큐브 데이터 소스에 대한 연결(OLAP)
Spotfire는 OLAP(Online Analytical Processing) 큐브 데이터 소스의 데이터 액세스를 지원합니다. Microsoft SQL Server Analysis Services, SAP BW 및 Oracle Essbase용 데이터 커넥터는 모두 해당 시스템의 큐브 데이터 작업에 맞게 조정되었습니다.
큐브란?
OLAP(Online Analytical Processing) 큐브란 데이터에 대한 다차원 표현입니다.
OLAP 큐브는 일련의 측정(또는 팩트) 및 여러 차원으로 구성됩니다.
차원은 고객, 상점 또는 지리 등과 같이 원하는 영역과 관련된 사용자 데이터로 구성됩니다. 일반적으로 차원은 사실상 계층 구조로 표시됩니다. 측정(팩트)은 차원 간 교집합에 있습니다. 따라서 측정이나 팩트는 큐브 자체에서 집계됩니다(사전에 집계되거나 동적으로 계산됨).
이는 측정이나 팩트가 데이터베이스 테이블에 저장되고 데이터베이스 테이블이 질의될 때 집계 방법을 적용하는 관계형 데이터베이스와의 차이점입니다.
큐브 예
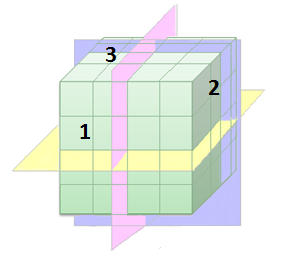
위의 개요 이미지에서 큐브의 면은 서로 다른 차원을 나타낸다고 간주할 수 있으며, 셀에는 연결된 측정이 포함됩니다.
간단히 면 1이 제품 유형, 면 2가 시간 단위, 면 3이 지역을 나타내는 경우 큐브를 여러 가지 다른 방법으로 질의할 수 있습니다. 노란색 평면은 "각 연도의 제품별 매출 표시"를 의미하고, 분홍색 평면은 "각 지역의 제품별 매출 표시"를 나타내고, 파란색 평면은 "각 연도의 지역별 매출 표시"를 나타낼 수 있습니다.
Spotfire에서 OLAP 큐브는 테이블로 표시됩니다. Spotfire를 처음 사용하는 경우 초보자에게 적합한 시각화는 크로스 테이블 시각화(스프레드시트라고도 함)입니다.
측정이란?
측정이란 데이터 분석에서 관심 있는 측정값, 지표 또는 팩트에 대한 일반적인 이름입니다. 사실상 측정은 대부분 숫자 값입니다. 측정의 예로는 판매량, 수량, 계정 등이 있습니다.
측정 값은 셀에 대해 해당 차원 교집합에 해당하는 데이터를 집계하여 셀이나 지정된 포인트에 대해 계산됩니다.
Spotfire에서 각 측정은 컬럼으로 표시되며, 이러한 컬럼은 일반적으로 시각화의 값 축에 배치되는 항목입니다. 측정은 OLAP 큐브에서 계산되므로 Spotfire의 측정에 대해 집계 방법을 변경할 수 없습니다.
SAP BW에서 측정은 "주요 수치"라고 합니다.
차원이란?
차원은 원하는 영역과 관련된 데이터로 구성됩니다. 차원은 고객, 상점, 지리 등과 같은 항목이 될 수 있으며, 일반적으로 사실상 계층 구조로 표시됩니다.
Spotfire에서 차원은 시각화에 배치될 수 없습니다. 차원은 관련 데이터를 정리하는 방법이며, 분석 내 데이터 플라이아웃과 관계형 데이터베이스에 연결할 데이터를 선택할 때 관련 데이터를 찾는 수단이라고 할 수 있습니다. 대신 차원은 Spotfire 시각화의 축에 사용되는 계층이라고 보면 됩니다.
SAP BW에서는 '주요 수치'와 '특성'이 구분됩니다. 주요 수치는 Spotfire에서 측정이 되며 모든 특성은 '특성' 차원에 있습니다.
Oracle Essbase에서는 모든 차원이 사실상 계층 구조로 표시됩니다. 따라서 Spotfire에서 Essbase 차원은 모두 계층으로 표시됩니다.
계층이란?
계층은 일련의 상위-하위 관계를 정의합니다. 일반적으로 상위 회원은 하위 회원보다 더 일반적인 개념에 속하며, 상위 회원은 해당 하위 회원을 "요약"합니다. 상위 회원은 다른 상위 회원의 하위 회원으로 집계될 수도 있습니다.
계층은 하위 수준 개념 집합부터 더 일반적인 상위 수준 개념까지의 일련의 매핑으로 표시될 수 도 있습니다. 각 개념에는 이름 - 수준 이름이 지정됩니다. 수준은 "더 일반적"인 수준이 "덜 일반적"인 수준 앞에 오도록 정렬됩니다.
각 개념이나 수준은 일련의 값으로 구성됩니다. 수준 값을 회원이라고 하며, 각 회원에게는 이름과 키가 지정됩니다. 여기서 키는 회원이 고유하도록 해줍니다.
