统计函数
下面的列表显示了可在表达式中使用的统计函数。
| 函数 | 说明 |
|---|---|
Avg(Arg1, ...)
|
返回参数的平均值(算术平均值)。参数和结果是实数类型。如果指定了一个参数,则结果为所有行的平均值。如果指定了多个参数,则结果为每个行的平均值。Null 参数被忽略并且不能平均。 示例:
|
ChiDist(Arg1)
|
将返回参数的 (上尾) 卡方分布的 p 值。 示例:
|
ChiInv(Arg1)
|
将返回参数的 (上尾) 卡方分位数值。 示例:
|
Count(Arg1)
|
计算参数列中的非空值数,或在未指定参数时,计算总行数。 示例:
|
CountBig(Arg1)
|
计算参数列中的非空值数,或在未指定参数时,计算总行数。该函数返回一个 LongInteger。 示例:
|
Covariance(Arg1, Arg2)
|
计算以参数形式指定的两个列的协方差。 示例:
|
FDist(Arg1)
|
将返回参数的上尾 F 分布的 p 值。 示例:
|
FInv(Arg1)
|
将返回参数的(上尾)F 分位数值。 示例:
|
First(Arg1)
|
将基于参数列中数据所在行的物理顺序返回第一个有效值。 示例:
|
GeometricMean()
|
计算几何平均值。如果任何输入值为负数,那么结果将为“空”。如果任何输入值等于零,那么结果将为零。 示例:
|
IQR(Arg1)
|
计算 Q3-Q1 或 P75-P25 的值差。IQR 也称为 H 展开。 示例:
|
L95(Arg1)
|
计算 95% 置信区间的下端点。 注: 此函数使用的静态 t 值 1.959964 适用于大样本量 ( n >= 40)。对于较小的样本量,请改用下面的表达式:
Example:
|
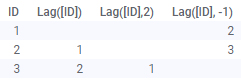
Lag(Arg1, Arg2)
|
将列中的值向下移动指定的步数。第一个参数是要移动的列。第二个(可选)参数是步数。默认值为 1。 如果使用负的步数,则会向相反方向移动值,请参见下图。 示例:
请注意,将按数据的加载顺序对数据应用 Lag 函数;该函数不会将图表中的排序考虑在内,对数据进行的任何更改(例如在重新加载期间)可能会导致各个行具有不同的值。 |
Last(Arg1)
|
将基于参数列中数据所在行的物理顺序返回最后一个有效值。 示例:
|
LastValueForMax(Arg1, Arg2)
|
将返回第 2 列的值作为第 1 列的最大值。 如果存在多个第 1 列最大值,那么结果是最后一个最大值行的值。另请参见 示例:
|
LastValueForMin(Arg1, Arg2)
|
将返回第 2 列的值作为第 1 列的最小值。 如果有多个第 1 列最小值,则结果将是最后一个最小行数的值。另请参见 示例:
|
LAV(Arg1)
|
计算下邻值。 示例:
|
Lead(Arg1, Arg2)
|
将列中的值向上移动指定的步数。第一个参数是要移动的列。第二个(可选)参数是步数。默认值为 1。 如果使用负的步数,则会向相反方向移动值,请参见下图。 示例:
请注意,将按数据的加载顺序对数据应用 Lead 函数;该函数不会将图表中的排序考虑在内,对数据进行的任何更改(例如在重新加载期间)可能会导致各个行具有不同的值。 |
LIF(Arg1)
|
计算下内围。这是位于 Q1 – (1.5*IQR) 的阈值。示例:
|
LOF(Arg1)
|
计算下外围。这是位于 Q1 – (3*IQR) 的阈值。示例:
|
Max(Arg1, ...)
|
计算最大值。如果指定了一个参数,则结果为整个列的最大值。如果指定了多个参数,则结果为每个行的最大值。参数和结果是实数类型。Null 参数被忽略。 示例:
|
MeanDeviation(Arg1, ...)
|
计算平均偏差值(平均绝对偏差,AAD)。如果指定了一个参数,则结果为所有行的平均差值。如果指定了多个参数,则结果为每个行的平均差值。 示例:
|
Median(Arg1)
|
计算参数的中位数。如果指定了一个参数,则结果为所有行的中值。如果指定了多个参数,则结果为每个行的中值。 示例:
|
MedianAbsoluteDeviation(Arg1, ...)
|
计算绝对中位偏差 (MAD)。如果指定了一个参数,则结果为所有行的绝对中位差值。如果指定了多个参数,则结果为每个行的绝对中位差值。 示例:
|
Min(Arg1, ...)
