데이터 피벗
피벗 변환은 길고 좁은 형식의 데이터를 짧고 넓은 형식으로 변환하는 한 가지 방법입니다. 일반적으로 값을 집계하는 여러 컬럼으로 데이터가 분산됩니다. 즉, 원본 데이터의 여러 값이 새 데이터 테이블의 동일한 위치에 배치됩니다.
예
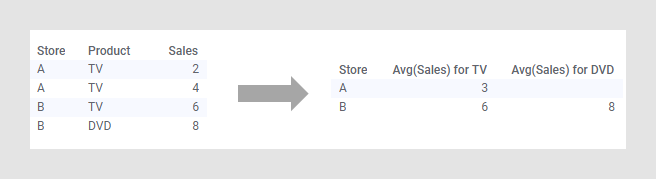
아래 예에서는 매우 간단한 데이터 세트의 피벗 변환을 보여 줍니다. 원본 데이터 테이블에는 세 개의 컬럼과 네 개의 행이 있습니다. 각 행에는 두 백화점 A 또는 B 중 하나와 제품 TV 또는 DVD 및 판매 수에 대한 숫자 값이 포함되어 있습니다. 매일 새 행이 추가되는 경우의 데이터 테이블은 이와 비슷합니다.
각 백화점에서 판매되는 각 제품의 평균 단위 수를 확인할 수 있습니다.
데이터 테이블을 피벗한 후 두 제품에 대한 숫자 값에 집계 방법 "평균"을 사용하여 새 데이터 테이블을 표시합니다. 이 데이터 테이블에는 백화점당 하나씩 두 개의 행만 있습니다. 테이블 레이아웃은 길고 좁은 형식에서 짧고 넓은 형식으로 변경되었습니다. 데이터 테이블에 제품이 여러 개 있는 경우 차이가 더 두드러집니다. 새 데이터 테이블에서 각 백화점에서 매일 판매하는 제품의 평균 수를 쉽게 확인할 수 있습니다. 첫 번째 행에서는 백화점 A에서 지정된 날짜에 DVD는 판매하지 못하고 TV 3대를 판매했음을 보여 줍니다. 백화점 B에서는 일일 평균 6대의 TV와 8대의 DVD를 판매합니다.
예
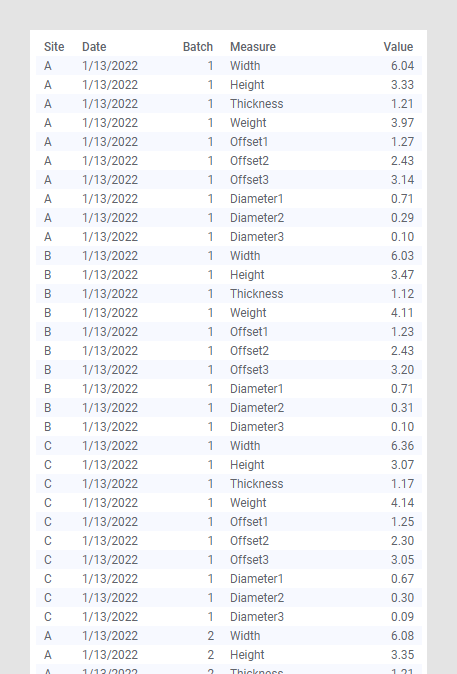
이 예에서는 소형 기계 부품을 생산하는 가상 기업의 데이터를 포함하는 대용량 데이터 세트를 사용합니다. 이러한 부품은 너비, 높이 및 두께를 측정합니다. 부품에는 세 개의 구멍이 있습니다. 또한 이 부품은 구멍의 지름과 구멍이 있어야 하는 위치로부터의 작은 오프셋도 측정합니다.
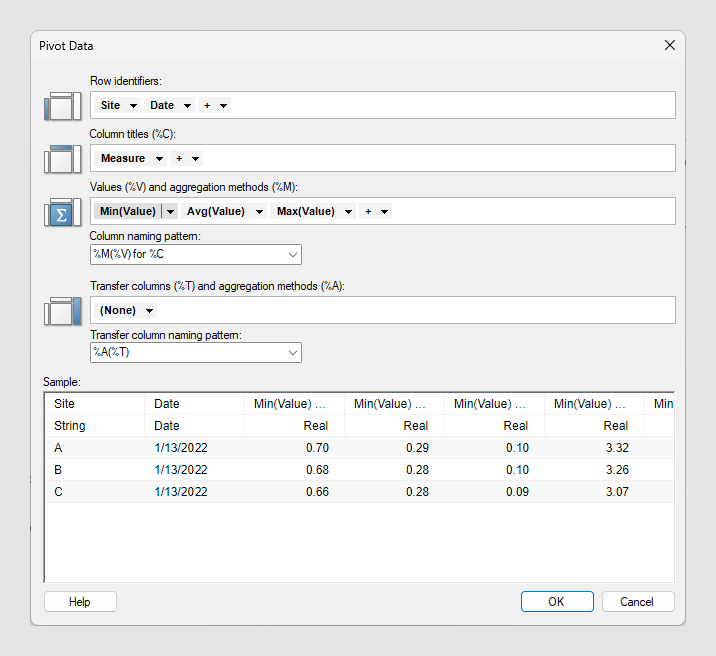
새 컬럼의 순서는 이름 지정 표현식의 결과에 의해 결정되며 사전순으로 정렬됩니다.
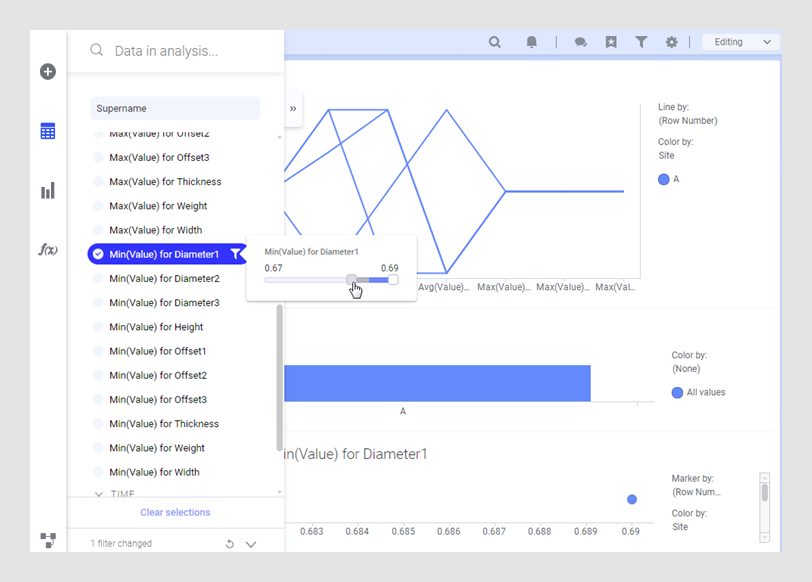
분석에서 지름이 작지 않아야 한다는 것이 가장 중요한 기준일 경우 A 공장에서 가장 까다로운 고객에게 부품을 공급해야 합니다.