Múltiplas Tabelas de Dados em Uma Visualização
Às vezes os dados que você deseja analisar no Spotfire estão situados em tabelas de dados diferentes. Trabalhar com visualizações combinando dados de várias tabelas de dados não é muito diferente de trabalhar com dados de uma tabela de dados simples. Você pode escolher a visualização que melhor se adapta aos seus dados, pode filtrar, marcar e detalhar seus dados. No entanto, alguns conceitos são importantes ao configurar e trabalhar com uma visualização que combina dados de diferentes tabelas de dados.
A tabela de dados principal
Em uma visualização, combinando dados de tabelas de dados diferentes, a tabela de dados principal desempenha um papel importante. Uma visualização sempre tem apenas uma tabela de dados principal, que é o ponto de ancoragem nos dados para visualização. Ela define o que é uma linha em uma visualização não agregada, e as colunas da tabela de dados principal são as colunas que podem ser usadas para agrupar a visualização de diferentes maneiras. Consequentemente, as colunas da tabela de dados principal controlam o que se torna um item (como um marcador em um gráfico de dispersão ou uma barra em um gráfico de barras) em uma visualização agregada.
Quando você marca itens em uma visualização, os detalhes são mostrados apenas para as colunas na tabela de dados principal. A tabela de dados principal também é a tabela de dados à qual todas as expressões se referem por padrão, a menos que você especifique explicitamente que uma expressão deve se referir a outra tabela de dados na visualização usando o nome da coluna qualificada: [Nome da tabela de dados].[Nome da coluna]. (Por exemplo: Sum([Vendas do ano anterior].[Vendas]) onde 'Vendas do ano anterior' é o nome da tabela de dados e 'Vendas' é o nome da coluna.)
Para obter o máximo de seus dados, pense em qual tabela de dados é mais adequada como a tabela de dados principal antes de começar a configurar a visualização.
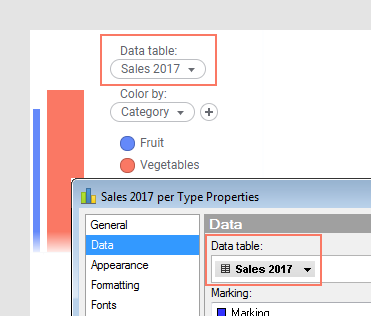
Selecione a tabela de dados principal na seção Dados das Propriedades de visualização ou no seletor de tabela de dados na legenda. Na imagem abaixo, o nome da tabela de dados principal é 'Vendas 2017':
Tabelas de dados adicionais
Colunas de outras tabelas de dados além da tabela de dados principal podem ser usadas em eixos de agregação na visualização, mas não em eixos que estão agrupando a visualização.
Para adicionar uma coluna de outra tabela de dados, use o recurso de arrastar e soltar no submenu Análise de dados ou no painel de Filtros ou selecione uma coluna no seletor de coluna. Abra o seletor de coluna e mude para a tabela de dados de interesse; o seletor de coluna mudará para mostrar as colunas na tabela de dados selecionada. O seletor de tabela de dados só fica visível se você tiver várias tabelas de dados na análise e houver correspondências de coluna disponíveis, veja abaixo. Correspondências de coluna só podem ser editadas usando o cliente instalado, mas, quando elas existem, você pode adicionar outra tabela de dados a uma visualização do cliente Web.
Correspondendo colunas
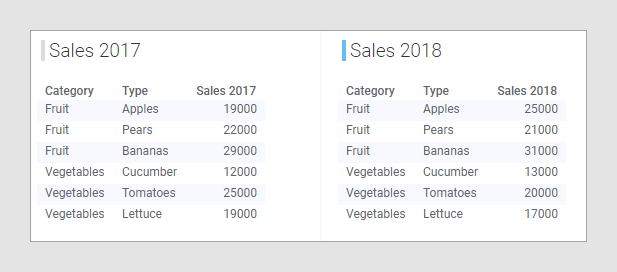
Outro conceito que é importante saber é a correspondência de coluna. Para uma visualização mostrar dados de várias tabelas de dados, pelo menos uma coluna que você usar para a visualização de algum modo deve corresponder a uma coluna correspondente nas outras tabelas de dados na visualização. Uma coluna é correspondente se ela contiver o mesmo tipo de dados. Se as colunas contiverem valores do mesmo tipo de dados E tiverem nomes de colunas idênticos, elas serão correspondidas automaticamente. Por exemplo, nas duas tabelas de dados 'Vendas 2017' e 'Vendas 2018' abaixo, as colunas 'Categoria' e 'Tipo' correspondem entre as tabelas de dados. Uma regra básica ao configurar uma visualização é que todas as categorias que você usará na visualização devem existir em todas as tabelas de dados. Dessa forma, a correspondência de colunas vai ser fácil. No entanto, existem excepções a essa regra. Para saber mais sobre isso, consulte a seção sobre Correspondências de colunas ausentes em Correspondências de coluna.
