Conexiones a orígenes de datos de cubo (OLAP)
Spotfire admite el acceso a datos de orígenes de datos de cubos OLAP (procesamiento analítico en línea). Los conectores de datos para Microsoft SQL Server Analysis Services, SAP BW y Oracle Essbase están diseñados para trabajar con datos de cubo en sus respectivos sistemas.
Qué es un cubo
Un cubo de procesamiento analítico en línea (OLAP, por sus siglas en inglés) es una representación de datos de varias dimensiones.
El cubo de OLAP está formado por un conjunto de medidas (o hechos) y varias dimensiones.
Las dimensiones organizan los datos de un usuario en relación con un área de interés, como los clientes, las tiendas o la geografía. Las dimensiones suelen ser de naturaleza jerárquica. Las medidas (hechos) se colocan en las intersecciones entre las dimensiones. Por lo tanto, el propio cubo agrega las medidas o los hechos (ya sea con anterioridad o mediante cálculo dinámico).
Esto los diferencia de las bases de datos relacionales, donde las medidas o los hechos se almacenan en la tabla de base de datos y los métodos de agregación se aplican cuando se consulta la tabla de base de datos.
Ejemplo de cubo
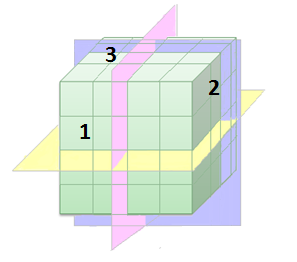
En la imagen esquemática superior, puede decirse que los lados del cubo representan dimensiones diferentes y que la celda contiene la medida asociada.
Para simplificar, si el lado 1 representa el tipo de producto, el lado 2 es una unidad de tiempo y el lado 3 es una región, entonces el cubo puede consultarse de varias formas: el plano amarillo puede indicar "Mostrar ventas por producto para diferentes años"; el rosa, "Mostrar ventas por producto en distintas regiones"; y el azul, "Mostrar ventas por región para diferentes años".
En Spotfire, un cubo de OLAP se representa como una tabla. Si no ha utilizado Spotfire antes, se recomienda usar la visualización de tabla cruzada para empezar (también denominada hoja de cálculo).
Qué son las medidas
Generalmente, las medidas, las métricas o los hechos que son de interés en el análisis de datos se conocen como medidas. Las medidas suelen ser numéricas. Algunos ejemplos de medidas son las ventas, las cantidades, las cuentas, etc.
El valor de una medida se calcula para un punto o una celda concretos mediante la agregación de los datos que corresponden a la intersección de dimensión respectiva de la celda.
En Spotfire, cada medida se representa como una columna. Normalmente, dicha columna se coloca en el eje de valores de una visualización. Debido a que el cubo de OLAP calcula las medidas, el método de agregación de estas no se puede cambiar en Spotfire.
En SAP BW, las medidas se denominan "Cifras clave".
Qué es una dimensión
Las dimensiones organizan los datos en relación con un área de interés. Las dimensiones pueden ser los clientes, las tiendas o la geografía, y suelen ser jerárquicas.
En Spotfire, las dimensiones no se pueden colocar en una visualización. Son un modo de organizar datos relacionados y se pueden ver en el menú flotante Datos del análisis y cuando selecciona datos para una conexión a una base de datos relacional como un método para encontrar datos relevantes. En su lugar, las jerarquías son las que se utilizan en los ejes de las visualizaciones de Spotfire.
SAP BW distingue entre "Cifras clave" y "Características". Las cifras clave se convierten en medidas en Spotfire, y todas las características se encuentran en la dimensión "Características".
En Oracle Essbase, todas las dimensiones son de naturaleza jerárquica. En Spotfire, las dimensiones de Essbase se muestran como jerarquías.
Qué es una jerarquía
Una jerarquía define un conjunto de relaciones principal-secundario. Normalmente, un miembro principal pertenece a un concepto más amplio que sus elementos secundarios, por lo que constituye un "resumen" de estos últimos. Además, los miembros principales se pueden agregar como elementos secundarios de otros elementos principales.
Una jerarquía también se puede visualizar como un conjunto de asignaciones de un conjunto de conceptos de bajo nivel a un conjunto de conceptos más generales y de nivel más alto. Cada concepto tiene un nombre: el nombre del nivel. Los niveles se ordenan de modo que los niveles "más generales" preceden a los niveles "menos generales".
Cada concepto o nivel consta de un conjunto de valores. Los valores del nivel se denominan miembros. Cada miembro tiene un nombre y una clave, que debe ser exclusiva.
