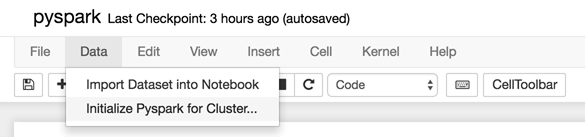
Initializing PySpark
You can initialize and use PySpark in your Jupyter Notebooks for Team Studio.
Prerequisites
-
Regenerate the PySpark context by clicking .
- Change the previously-generated code to the following:
os.environ['PYSPARK_SUBMIT_ARGS']= "--master yarn-client --num-executors 1 --executor-memory 1g --packages com.databricks:spark-csv_2.10:1.5.0,com.databricks:spark-avro_2.11:3.0.1 pyspark-shell"
If you do not have access to a Hadoop cluster, you can run your PySpark job in local mode. Before running PySpark in local mode, set the following configuration.
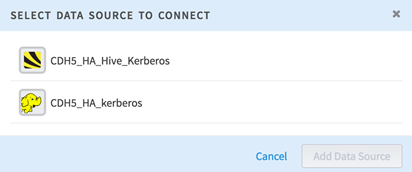
Procedure
Copyright © 2021. Cloud Software Group, Inc. All Rights Reserved.