データ関数を登録する
R またはその他の言語で記述された計算を分析に追加することで、データ関数を使用して Spotfire の機能を拡張することができます。データ関数は、Spotfire® Enterprise Runtime for R (別名 TERR™) エンジン、オープンソース R エンジン、または Python インタープリターなどの統計エンジンを使用して実行されます。データ関数を登録してライブラリーに保存すると、いずれの分析でも使用できるようになります。またスクリプトの作成者以外のユーザーによっても使用できます。
このタスクについて
始める前に
手順
タスクの結果
[データ関数の登録] ダイアログ

[Run] をクリックすると、入出力パラメータの設定を指定して現在のデータ関数を実行することができます。これは主に、ライブラリーに保存する前にデータ関数をテストするためのショートカットとして使用することを意図しており、テスト中に追加された埋め込みインスタンスは、分析に不要なインスタンスが保存されないように、完了時に分析から削除する必要があります。
その代わりに、保存したデータ関数を [f(x) - 分析ツール] または [ファイルとデータ] から実行するか、分析を保存する前に [データ関数のプロパティ] から [挿入] を使用して (インストール済みクライアントのみ) 、データ関数を今後のライブラリーの更新と同期できるようにします。
[キャッシングを許可する] は、同じ入力値サブセットが以前に計算されたことがある場合に、計算が再利用されるように指定します。一部の入力データが現在の分析以外の場所から取得されたものであり、入力データが変更されるたびに (以前に計算済みのものへの変更も含む) 新しい計算が実行されるようにする場合は、このチェック ボックスをオフにします。フィルターされた値、マークされた値、またはプロパティ値に入力が依存している場合は、入力データは変わる可能性があります。
たとえば、データ関数に乱数ジェネレータが含まれている場合は、以前に生成された乱数をキャッシュに保存しない方がおそらく望ましいでしょう。代わりに、データ関数の更新ごとに新しい乱数を計算します。チェック ボックスをオフにするもう 1 つの例は、データ関数に現在の日付または日時が含まれる場合です。
[スクリプト] タブでは、指定したスクリプト タイプの言語で、スクリプトの入力または貼り付けを行うことができます。インポートしたスクリプトを編集することもできます。[スクリプト] タブのフォント設定は、[] を使用して、[式とスクリプトのエディタ] を選択することで変更できます。スクリプトのエディタでは、構文の強調表示と自動字下げが可能で、スクリプトの書き込みや読み取りを簡単に行えます。
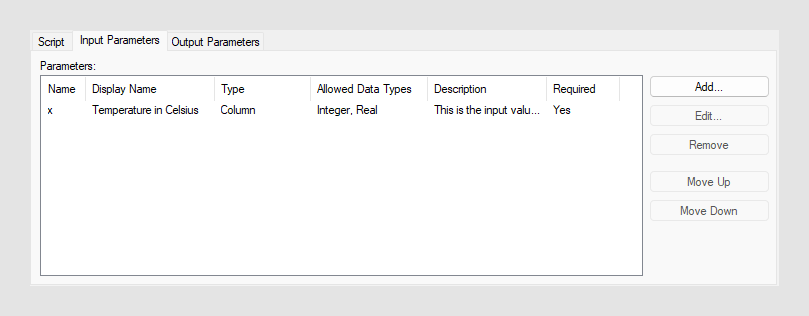
- [入力パラメータ名] または [名前] は、関数またはスクリプトで参照されているパラメータの名前です。
- [表示名] は、エンド ユーザーに表示されるパラメータの名前です。
- [タイプ] は入力タイプを決定します。[値]、[カラム] または [テーブル] (またはデータテーブル) のいずれかを指定します。これによって、入力パラメータを 1 つ以上のカラムにできるか、単一の値にできるかが定義されます。
- [許可されたデータ型] は、この入力パラメータでサポートされるデータ型を指定します。入力パラメータを定義する際に、許可するデータ型をすべて選択することができます。入力パラメータごとに、少なくとも 1 つのデータ型を選択する必要があります。
- [Description] には、オプションで入力パラメータに関する詳細情報を含めることができます。これにより、何を入力すべきかについてエンド ユーザーが理解しやすくなります。
- [Required parameter] は、関数の呼び出し時に必要なパラメータを指定します。パラメータが必要ない場合は、その関数はパラメータなしで動作するはずです。
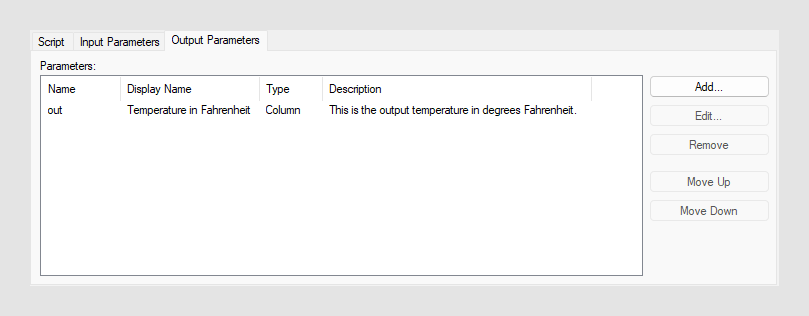
- [結果パラメータ名] または [名前] は、関数またはスクリプトで参照されるパラメータの名前です。
- [表示名] は、エンド ユーザーに表示されるパラメータの名前です。
- [タイプ] は出力タイプを決定します。[値]、[カラム] または [テーブル] (またはデータテーブル) のいずれかを指定します。これによって、出力パラメータが 1 つまたは複数のカラムであるか、または単一の値であるかが定義されます。
- [Description] には、オプションで出力パラメータに関する詳細情報を含めることができます。これにより、何が出力されるのかについてエンド ユーザーが理解しやすくなります。
TERR_* 関数を使用して、演算式の言語に直接 TERR スクリプトを追加できます。それらは、計算カラムおよびカスタム演算式の式言語におけるその他の関数として使用することもできます。ただし、式の関数は異なる分析間で共有できないことに注意してください。