Connecting to a Hive Data Source on Hadoop
You can create a Hive data source natively on Hadoop, without using JDBC. It is much faster than connecting to Hive over JDBC, and it has support for running HiveQL queries on the HQL Execute operator.
Adding a Hive data source is very similar to adding a Hadoop data source. No extra JARs are needed to get Hive functionality.
Note: Configuring Kerberos on Hive is a similar process to configuring Kerberos on Hadoop, with the following additions.
- You must add hive.metastore.kerberos.principal.
- When you create the data source, you must add the following two parameters.
- stack.version=2.3.4.0-3485 - This parameter is essential for running jobs on the server. (If the value 2.3.4.0-3485 does not work, try 2.3.6.0-3796).
- hive.additional.parameter.disabled=true - This parameter is necessary for the stack.version parameter to be accepted. If this parameter is not set, the connection returns the error "stack.version cannot be changed at runtime".
Procedure
-
In the
Add Data Source dialog box, choose
Hadoop Hive from the
Data Source Type drop-down list.
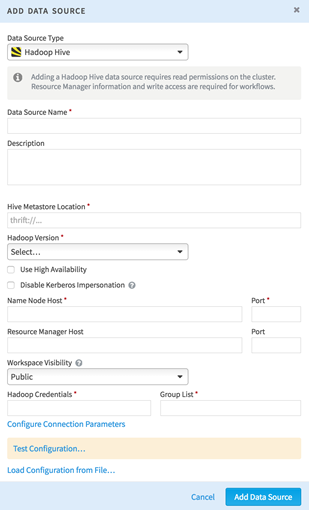
The only thing different from the section about Hadoop in Hadoop Data Sources is that the user needs to specify the Hive Metastore location. This location can be found in the file hive-site.xml on the cluster configuration and usually starts with thrift://.
Related tasks
Copyright © Cloud Software Group, Inc. All rights reserved.