Por ejemplo, imagine una jerarquía "Geografía" que contiene los conceptos "País" y "Ciudad", donde "País" es más general que "Ciudad". Es decir, la jerarquía "Geografía" contiene dos niveles, "País" y "Ciudad", donde el nivel "País" precede al nivel "Ciudad". Hay dos miembros, "EE. UU." y "Alemania", que pertenecen al nivel "País", y cuatro miembros, "Boston" (cuyo elemento principal es "EE. UU."), "Hamburgo" (cuyo elemento principal es "Alemania"), "Berlín" (cuyo elemento principal es "Alemania") y "Berlin" (cuyo elemento principal es "EE. UU."), que pertenecen al nivel "Ciudad".
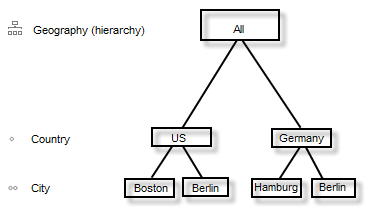
Las jerarquías son las categorías a las que se suele hacer referencia en Spotfire. Es decir, las jerarquías se suelen colocar en el eje de categorías de una visualización. Una jerarquía con un solo nivel se representa como una columna en Spotfire. Una jerarquía con varios niveles se representa como una jerarquía en Spotfire.
Consultas de cubo
Cuando se usan datos de cubo en bases de datos, Spotfire crea consultas MDX (MultiDimensional eXpression) que se envían al motor de consultas del cubo para obtener resultados.
En una consulta MDX, todas las jerarquías del cubo importan, aunque no se especifiquen en la consulta. Si no se especifica ninguna jerarquía en una consulta, se usará el miembro predeterminado de dicha jerarquía. Esto se puede considerar como una fragmentación implícita del cubo en el miembro predeterminado. El miembro predeterminado suele ser un miembro que indica "todos los elementos posibles", pero no siempre es así.
Por ejemplo, si hay un cubo que contiene una medida ("Ventas") y dos jerarquías ("Tiempo" y "Países"), Ventas se mostrará en un eje de la visualización y Tiempo en el otro. El resultado que se obtendrá serán las ventas a lo largo del tiempo de todos los países. Si usa una dimensión o una jerarquía de moneda, el miembro probablemente será una moneda específica, no "todas las monedas". Esto significa que obtendrá el valor (Ventas, por ejemplo) de la moneda que se haya establecido como predeterminada. Si no es lo que desea, debe pedir al administrador del cubo que cambie el miembro predeterminado (esto solo es posible en Microsoft SQL Server Analysis Services), o proporcionar un filtro de Spotfire para la jerarquía de moneda, en el que podrá seleccionar la moneda que se mostrará.
Si no ve datos en las visualizaciones, podría deberse a que no se han agregado datos para la combinación del miembro o los miembros predeterminados y las jerarquías indicadas en el cubo. Una posible solución para esta situación sería fragmentar el cubo de forma explícita mediante la aplicación de un filtro apropiado de Spotfire en la jerarquía o las jerarquías donde se usan los miembros predeterminados.
En teoría, es posible dividir una consulta lo suficiente como para que devuelva los valores actuales del almacenamiento de datos subyacente, pero el cubo seguiría considerando la consulta como agregada.
Tablas de datos en la base de datos de cubos en Spotfire
Debido a que los datos de cubo se agregan desde un principio, Spotfire no calcula las agregaciones cuando se usan datos de cubo en bases de datos. Todas las agregaciones (si las hay) que se deben calcular se envían al motor de consultas del cubo. Por otro lado, puede utilizar Spotfire para mostrar las combinaciones de medidas y jerarquías relacionadas que el administrador del cubo ha configurado.
Al aprovechar la estructura natural del cubo, puede asegurarse de que ve los datos relevantes. Por otro lado, la dimensionalidad libre de Spotfire le permitirá realizar combinaciones de medidas y dimensiones del cubo que no siempre tienen sentido, o que producen mensajes como "La expresión no es válida" en las visualizaciones.
Cuando se cambia lo que se muestra en los ejes de una visualización que se basa en datos de cubos en bases de datos, o bien cuando se realiza una selección en filtros jerárquicos o de casilla de verificación, se envía una solicitud al cubo para que suministre los datos seleccionados. Esto significa que si se realizan demasiados cambios en Spotfire, se pueden enviar muchas solicitudes a la base de datos, en lugar de la solicitud de la selección final.
Spotfire aplica un retraso de aproximadamente un segundo para determinar si se realizan otras selecciones en un filtro antes de enviar la solicitud a la base de datos. Esto quiere decir que debe hacer cambios coherentes en el filtro con un ritmo continuo y debe evitar detenerse por demasiado tiempo al activar varias casillas de verificación. Si se detiene por más de un segundo, la selección de filtro actual se enviará al cubo, el cual comenzará a suministrar los datos que se han solicitado. Si se hacen cambios adicionales al filtro, se enviarán más solicitudes a la base de datos y aumentará la carga de trabajo que esta debe procesar, ya que es posible que la primera solicitud aún se esté ejecutando.