데이터 함수란?
데이터 함수는 꽤 많은 유형의 계산을 수행할 수 있는 스크립트를 만들고 결과를 Spotfire 분석으로 반환하여 고급 분석가, 통계학자 또는 수학자가 Spotfire를 향상시킬 수 있도록 해주는 Spotfire의 방식입니다. 데이터 함수는 설치된 Spotfire 클라이언트를 사용하여 만들 수 있습니다. 데이터 함수를 라이브러리에 저장하면 TIBCO Spotfire Advanced Analytics의 데이터 함수 실행 라이센스 기능이 있는 Spotfire Business Author에서 새 분석을 만들 때 데이터 함수를 사용할 수 있습니다. 소비자 사용자는 완료된 분석으로 상호 작용할 때 계산의 결과를 이용할 수 있습니다.
데이터 함수는 매우 유연하기 때문에 다음과 같은 여러 용도에 사용할 수 있습니다.
- 데이터 열기.
- 데이터 변환(설치된 클라이언트에서만 변환을 추가할 수 있음).
- 첫 번째 데이터 테이블에 기반하여 새 데이터 테이블을 추가하여 시각화에 기능을 추가(예: 곡선).
대개의 경우 데이터 함수의 사용은 입력을 출력에 매핑하는 것입니다. 즉, 현재 분석의 컨텍스트에서 스크립트 실행 시 계산의 기반이 될 값과 계산 결과를 넣을 위치를 사용자가 지정해야 합니다.
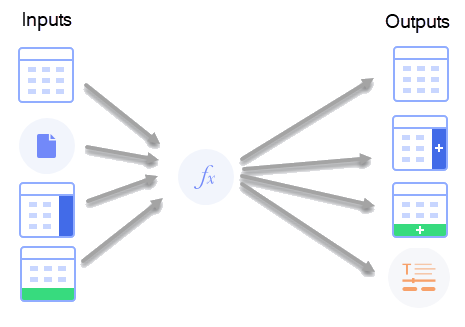
예를 들어 입력은 현재 분석의 컬럼이나 데이터 또는 값일 수 있지만, 스크립트가 다른 곳에서 데이터를 가져오고 데이터 함수가 분석의 첫 번째 데이터 테이블의 소스 역할을 하도록 하는 것도 가능합니다.
출력은 숫자 값(예: 모델 계수, 예측 등), 텍스트(예: 요약 진단) 또는 R 그래픽 개체의 모든 조합일 수 있습니다. 또한 출력은 Spotfire에서 값, 컬럼 또는 데이터 테이블에 매핑됩니다. 새 컬럼이 생성될 때 원하는 경우 기존 데이터 테이블에 통합할 수도 있습니다. 단일 값 출력이 설치된 클라이언트를 사용하여 구성된 경우 단일 값 출력을 속성에 매핑하고 텍스트 영역에 표시할 수 있습니다.
라이브러리에서 손쉽게 데이터 함수를 찾고 재사용하려면 데이터 함수를 f(x) 플라이아웃에 고정하면 됩니다.
데이터 함수 정의와 데이터 함수 인스턴스
실제로 라이브러리에는 데이터 함수 정의가 저장됩니다. 여기에는 스크립트 자체와 예상하거나 허용할 입력 및 출력 유형에 대한 작성자의 사양이 포함됩니다.
분석의 입력 및 출력에 정의를 매핑하여 데이터 함수를 실행할 때 문서에 해당 데이터 함수의 인스턴스를 만듭니다. 분석에서 동일한 데이터 함수를 여러 번 실행하는 경우 여러 인스턴스가 분석에 포함될 수 있지만 이 인스턴스는 서로 다른 입력으로 데이터 함수를 실행하여 각기 다른 출력을 사용 또는 유지하려고 할 때만 필요합니다(동일한 함수를 사용하여 다수의 계산된 컬럼을 만들 때와 유사). 문서에서 각 데이터 함수 정의의 단일 인스턴스를 유지하는 것은 성능상의 이유로 대부분의 경우 선호되는 옵션입니다.
데이터 함수를 갱신하거나 이미 존재하는 데이터 함수 인스턴스의 매개변수 또는 스크립트를 조정하려는 경우 다시 추가하는 대신 데이터 캔버스에서 편집할 수 있습니다.