곡선 맞춤 모델
곡선 맞춤에 사용할 수 있는 여러 가지 모델이 있습니다. 여기에서는 다양한 모델에 대해 간략하게 설명합니다.
라인 및 곡선를 참조하십시오.
직선
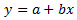
여기서 a는 절편이고 b는 기울기입니다.
로그
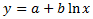
여기서 a와 b는 상수이고 ln은 자연 로그 함수입니다. 이 모델에서는 모든 데이터 포인트에 대해 x>0이 필요합니다. Spotfire에서는 이 계산에 대해 비선형 회귀 방법을 사용합니다. 따라서 변환된 값에 대해서만 선형 회귀를 사용할 때와 비교하여 계산의 정확도가 향상됩니다.
지수
여기서 a와 b는 상수이고 e는 자연 로그의 밑입니다.
예를 들어 지수 곡선은 박테리아의 기하급수적 성장에 대한 생물학적 응용에 일반적으로 사용됩니다. Spotfire에서는 이 계산에 대해 비선형 회귀 방법을 사용합니다. 따라서 변환된 값에 대해서만 선형 회귀를 사용할 때와 비교하여 계산의 정확도가 향상됩니다.
지수
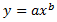
여기서 a와 b는 상수입니다. 이 모델에서는 모든 데이터 포인트에 대해 x가 0보다 크고, 모든 y가 0보다 크거나 작아야 합니다. Spotfire에서는 이 계산에 대해 비선형 회귀 방법을 사용합니다. 따라서 변환된 값에 대해서만 선형 회귀를 사용할 때와 비교하여 계산의 정확도가 향상됩니다.
로지스틱 회귀
기호 논리 회구 맞춤은 용량 반응("IC50") 모델이며, S형 용량 반응이라고도 합니다. 4 매개변수 기호 논리 모델이 가장 중요한 모델입니다.
용량 반응 곡선은 약물 치료에 대한 반응과 약물 복용량 또는 농도 사이의 관계를 설명합니다. 이 유형의 곡선은 X축에 로그(약물 농도)가 있는 반대수인 경우도 있습니다. Y축에는 효소 활동 측정치, 세포 내 제2 전령 누적, 심박동수 또는 근육 수축 측정치가 표시됩니다.
Log10 변환 X값
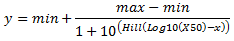
LoggedX50 값은 Log10(X50)으로 해석됩니다. 예를 들어 IC50에서 H30+ 농도의 pH가 3인 경우, LoggedX50 = -3입니다.
비대수 X값
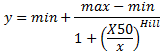
x>0이어야 하며 최소 4개의 레코드를 사용하여 곡선을 계산해야 합니다.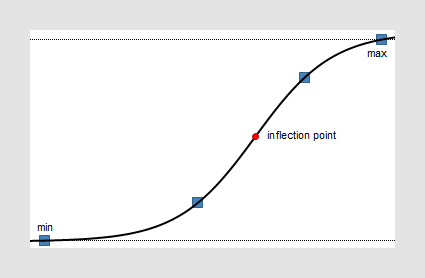
다항식
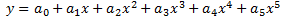
여기서 a0, a1, a2, 등은 상수입니다. 기본 차수는 2차 다항식이지만 곡선 설정에서 차수를 변경할 수 있습니다. 이 모델의 경우, 2차 다항식 모델에 대한 곡선을 계산하려면 마커를 3개 이상 사용하고, 3차 다항식 모델에 대한 곡선을 계산하려면 마커를 4개 이상 사용하고, ...n차 다항식 모델에 대한 곡선을 계산하려면 n-1개 이상의 마커를 사용해야 합니다.
고유한 x 값의 수가 적은 경우, 다항식 곡선을 무수한 방법으로 계산할 수 있습니다. 즉, 곡선이 예상한 모양과 다를 수 있습니다. 이 경우, 이 모델을 데이터에 적용하면 안 됩니다.
일부 모델의 경우, LAPACK 소프트웨어 패키지를 사용하여 부분적으로 확인되었습니다. 자세한 내용은 기본 설정을 참조하십시오.
가우스
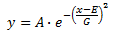
여기서 A는 곡선의 진폭(높이)이고, E는 곡선의 중심 위치이고, G는 너비입니다.
Spotfire에서는 곡선 매개변수 필드를 비워두면 응용 프로그램이 사용 가능한 데이터에서 매개변수 A, E 및 G의 값을 자동으로 계산할 수 있습니다. 매개변수 중 하나 이상을 직접 지정할 수도 있습니다.