Se nenhuma correspondência automática for encontrada, você poderá adicionar correspondências de forma manual. Para saber mais sobre quando e como corresponder colunas manualmente, consulte Correspondências de coluna, Adicionando correspondências de coluna de forma manual e os seguintes tópicos.
Embora geralmente não seja necessário definir uma relação entre tabelas de dados além de uma correspondência de coluna, às vezes pode ser útil fazer isso. Com uma relação entre duas tabelas de dados, a marcação e a filtragem de uma tabela de dados podem ser propagadas para outra tabela de dados. Para ler mais sobre como especificar como a filtragem deve funcionar em tabelas de dados relacionadas, consulte Filtragem em tabelas de dados relacionadas.
Exemplo básico
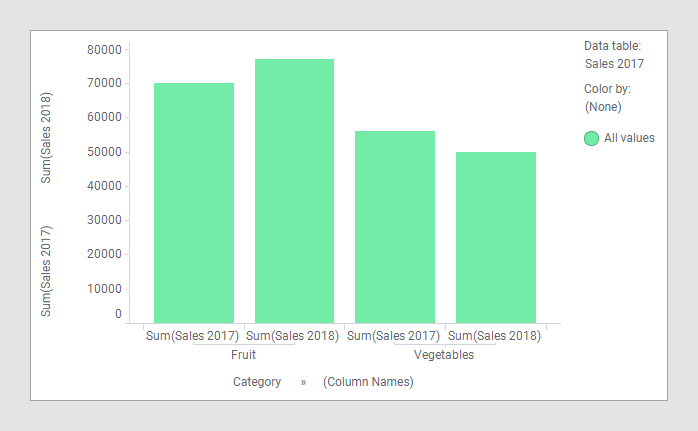
Comparar os dados nas duas tabelas de dados acima em um gráfico de barras não requer adaptações especiais. Apenas carregue as duas tabelas de dados no Spotfire, crie o gráfico de barras, selecione uma das colunas categóricas sobre o eixo por categoria e, em seguida, selecione as duas colunas 'Vendas 2017' e 'Vendas 2018' no eixo de valor.
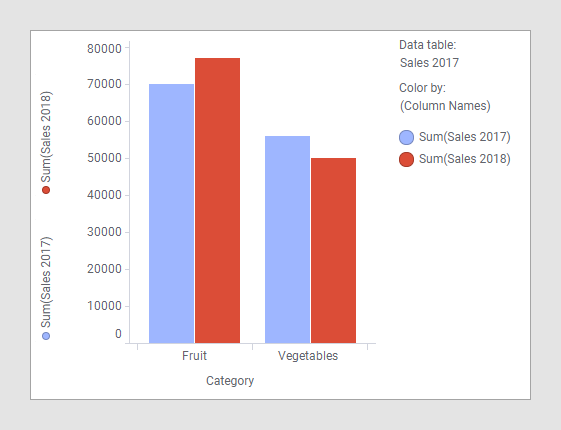
Como as colunas “Categoria” e “Tipo” nessas duas tabelas de dados têm nomes idênticos e contêm valores do mesmo tipo de dados, elas já foram correspondidas automaticamente. Como o exemplo ilustra, a tabela de dados principal é 'Vendas 2017', e, portanto, a coluna usada no eixo por categoria se origina dessa tabela de dados. Neste exemplo, qualquer uma das duas tabelas de dados pode ser usada como a tabela de dados principal, porque as colunas categóricas são as mesmas em ambas as tabelas de dados. Como sempre, quando várias colunas são utilizadas no eixo de valor de um gráfico de barras, (Nomes das Colunas) deve ser usado para agrupar a visualização. Na imagem acima, a opção (Nomes das colunas) é usada para colorir, mas usá-la para treliçar ou, como na imagem abaixo, adicioná-la ao eixo de categoria são outras possibilidades.
