Enrejado
Una visualización enrejada se divide en varios paneles, donde cada panel representa un subconjunto de los datos. Al utilizar visualizaciones enrejadas, puede detectar similitudes y diferencias entre los subconjuntos de datos o dentro de los subconjuntos.
Los subconjuntos se pueden definir dividiendo los datos en categorías que estén disponibles en una columna de datos, alternativamente dividiendo los datos por columna de datos; posteriormente, cada categoría o columna se muestra en un panel independiente.
Para dividir los datos por columnas de datos, consulte Visualizaciones enrejadas por columnas de datos.
Ejemplo 1
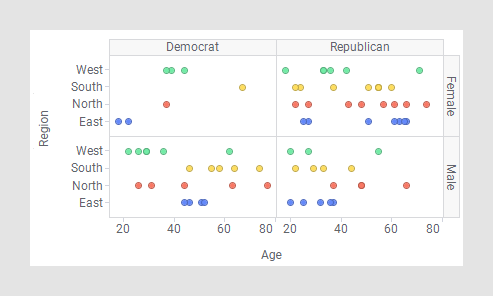
Si se elige una visualización enrejada basada en las dos variables Sexo y Afiliación política, se obtendrán cuatro paneles separados que representarán las combinaciones de femenino-republicano, femenino-demócrata, masculino-republicano y masculino-demócrata.
Si la variable Sexo se usa junto con otra variable que tenga cinco valores distintos, esto producirá diez paneles. De esto se deduce que las variables con una distribución continua y un amplio rango de valores (por ejemplo, los valores Real) deberían clasificarse en bandejas antes de usarse en una visualización enrejada. De lo contrario, el número de paneles se vuelve imposible de gestionar.
Este es un gráfico de dispersión no enrejado estándar:
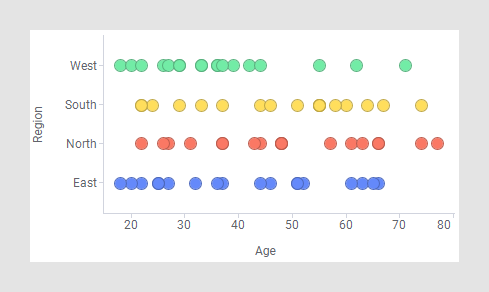
Al enrejar esta visualización basada en Sexo y Afiliación política, tendrá el siguiente aspecto:
Ejemplo 2
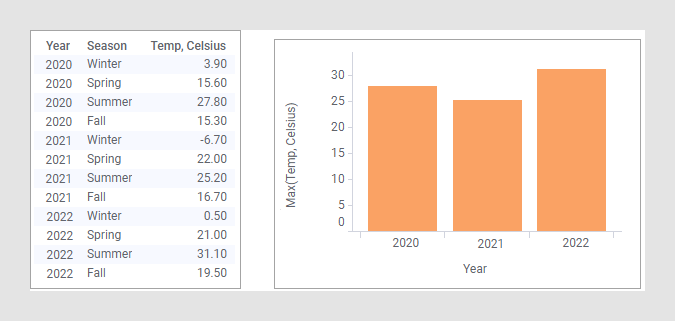
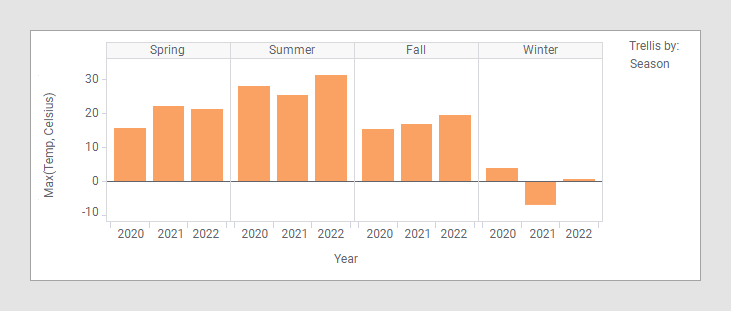
Los paneles de arriba se colocan horizontalmente, pero también se pueden colocar verticalmente o distribuidos uniformemente en una matriz.