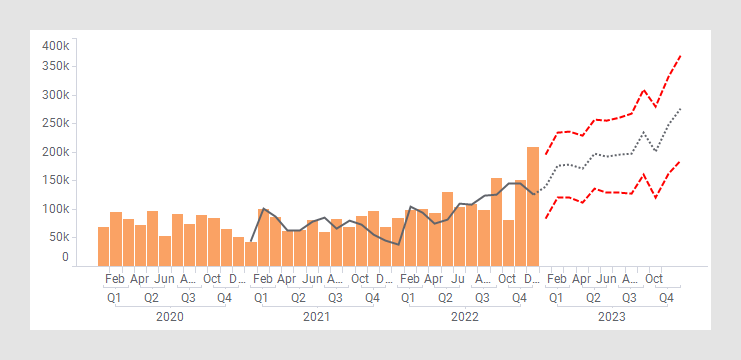
Holt-Winters 예측
Holt-Winters 예측에서는 Spotfire® Enterprise Runtime for R(TERR™이라고도 함)을 사용하여 시계열의 Holt-Winters 필터링 또는 시계열에 강제 적용할 수 있는 필터를 계산합니다. 이 필터는 시계열의 수준, 트렌드 및 계절 구성 요소에 대해 지수 가중치를 적용한 이동 평균 필터입니다. 평활화 매개변수는 한 단계 앞 제곱 예측 오차의 합계를 최소화하기 위해 선택합니다.
Holt-Winters 예측은 세 가지 곡선 즉, 원하는 측정의 일반 변형을 보여주는 보관된 곡선, 미래 트렌드를 예측하는 예측 곡선, 예측이 알려진 값으로부터 멀어질수록 불안이 얼마나 증가하는지를 보여주는 신뢰 구간 등으로 출력됩니다.
- 수준(알파) – 시계열의 수준 구성 요소를 평활화하는 방법을 지정합니다.
수준(알파) 매개변수는 0보다 크고 1보다 크지 않아야 합니다.
값이 작은 경우, X 방향에서 오래된 값일수록 더 높은 가중치가 적용됩니다.
값이 1.0에 가까운 경우, 최신 값에 더 높은 가중치가 적용됩니다.
- 트렌드(베타) – 시계열의 트렌드 구성 요소를 평활화하는 방법을 지정합니다.
트렌드(베타) 매개변수는 0-1 간격 이내에 있어야 합니다.
값이 작은 경우, X 방향에서 오래된 값일수록 더 높은 가중치가 적용됩니다.
값이 1.0에 가까운 경우, 최신 값에 더 높은 가중치가 적용됩니다.
- 계절(감마) – 시계열의 계절 구성 요소를 평활화하는 방법을 지정합니다.
계절(감마) 매개변수는 0-1 간격 이내에 있어야 합니다.
값이 작은 경우, X 방향에서 오래된 값일수록 더 높은 가중치가 적용됩니다.
값이 1.0에 가까운 경우, 최신 값에 더 높은 가중치가 적용됩니다.
드롭다운 목록을 사용하여 계절 구성 요소가 다른 구성 요소와 상호 작용하는 방법을 지정합니다.
덧셈(기본값)은 X가 수준 + 트렌드 + 계절로 모델링됨을 나타냅니다.
곱셈은 (수준 + 트렌드) * 계절로 모델링됨을 나타냅니다.
- 빈도 – 계절(감마) 구성 요소가 모델에 포함되어 있는 경우에만 해당됩니다.
시작 값을 계산하는 데 사용할 계절 기간 수 즉, 샘플링 기간당 관찰 수를 지정합니다. 예를 들어 월별 데이터의 빈도는 12입니다. 계절 구성 요소를 충족하려면 빈도가 1보다 커야 합니다.
- 향후 시점 – 시계열 값을 예측할 미래 시점(노드) 수를 지정합니다.
시각화에 월이 표시되는 경우, 향후 시점은 예측할 이후 개월 수와 같습니다. 시각화에 연도가 표시되는 경우, 향후 시점은 예측할 이후 연수를 나타냅니다.
- 신뢰 수준 – 신뢰 수준을 지정합니다. 이 값은 0보다 크고 1보다 크지 않은 수입니다.
- 비어 있는 값 대체 허용 – 인접한 값을 보간하여 비어 있는 값을 대체할 수 있습니다. 한 행에서 두 개의 누락된 데이터 포인트가 있는 경우, 해당 포인트를 보간할 수 없습니다.
고정 숫자를 사용하거나 속성에서 설정 기능을 사용하여 선택한 속성 값으로 빈도나 향후 시점을 지정할 수 있습니다. 그러면 텍스트 영역에 속성 제어를 추가하여 속성 값을 변경할 수 있습니다. 속성 및 속성 컨트롤에 대한 자세한 내용은 분석에서 문서, 데이터 테이블 또는 컬럼 속성 사용을 참조하십시오.
사용되는 매개변수를 레이블 또는 툴 팁에 표시할 수 있습니다.