Diferentes níveis de detalhe
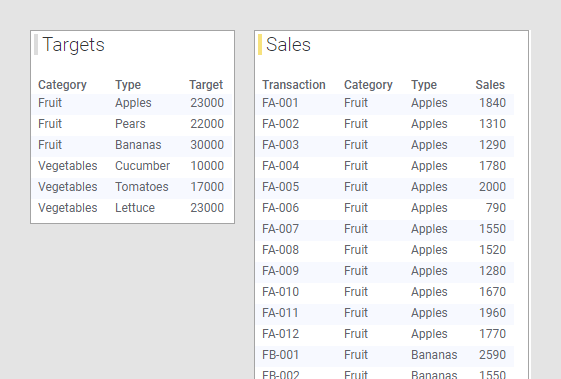
No exemplo acima, as tabelas de dados tinham mais ou menos as mesmas colunas; 'Categoria', 'Tipo' e uma coluna que contém os números de vendas. Você também pode comparar dados de tabelas de dados com dados em diferentes níveis de detalhe em uma visualização. Por exemplo, você pode comparar as metas de vendas para um determinado ano com as vendas reais até o momento para o ano. Talvez você tenha uma tabela de dados que contém metas de vendas de frutas e legumes. Para cada tipo de vegetais e frutas, uma única linha representa a meta, como visto na tabela de dados 'Metas' abaixo. Em outra tabela de dados, você pode ter os dados de vendas reais do ano atual, conforme mostrado na tabela de dados “Vendas” abaixo. Nesta tabela de dados cada operação de venda é representada por uma linha, o que significa que para cada tipo de frutas e vegetais, existem várias linhas de números de vendas.
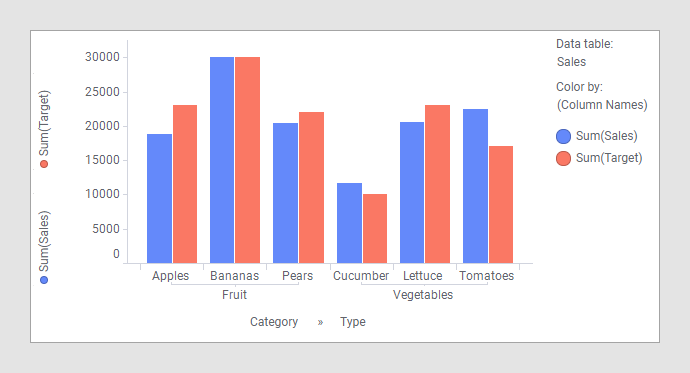
Ao combinar os dados dessas duas tabelas de dados em um gráfico de barras, você pode ver quais frutas e vegetais atingiram suas metas este ano:
Fluxo de trabalho recomendado
Se você não tiver certeza de como configurar uma visualização combinando colunas de diferentes tabelas de dados, este fluxo de trabalho recomendado pode ser útil.
1. Escolha a tabela de dados principal
Comece olhando para os dados nas tabelas de dados diferentes e tente responder algumas perguntas. Quais dados elas contém? O que você deseja visualizar com base nesses dados? Uma tabela de dados contendo as categorias pelas quais você deseja agrupar sua visualização é um bom candidato para a tabela de dados principal. Por exemplo, você pode querer agrupar por região, departamento, vendedor, tipo de produto ou similar.
2. Configure a visualização apenas com a tabela de dados principal
Adicione uma visualização do tipo que deseja usar e configure o máximo possível dessa visualização com colunas apenas da tabela de dados principal. Selecione como e por quais colunas a visualização deve ser agrupada, e se a tabela de dados principal também contém colunas que você deseja mostrar como agregadas, adicione as colunas aos eixos apropriados também.
3. Adicione as medidas de agregação
Quando a visualização foi configurada, tanto quanto possível, com apenas a tabela de dados principal, você pode iniciar adicionando colunas agregadas de outras tabelas de dados.