Multivariate Statistical Process Control (MSPC) Technical Notes
- Batch Processes
Industrial productions can be divided into two main categories: those that continuously lead to the production of the end product, and those yielding production in a discrete way. The latter is known as batch processes.
Batch processes are of considerable importance in making products with the desired specifications and standards in many sectors of the industry. Examples of such products include polymers, paint, fertilizers, pharmaceuticals, cement, petroleum products, biochemicals, perfume, and semiconductors. In batch operations, a specified recipe of reactants are charged into a tank and processed for a certain period of time, during which hundreds of measurements are taken for dozens of process variables (such as pressure, temperature, feed-rates, etc.) in regular time intervals (typically, hundreds). During a batch run, the reactants remain in a controlled environment with conditions changing subject to fairly well defined trajectories (i.e., the trend in the evolution of the process variables). At the end of a batch process, the product is either sent to another phase involving another batch or simply discharged. The outcome of a batch (or a sequence of batches) is the end product that the batch process is meant to produce.
The objectives of batch processing are related to profitability achieved by reducing product variability as well as increasing quality. From a quality point of view, batch processes can be divided into normal and abnormal batches. Generally speaking, a normal batch leads to a product with the desired specifications and standards. This is in contrast to abnormal batch runs where the end product is expected to have a poor quality. Another reason for batch monitoring is related to regulatory and safety purposes. Often industrial productions are required to keep full track (i.e., history) of the batch process for presentation of evidence on good quality control practice.
Statistical Process Control (SPC) is a method that can provide engineers with fault detection tools in operating conditions that may be present in batch processing of industrial production lines. This multi-purpose tracking tool provides engineers with early warning and fault detection systems when the conditions of the batch process, i.e., the conditions under which the end product is developing, does not meet the required specifications and standards. Production under abnormal conditions may lead to poor quality and even faulty products. It has been estimated that such deviations from normality cost the U.S. petrochemical industry $20 billion per year. SPC can provide engineers with valuable information that could help them to better manage and control such situations.
- Batch Trajectories
SPC assesses the evolution of a batch by monitoring the trajectory of the process variables and their evolution for the duration of the batch (see Figure 1). Variables of an abnormal batch usually follow trajectories that are often substantially different from those demonstrated by normal batches, either for part or full duration of the batch run. If such abnormalities are detected early enough, engineers can take corrective actions that can ensure the quality of the end product.
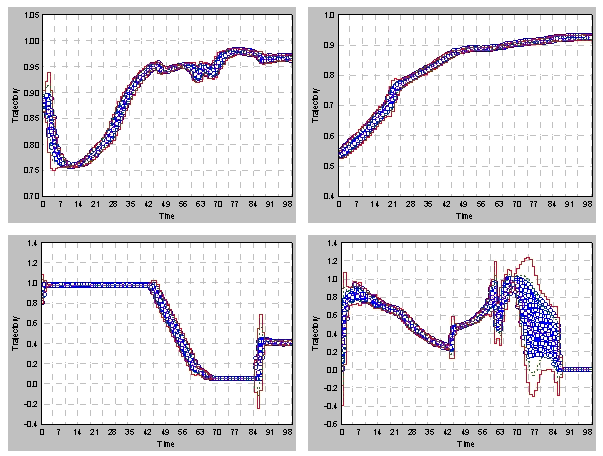
Figure 1. An example of four different process variable trajectories measured over 100 time intervals for a total of 30 normal batches. SPC uses the trend in these trajectories for monitoring of new batches during their evolution in time. Note that, although each variable follows a similar trajectory, there is also some degree of variation from one batch to another.
No two batches are the same. Even identical batches exhibit some variability from one batch to another, mainly due to initial starting conditions, quality of the reactants, and the control environment that is inevitably subject to uncontrollable and random effects. As a result, while the process variables generally follow trajectories very similar in trend, the path of each variable may vary, more or less, from one batch to another. If a variable is found to have a substantially different trajectory from the normal trend, this could be an indication of a growing abnormality within the process, which might necessitate corrective action to save the quality of the end product.
From the above, it is clear that in order to monitor the progress of a new batch, we need to have some reference data taken from successful (i.e., normal) batch runs. Such data is called historic data or simply batch data. By comparing the trajectories of the process variables of a new batch with those taken from historic data, SPC establishes a monitoring chart system that can be effectively used for quality control.
- Batch Data
Again, let's go back to the issue of industrial batch production. Recall that while the batch is in progress, we constantly need to monitor the conditions under which the batch product develops. To this end, we place sensors at different places of the mixture to measure quantities of interest on regular time intervals and as frequently as needed (see Figure 2).
