Daten pivotieren
Die Umwandlung Daten pivotieren wird verwendet, um Daten von einem langen/schmalen Format in ein kurzes/breites Format umzuwandeln.
Informationen zum Hinzufügen einer Umwandlung zu einer Analyse finden Sie unter Umwandeln von Daten.
Ein Beispiel dafür, wann Pivoting nützlich sein kann, finden Sie unter Pivotieren von Daten.
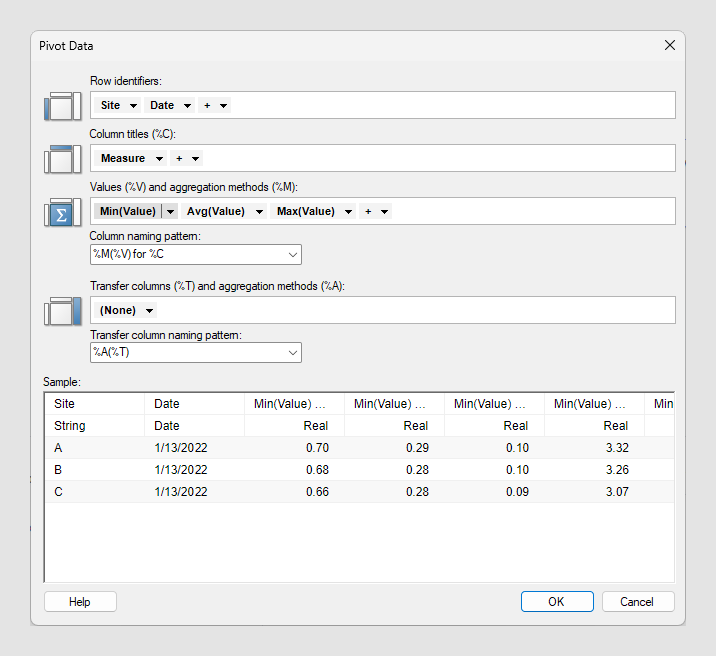
| Option | Beschreibung |
|---|---|
| Zeilen-IDs | Jeder eindeutige Wert in der gewählten Identitätsspalte oder Hierarchie erzeugt eine Zeile in der generierten Tabelle. Wenn Sie mehrere Spalten wählen, enthält die neue Tabelle eine eigene Zeile für jede eindeutige Wertekombination in den gewählten Spalten. |
| Spaltentitel (% C) | Jeder eindeutige Wert in der gewählten Kategoriespalte oder Hierarchie erzeugt für jede Aggregationsmethode eine neue Spalte in der generierten Datentabelle. Wenn Sie mehrere Spalten auswählen, enthält die neue Datentabelle eine eigene Spalte für jede eindeutige Wertekombination in den gewählten Spalten. Die Spaltentitel werden im Muster für die Spaltenbenennung verwendet (siehe unten). |
| Werte (% V) und Aggregationsmethoden (% M) | Die Spalte, aus der die Daten für die Berechnung stammen. Die Werte in der generierten Datentabelle werden gemäß der im Menü des Spaltenselektors unter Aggregation ausgewählten Methode berechnet (z. B. Average). Eine Liste der Aggregationsmethoden finden Sie auf der Seite Statistische Funktionen.Anmerkung: Neben den auf der Seite der statistischen Methoden angegebenen Methoden kann auch die Methode
Count() verwendet werden. Sie berücksichtigt alle Werte, einschließlich leerer Werte, und gibt daher die Gesamtanzahl von Zeilen in der Spalte zurück.Anmerkung: Wenn Sie sicher sind, dass alle Kombination aus Identität und Kategorie einen eindeutigen Wert besitzen, können Sie als Aggregation: Keine auswählen, wodurch keine Aggregation auf die Daten angewendet wird. Die Pivot-Aufbereitung schlägt jedoch fehl, wenn Sie Keine auswählen und nicht jede Kombination aus Identität und Kategorie eindeutig ist.
|
| Muster für Spaltenbenennung | Sie können auswählen, wie die pivotierten Spalten benannt werden sollen. Folgende Option ist standardmäßig vorgegeben: Methode(Wert) für Spalte Darüber hinaus haben Sie die Möglichkeit, das Schema für Ihre pivotierten Spalten zu benennen. Durch Klicken auf die Dropdownliste können Sie eine Auswahl aus den zuletzt verwendeten Namen treffen. Die resultierenden neuen Spalten werden alphabetisch nach den vom Benennungsausdruck festgelegten Namen sortiert. |
| Übertragungsspalten (% T) und Aggregationsmethoden (% A) | Mit dieser Option können Sie einen Gesamtdurchschnitt eines bestimmten Messwerts oder eine beliebige andere Aggregationsmethode von der Seite Statistische Funktionen für jede Zeile in der generierten Tabelle einfügen. Anmerkung: Neben den auf der Seite der statistischen Methoden angegebenen Methoden kann auch die Methode
Count() verwendet werden. Sie berücksichtigt alle Werte, einschließlich leerer Werte, und gibt daher die Gesamtanzahl von Zeilen in der Spalte zurück. |
| Muster für Übertragungsspaltenbenennung | Sie können auswählen, wie die Übertragungsspalten benannt werden sollen. Folgende Option ist standardmäßig vorgegeben: Aggregation(TransferValue) Durch Klicken auf die Dropdownliste können Sie eine Auswahl aus den zuletzt verwendeten Namen treffen. |
| Beispiel | Gibt ein Beispiel für die resultierende Datentabelle. Anmerkung: Das Beispiel verwendet die ersten 100 Zeilen aus der Datentabelle, daher können einige Unterschiede zwischen der Beispieltabelle und der resultierenden Datentabelle bestehen.
|