|
计算最小值。如果指定了一个参数,则结果为整个列的最小值。如果指定了多个参数,则结果为每个行的最小值。参数和结果是实数类型。Null 参数被忽略。 示例:
|
NormDist(Arg1)
|
将返回参数的 (上尾) 正态分布的 p 值。如果您未指定,默认情况下平均值 = 0,标准偏差 = 1。 示例:
|
NormInv(Arg1)
|
将返回参数的(上尾)正态分位数值。如果您未指定,默认情况下平均值 = 0,标准偏差 = 1。 示例:
|
NthLargest(Arg1, Arg2)
|
第 n 个最大值。第一个参数是要分析的列,第二个参数是 n 的值。 如果 n 大于列中值的数量,则将返回最小值。 示例:
|
NthSmallest(Arg1, Arg2)
|
第 n 个最小值。第一个参数是要分析的列,第二个参数是 n 的值。 如果 n 大于列中值的数量,则将返回最大值。 示例:
|
Outliers(Arg1)
|
外围值计数。将计算大于上相邻值或小于下相邻值的值的计数。 示例:
|
P10(Arg1)
|
P10 是指某个值,在该值处,10% 的数据值等于或小于该值。 示例:
|
P90(Arg1)
|
P90 是指某个值,在该值处,90% 的数据值等于或小于该值。 示例:
|
PctOutliers(Arg1)
|
外围值计百分位。将计算大于上相邻值或小于下相邻值的值所占的百分比。 示例:
|
Percent(Arg1, Arg2)
|
百分比是在值范围 (最大值 – 最小值) 内计算的大于最小值的特定百分比的值。第一个参数是要分析的列,第二个参数是百分比。 示例:
|
Percentile(Arg1, Arg2)
|
百分位是指某个值,在该值处,特定百分比的数据值等于或小于该值。第一个参数是要分析的列,第二个参数是百分比。 示例:
|
Q1(Arg1)
|
计算第一个四分位数。 示例:
|
Q3(Arg1)
|
计算第三个四分位数。 示例:
|
Range(Arg1)
|
列中最大值和最小值之间的间距。 结果将显示为实数还是时间跨度,取决于参数的数据类型。 示例:
|
StdDev(Arg1)
|
计算标准偏差。 示例:
|
StdErr(Arg1)
|
计算标准误差。 示例:
|
TDist(Arg1)
|
将返回参数的 (上尾) T 分布的 p 值。 示例:
|
TERR_Binary
|
调用 Spotfire® Enterprise Runtime for R(又名 TERR™),并返回指定数据类型的输出,其中包含的行数与输入相同。 第一个参数为脚本,随后的参数为脚本的参数。 返回的列具有的行数必须与输入相同。除脚本以外,至少需要一个参数。输入将放在名为 示例:
|
TERR_Boolean
|
请参见上面的 TERR_Binary。 |
TERR_DateTime
|
请参见上面的 TERR_Binary。 |
TERR_Integer
|
请参见上面的 TERR_Binary。 |
TERR_Real
|
请参见上面的 TERR_Binary。 |
TERR_String
|
请参见上面的 TERR_Binary。 |
TERRAggregation_Binary
|
调用 TERR 引擎并返回指定数据类型的输出。第一个参数为脚本,随后的参数为脚本的参数。 该脚本应该返回单个聚合值。除脚本以外,至少需要一个参数。输入将放在名为 示例:
|
TERRAggregation_Boolean
|
请参见上面的 TERRAggregation_Binary。 |
TERRAggregation_DateTime
|
请参见上面的 TERRAggregation_Binary。 |
TERRAggregation_Integer
|
请参见上面的 TERRAggregation_Binary。 |
TERRAggregation_Real
|
请参见上面的 TERRAggregation_Binary。 |
TERRAggregation_String
|
请参见上面的 TERRAggregation_Binary。 |
TInv(Arg1)
|
将返回参数的 (上尾) T 分位数值。 示例:
|
TrimmedMean(Arg1, Arg2)
|
计算被剪裁的平均值 (剪裁平均值)。第一个参数是要分析的列,第二个参数使用百分比的形式,指示要从计算中排除的值数。如果剪裁值设置为 10%,则最高 5% 和最低 5% 的值将从计算的平均值中排除。 示例:
|
U95(Arg1)
|
计算 95% 置信区间的上端点。 注: 此函数使用的静态 t 值 1.959964 适用于大样本量 ( n >= 40)。对于较小的样本量,请改用下面的表达式:
Example:
|
UAV(Arg1)
|
计算上邻值。 示例:
|
UIF(Arg1)
|
计算上内围。这是位于 Q3 + (1.5*IQR) 的阈值。示例:
|
UniqueCount(Arg1)
|
计算参数列中非空唯一值的数量。 示例:
|
UOF(Arg1)
|
计算上外围。这是位于 Q3 + (3*IQR) 的阈值。 示例:
|
ValueForMax(Arg1, Arg2)
|
将返回第 2 列的值作为第 1 列的最大值。 如果存在多个第 1 列最大值,那么结果是第一个最大值行的值。另请参见 示例:
|
ValueForMin(Arg1, Arg2)
|
将返回第 2 列的值作为第 1 列的最小值。 如果有多个第 1 列最小值,则结果将是第一个最小行数的值。另请参见 示例:
|
Var(Arg1)
|
计算方差。 示例:
|
WeightedAverage(Arg1, Arg2)
|
计算两个列的加权平均值。Arg1 是权重列,Arg2 是值列。 示例:
|

提示:DISTINCT 关键字可用以返回仅使用唯一值的结果。例如,Avg(DISTINCT[Column]) 将返回唯一值的平均值,而不是指定列中所有值的平均值。UniqueCount([Column]) 相当于 Count(DISTINCT[Column])。
另请参见函数。