データのピボット
[データのピボット] 変換は、データを Tall/Skinny 形式から Short/Wide 形式に変換するのに使用されます。
分析に変換を追加する方法については、「データを変換する」を参照してください。
ピボットが有用な場合の例については、「データをピボットする」を参照してください。
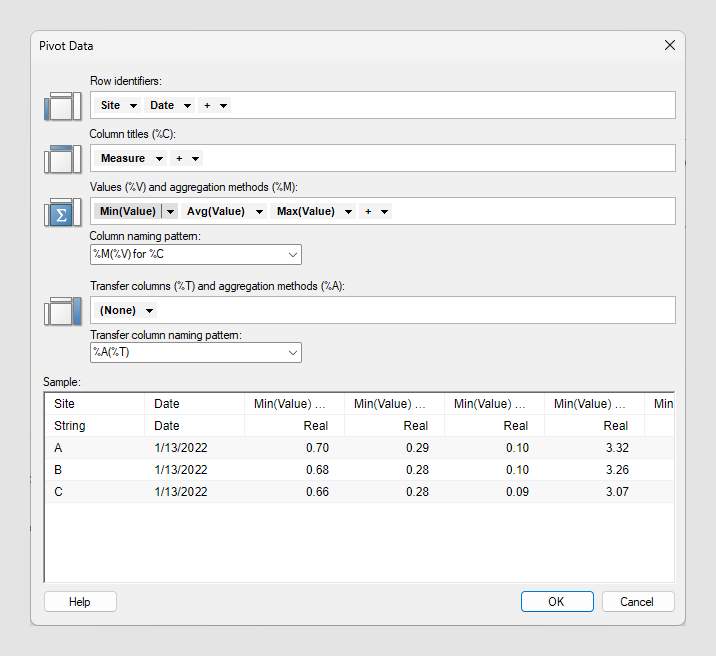
| オプション | 説明 |
|---|---|
| ローの識別子 | 生成されたテーブルには、選択した ID カラムまたは階層の固有値ごとに 1 つのローが作成されます。 複数のカラムを選択した場合は、新しいテーブルには、選択したカラム内の値の固有の組み合わせごとに別個のローが作成されます。 |
| カラム タイトル (%C) | 生成されたデータテーブルには、選択したカテゴリカラムまたは階層の固有値ごとに、各集計方法について 1 つの新規カラムが作成されます。 複数のカラムを選択した場合は、新しいデータテーブルには、選択したカラム内の値の固有の組み合わせごとに別個のカラムが作成されます。 カラムタイトルは、カラムの命名パターンで使用されます。以下を参照してください。 |
| 値 (%V) および集計方法 (%M) | これはデータ値の計算元となるカラムです。生成されたデータテーブル内の値は、カラム セレクター メニューの [集計] で選択された方法 ([Average] など) に従って計算されます。集計方法のリストは、「統計関数」のページにあります。注: 「統計関数」のページにあるメソッドに加え、メソッド
Count() を使用できます。空の値を含むすべての値を含むため、カラム内のローの総数を返します。注: ID とカテゴリの各組み合わせに固有値が含まれていることが確実にわかっている場合は、[集計:] で[なし] を選択できます。このオプションを選択すると、データのどの集計も適用されません。ただし、[なし] を選択した場合に、ID とカテゴリの各組み合わせが固有でない場合は、ピボットを正常に実行できません。
|
| カラムの命名パターン | ピボットされたカラムの命名規則を指定できます。既定では、次の事前定義規則が使用されます。 カラムのメソッド(値) 各自のピボットされたカラム用に、カスタムの命名規則を作成することもできます。 ドロップダウン リストをクリックすると、最近使用した名前の中から選択できます。 結果の新規カラムが命名式によって決定された名前別にアルファベット順に並べ替えられます。 |
| 転送カラム (%T) および集計方法 (%A) | このオプションを使用すると、生成されたテーブルの各ローについて、特定の測定値に関する全体的平均、または「統計関数」のページにリストされているその他の集計方法を含めることができます。 注: 「統計関数」のページにあるメソッド以外に、メソッド
Count() も使用できます。空の値を含むすべての値を含むため、カラム内のローの総数を返します。 |
| 転送カラムの命名パターン | 転送カラムの名前を変更する方法を選択できます。既定では、次の事前定義規則が使用されます。 Aggregation(TransferValue) ドロップダウン リストをクリックすると、最近使用した名前の中から選択できます。 |
| サンプル | 結果のデータテーブルがどのようになるかのサンプルを示します。 注: サンプルはデータテーブルからの最初の 100 個のローを使用しているため、サンプルと結果のデータテーブルは一部異なる可能性があります。
|