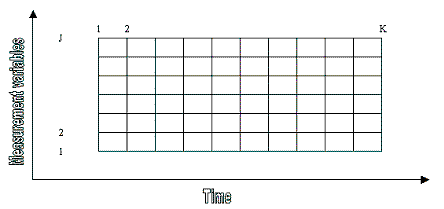
Figure 2. This figure shows data for one batch. There are J measurements variables to be monitored, and the measurements are taken on K regular time intervals covering the entire batch run.
Note: no two batches are identical as conditions may vary from one batch to another, but as long as these variations are within limits of tolerance, the quality of the product will remain acceptable. To consider these variations we, therefore, need to base our monitoring of the current batch on many past normal batches (rather than just one) for which we know the end quality was within acceptable standards. Data taken from multiple past batches is usually combined in the form of a 3-dimensional IxJxK matrix.
Figure 3. A schematic of data obtained from multiple batches. It is a 3-dimensional IxJxK matrix. Such batches are collected from previously successful runs and are used for future monitoring.
- Multivariate Statistical Process Control (MSPC)
To summarize, SPC assesses the quality of a batch by monitoring the trajectory of the process variables. Beyond the natural variations that these variables can display during the evolution of a batch, if any substantial deviation is detected, it might indicate the formation of an abnormal batch and possibly a faulty product.
However, SPC has a number of shortcomings that make it less suitable for tackling modern quality control problems. For instance, with online computers being so available, massive amounts of data can be obtained from measurements of various process variables during a single batch. For example, measurements for a single batch may contain hundreds of readings for dozens of process variables. This simply means that, for each batch, we have to monitor a substantially large number of quality charts. Monitoring so many variables is tedious, but this is not the only weakness from which traditional SPC methods suffer.
Since SPC monitors the process variables separately, it ignores the substantial degree of correlation that often is present among these variables. The existence of correlation among the process variables makes the SPC monitoring system simply inadequate, rendering model interpretation and diagnosis difficult. Only through the collective examination of the process variables can we extract adequate information on the variation of the batch as a whole.
Another disadvantage of traditional SPC is related to the signal to noise ratio. When important events occur that may affect the process, one way or another the variable signals often have a low signal to noise ratio, which makes detecting such changes difficult. The collective observation of the process variables can extract this information more efficiently by reducing the level of noise that may act as a mask in screening important process events.
The solution to the above problems is found in the application of Multivariate Statistical Process Control (MSPC). MSPC uses the method of Principal Component Analysis (PCA) and Partial Least Squares (PLS) to overcome the above difficulties in a natural and efficient way by eliminating the correlation between the measurement variables and analyzing all measurement variables collectively so the monitoring process can be accomplished with the aid of only a few illustrative charts (instead of as many charts as the number of variables, which may run into hundreds), such as the Hotelling T2 and SPE (Squared Prediction Error). T2 is a measure of how close the current operating conditions are to the normal conditions (i.e., normal conditions as determined from historic data). SPE measures deviations of the current batch from normality. Large deviations might be an indication of faulty batches.
Although PCA and PLS are general modeling tools, they are particularly suited for tackling problems with a large number of variables. The natural ability to combat the curse of dimensionality (Bishop 1995) is inherent in these models since they base the representation of the original data set on a number of coordinates (i.e., principal components) lesser in dimension than the number of variables. Given this fact, such methods are particularly suited for the application of MSPC to batch processing. The reason is, although the number of variables in a batch may run into hundreds, the true underlying factors that drive the trend are actually fewer in number. Based on these new variables, called scores and loadings, MSPC can achieve an effective monitoring system that uses only a handful of monitoring charts derived from the new variables.
The application of PCA to MSPC involves building a PCA model from batches that are fault free (i.e., normal batches). Then, the model is used as a template for assessing new batches. In other words, we build a PCA model that we subsequently use to predict whether a new batch is normal. The detection of abnormal batches does not necessarily imply faulty end products. Instead, it serves as a monitoring system that can raise the alarm when corrective actions may be needed.
In MSPC, we often define a quality variable that simply indicates the acceptability of the end product. Using this variable, we construct a PLS model that can be used for predicting the value of the quality variable during the evolution of a batch, i.e., how good the end product is going to be. This provides a great advantage in monitoring batches and quality control since quality (or related variables) are hard to measure or simply can't be measured while the batch production is in progress.
