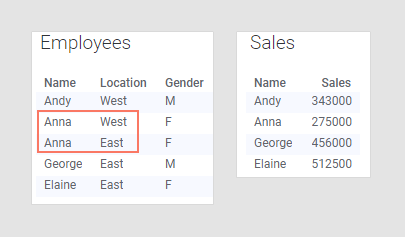
Les tables de données ci-dessous sont similaires à celles de l'exemple précédent à l'exception de la table « Employees » qui a été mise à jour pour signaler qu'Anna partage son temps de travail entre deux bureaux. Il est inutile de mettre à jour la table de données « Sales » car les ventes réalisées par Anna n'ont pas changé et n'ont aucun lien avec le bureau où elle se trouve.
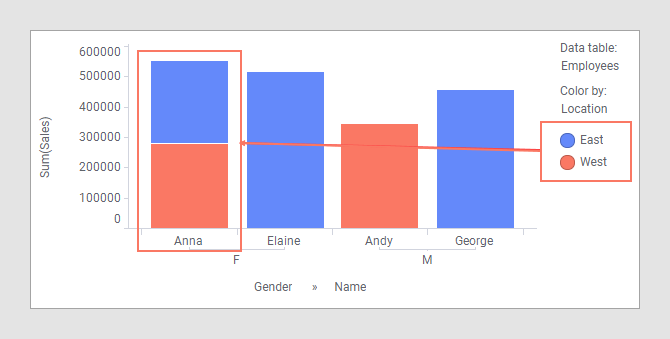
Cependant, ce changement dans la table de données principale a un impact sur la visualisation. Étant donné que la couleur des barres est définie par la colonne « Location » et qu'Anna figure dans les deux catégories, « East » et « West », elle apparaît une fois pour le bureau East et une fois pour le bureau West. Telle qu'elle est configurée, cette visualisation donne l'impression que le montant des ventes réalisées par Anna a été doublé, ce qui est faux.
Puisqu'Anna travaille dans les deux bureaux, la colonne « Location » ne peut plus être utilisée sur un axe de regroupement dans la visualisation. Pour que la visualisation soit de nouveau valide, il suffit de supprimer « Location » de l'axe de coloration :
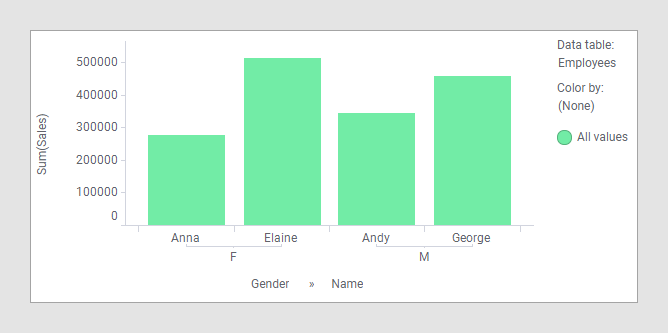
Désormais, chaque personne n’apparaît qu’une seule fois dans la visualisation, et vous pouvez utiliser la colonne « Gender » pour regrouper les données.
Si vous êtes certain d'avoir une visualisation valide, vous pouvez désactiver les avertissements concernant les correspondances de colonnes manquantes, comme décrit dans la section Masquage des avertissements concernant d'éventuelles non-concordances.