Dinamización de datos
Una transformación de dinamización de datos es una forma de convertir datos de un formato alargado y estrecho en uno corto y ancho. Los datos se suelen distribuir en columnas, agregando los valores. Esto significa que diversos valores de los datos originales acaban en el mismo lugar en la tabla de datos nueva.
Ejemplo
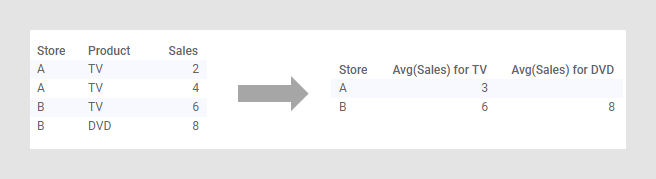
En el ejemplo siguiente se muestra una transformación de dinamización de datos con un conjunto de datos muy sencillo. En la tabla de datos original hay tres columnas y cuatro filas. Cada fila contiene uno de las dos tiendas, A o B; un producto, TV o DVD; y un valor numérico para las cifras de ventas. La tabla de datos podría tener este aspecto si se agrega una fila nueva cada día.
Sin embargo, quizás resulte más interesante conocer cuántas unidades de cada producto se venden en cada tienda un día normal.
Tras dinamizar la tabla de datos y usar el método de agregación "promedio" en los valores numéricos de los dos productos, obtenemos una tabla de datos nueva con solo dos filas, una para cada tienda. El diseño de la tabla ha pasado de largo y estrecho a corto y ancho. Si hubiera más productos en la tabla, la diferencia habría sido incluso más pronunciada. En la tabla de datos nueva resulta fácil comprobar el número de productos que se vende en cada tienda un día promedio. La primera fila indica que un día cualquiera se venden 3 aparatos de TV en la tienda A, pero ningún DVD. Sin embargo, en la tienda B, un día promedio se podrían vender 6 aparatos de TV y 8 de DVD.
Ejemplo
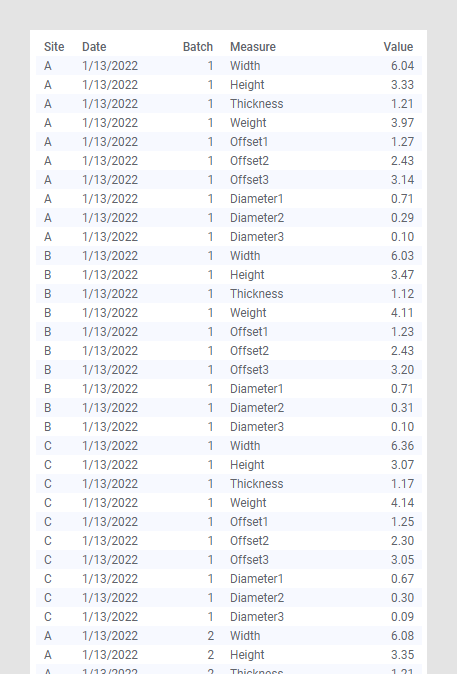
En este ejemplo tenemos un conjunto de datos más grande, con datos de una empresa imaginaria que produce pequeñas piezas de maquinaria. Estas piezas cuentan con medidas de anchura, altura y grosor. Las piezas tienen tres orificios distintos. También hay medidas del diámetro de estos orificios, así como una medida de un posible desplazamiento leve respecto al lugar donde deberían estar.
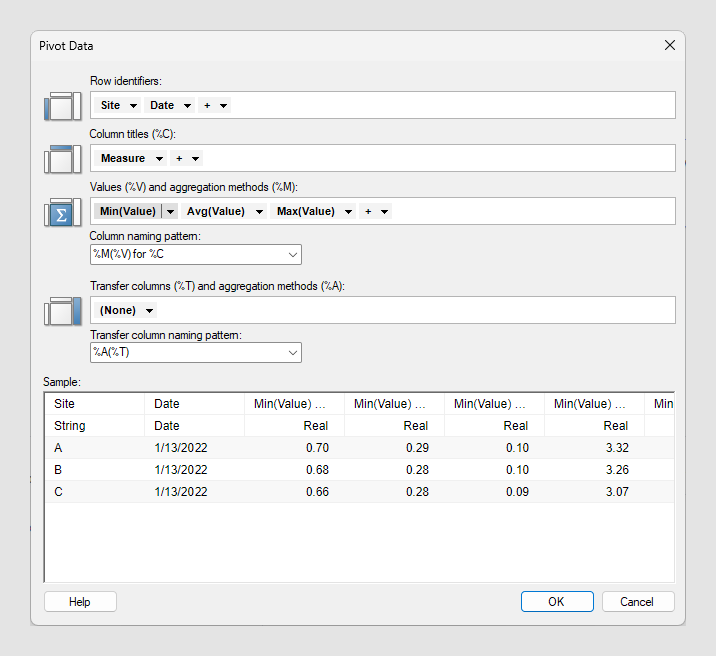
El orden de las nuevas columnas lo determina el resultado de la expresión de nombre, y aparece en orden alfabético.
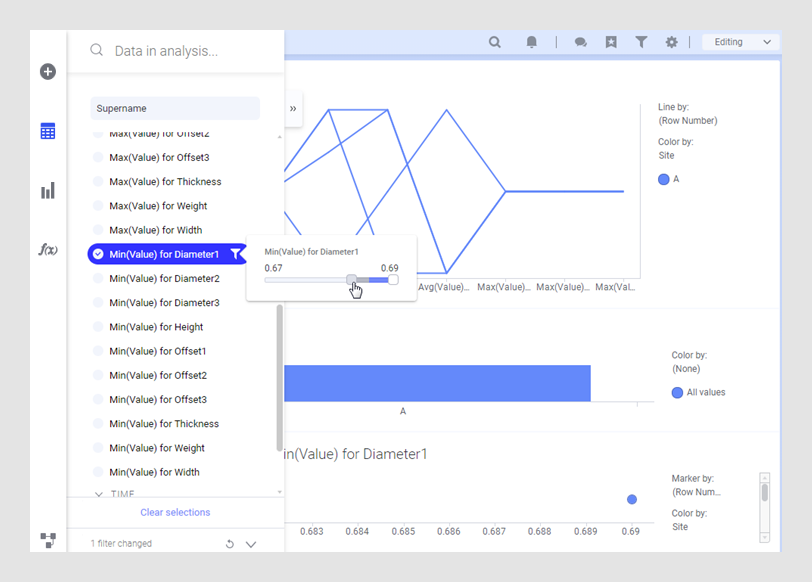
En el análisis, podemos comprobar que si el criterio más importante es que el diámetro no sea demasiado pequeño, la fábrica A debería suministrar las piezas a los clientes más exigentes.