예를 들어 '국가' 및 '도시' 개념을 가진 '지리' 계층이 있다고 가정해 봅시다. 여기서 '국가'는 '도시'보다 더 일반적입니다. 즉 '지리' 계층에 두 개의 수준 즉, '국가' 및' 도시'가 포함되며, 여기서 '국가' 수준은 '도시' 수준 앞에 옵니다. '국가' 수준에 속하는 2개의 회원 즉, '미국'과 '독일'이 있고 '도시' 수준에 속하는 4개의 회원 즉, '보스턴'(상위 항목이 '미국'임), '함부르크'('상위 항목이 '독일'임), '베를린'(상위 항목이 '독일'임) 및 '베를린'(상위 항목이 '미국'임)이 있습니다.
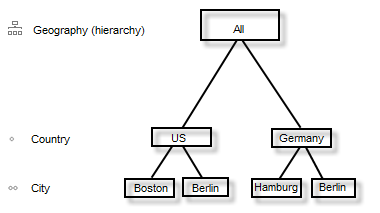
일반적으로 계층은 Spotfire에서 범주라고 합니다. 즉 계층은 일반적으로 시각화의 범주 축에 배치되는 항목입니다. 1개의 수준만 있는 계층은 Spotfire에서 컬럼으로 표시됩니다. 반면 둘 이상의 수준이 있는 계층은 Spotfire에서 계층으로 표시됩니다.
큐브 질의
데이터베이스 내 큐브 데이터 작업 시 Spotfire는 결과를 반환하기 위해 큐브 질의 엔진으로 전송되는 MDX(MultiDimensional eXpression) 질의를 만듭니다.
MDX 질의에서 큐브의 모든 계층은 중요합니다(질의에서 지정되지 않은 계층도 마찬가지임). 질의에서 계층이 지정되지 않은 경우 해당 계층의 기본 회원이 사용되며, 이는 기본 회원에 대한 큐브의 암시적 슬라이싱으로 볼 수 있습니다. 기본 회원은 일반적으로 "가능한 모든 항목"을 나타내는 회원이지만, 항상 그런 것은 아닙니다.
예를 들어 하나의 측정('판매량') 및 두 개의 계층('시간' 및 '국가')을 포함하는 큐브가 있는 경우 시각화의 하나의 축에서 판매량을 사용하고 또 다른 축에서 시간을 사용합니다. 반환되는 결과는 모든 국가에 대해 시간별 판매량입니다. 통화 차원이나 계층을 사용하는 경우 기본 회원이 "모든 통화"가 아니라 특정 통화가 되는 경우는 많습니다. 즉 기본 통화인 통화에 대해 값(예: 판매량)을 가져오게 됩니다. 가져온 결과가 원하는 결과가 아닌 경우 큐브의 기본 회원을 변경하도록 큐브 관리자에게 요청하거나(Microsoft SQL Server Analysis Services에서만 가능) 표시할 통화를 선택할 수 있는, 통화 계층의 Spotfire 필터를 제공해야 합니다.
시각화에 아무 데이터도 표시되지 않으면 큐브의 기본 회원 및 지정된 계층의 조합에 대해 데이터가 집계되지 않은 것일 수 있습니다. 이러한 상황에 대한 잠재적인 해결 방법은 기본 회원이 사용되는 계층에 대해 적합한 Spotfire 필터를 적용하여 큐브를 명시적으로 슬라이싱 또는 다이싱하는 것입니다.
이론적으론 질의를 분할하여 기본 데이터 웨어하우스의 실제 값을 반환할 수 있지만 큐브에서는 계속 질의를 집계된 것으로 간주합니다.
Spotfire의 큐브에서 데이터베이스 내 데이터 테이블
큐브 데이터는 처음부터 이미 집계되었으므로 db 내 큐브 데이터 작업 시 Spotfire에서 집계가 수행되지 않습니다. 수행해야 하는 모든 집계(있는 경우)는 큐브 질의 엔진으로 이동됩니다. 대신 큐브 관리자가 구성한 측정과 계층의 관련 조합을 표시하는 방법으로 Spotfire를 사용할 수 있습니다.
큐브의 일반 구조를 활용하여 관련 데이터가 표시되어 있는지 확인할 수 있습니다. Spotfire의 자유 차원성을 활용하여 큐브에서 부분적으로 관련 없는 측정값과 차원을 조합할 수 있습니다. 그렇지 않은 경우 "표현식이 잘못되었습니다."라는 메시지가 시각화에 표시됩니다.
db 내 큐브 데이터를 기반으로 하는 시각화의 축에 표시된 항목을 변경하거나 계층 필터 또는 확인란 필터를 선택할 때마다 요청이 큐브에 전송되어 선택한 데이터가 제공됩니다. 즉, Spotfire에서 여러 번 변경한 경우 최종 선택 사항에 대한 요청만 전송되는 것이 아니라 여러 요청이 데이터베이스에 전송될 수 있습니다.
Spotfire에서는 요청을 데이터베이스에 전송하기 전에 약 1초의 지연을 사용하여 필터에서 추가적으로 수행된 선택 사항이 있는지 확인합니다. 따라서 필터링에서 일정한 간격으로 일관되게 변경해야 하며 여러 체크박스를 선택할 때 동작을 너무 오래 멈추지 말아야 합니다. 동작을 약 2초 이상 멈추면 현재 필터 선택 사항이 큐브에 전송되어 요청한 데이터가 제공되기 시작합니다. 필터에 대한 추가 변경이 수행되면 데이터베이스에 추가 요청이 전송되는데, 첫 번째 요청이 아직 실행되고 있을 수 있으므로 데이터베이스의 워크로드가 증가합니다.