Filtering in related data tables
When you have multiple data tables that are related to each other in your analysis, and the data tables do not include exactly the same values, you might want to handle filtering in the related data tables in different ways, depending on whether you are interested in the filtered values or the filtered out values in the columns that define the relation.
Before you begin
To help show the difference between the three options available, here is an example with two related data tables, DT1 and DT2. Both DT1 and DT2 contain some values that are not available in the other data table (pink and yellow), but they also contain common values (blue):
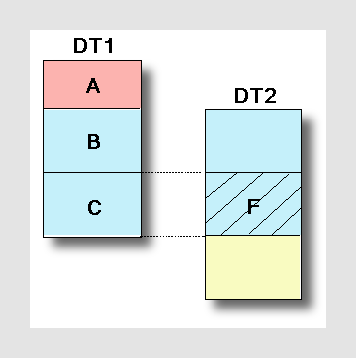
A = Values in DT1 that are not available in DT2.
B = Values in DT1 that are available in DT2, but have been filtered out.
C = Values in DT1 that are available in DT2 and included in the currently filtered values of DT2.
F = The filtered values (values remaining after filtering) in DT2.
When the filtering management for DT2 is specified (from the DT1 data table header) the different options will give the following results:Include filtered values only
The first option will make all values that are only present in DT1 disappear from the visualizations using DT1, because only the values that are currently filtered in DT2 will be included. Hence, this option keeps only those values that are present in both data tables (and have not been filtered out).
In the example above, this means that only the values in C will remain after filtering in DT2.
Exclude filtered out values
The second option will remove those values that have been filtered out from DT2 from all visualizations using DT1. Hence, this option keeps those values that are filtered in DT2 as well as the additional values from DT1.
In the example above, this means that A and C will remain after filtering in DT2.
Ignore filtering (default)
The third option is to ignore any filtering done in the related data table completely. This way, all values that are available in the current data table will remain available.
In the example above, this means that A, B and C will all remain after filtering in DT2.
About this task
Changing the settings for filtering in related data tables
Procedure
-
Click on the
Filtering in related data tables icon
 .
If something other than Ignore filtering is selected, the icon will be blue. If a relation no longer is valid, the icon will turn red.
.
If something other than Ignore filtering is selected, the icon will be blue. If a relation no longer is valid, the icon will turn red. -
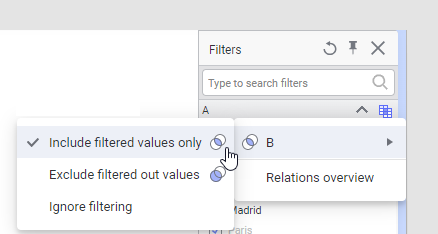
Select the data table for which you want to change how filtering
should affect the current data table, and select one of the options
Include filtered values only,
Exclude filtered out rows or
Ignore filtering.
Results
Example: The difference between the settings
In this example, two data tables, DT1 & DT2, both have a column called City which is used to create the relation. This column shares five values between both tables (Berlin, Calcutta, Johannesburg, Madrid, Tokyo), and each include one additional value that is different in the tables (Paris or Rome).
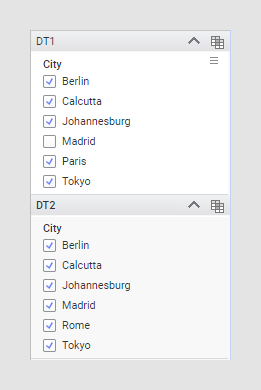
When Madrid is filtered out in DT1, nothing happens to the value in DT2.
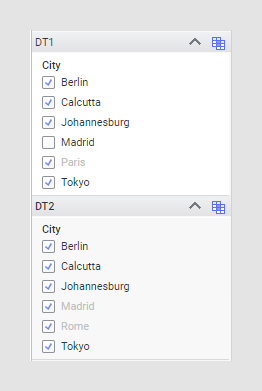
The filter setting is applied in both directions in these examples, but the directions do not affect each other. The result in DT1 is the same, regardless of how DT2 is configured on its end. If you want to include all values from DT1 (that is, to include Paris) but not all values from DT2 (to remove Rome), you would specify the Include filtered values only option on DT2, but not on DT1.
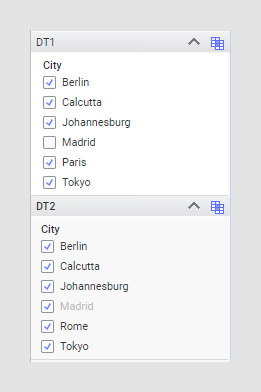
With this option, Madrid is greyed out in DT2, because it has actively been filtered out in DT1, but Paris and Rome remain in DT1 and DT2 respectively, because those values have not been filtered out from any of the data tables.