- Data Unfolding
Although PCA and PLS methods are extremely useful for tackling MSPC problems, they are strictly applicable, as many statistical tools, to 2-dimensional problems. Thus, before analyzing 3-dimensional batch data using these methods, we first should transform them into a more suitable structure. This can be achieved using the method of unfolding, a technique that reduces 3-dimensional batch data to one with only 2-dimensions. Using the 2-dimensional matrix, we can then build PCA and PLS models for batch processing. The question is how to unfold a batch data set while retaining all the process information that comes with it.
- Time-Wise Data Unfolding
For process monitoring, the most meaningful way to unfold batch data is to rearrange the vertical slices as shown in Figure 4. The result is an I xJK matrix X, where I is the number of batches, J is the number of measurement variables, and K is the number of measurements taken for each variable. See P. Nomikos and John F. MacGregor for more details.

Figure 4. The process of the unfolding of a 3-dimensional IxJxK batch data set to a IxJK 2-dimensional matrix in the direction of time. This is known as time-wise unfolding.
Batch processes are by nature time based. It is not only the trajectory of the batch variables that vary in time but also the correlation among them. Therefore, any monitoring system should implicitly include this dynamic time dependency. That is why time-wise unfolding is particularly suited for online batch monitoring since it preserves the time dimension that is inherent in the data set. As a result, PCA and PLS models built on time-wise unfolding are particularly sensitive, not only to the quality of a batch as a whole but also to the time dependent conditions under which the batch was evolved. Thus, they are better suited for online monitoring.
- Batch-Wise Data Unfolding
Another method for restructuring batch data is to unfold the 3-dimensional matrix in the direction of the batches. This is known as batch-wise unfolding. In this technique, the unfolding of the IxJxK 3-dimensional data yields a 2-dimensional matrix with IxJ rows and K columns. See Wold et. al. for more details.
As discussed previously, time-wise unfolding is more sensitive to detecting variations and deviations from normality in process monitoring. For a comparison of this method with time-wise unfolding, see Salvador Garcia's Batch Process Analysis using MPCA/MPLS, A Comparison Study.
- MPCA and MPLS
As discussed in section 6, batch data comes in the form of a 3-dimensional matrix IxJxK. Thus, it is not possible to apply PCA or PLS directly to batch data without some restructuring. A Multi-way PCA (MPCA) or Multi-way PLS (MPLS) unfolds the 3-dimensional batch to a 2-dimensional data set (see section 5, 6, and 7), followed by an application of a regular PCA or PLS to build a model that can define a region of desirable process operations for monitoring and assessing future batches. Depending on the method used for data unfolding, we refer to MPCA and MPLS as Time-wise MPCA (TMPCA) and Time-wise MPLS (TMPLS) should the unfolding be carried out in the direction of time. Similarly we call MPLS models built from batch-wise unfolded data as Batch-wise MPLS (BMPLS).

Figure 5. TMPCA for time-wise unfolded data with I batches, J variables, and K number of measurements. The unfolded matrix X has I rows and KxJ columns.

Figure 6. BMPCA for batch-wise unfolded data with I batches, J variables, and K number of measurements. The unfolded matrix X has IxK rows and J columns.
In TMPCA, the 2-dimensional data X is decomposed into a new set of variables known as scores and loading factors (see PCA and PLS Technical Notes).

where C is the number of principal components. Usually a few number of principal components are needed to model the matrix X especially when the process variables are strongly correlated. Thus, using a relatively small set of principal components, you can extract most of the variability in the matrix X. By building reference models from past normal batches, you can detect similarities and deviations from normality. As can be seen from Figure 5, each score vector t (rows of the T matrix) belongs to a single batch and measures the overall variability of this batch with respect to the rest. This is contrast to the loading factor p (rows of the PT matrix), which measures the variability of a batch in the direction of time. In effect, the p vector contains records of the variability of the process variables. Thus, while we can use the score vector t for assessing the overall quality of a batch, the loading vector p provides us with a history track of how a particular batch evolved in time. For more details on scores and loading factors, see PCA and PLS Technical Notes.
The number of principal components of a PCA (and PLS) model is the nuisance parameter, which is not known a priori. STATISTICA uses the method of cross-validation to estimate the optimal number of the principal components.
The t-scores can be used to track the projection of the batch history onto the plane defined by the principal components. They verify the overall quality of a batch. To track the state of evolution of a batch at a particular instant, you should use the SPE (Q) measure. If the t-scores of a batch are close to the point of origin and its residuals are small with respect to the reference model, we can assume that the batch is normal.
We can use scatterplots of the p-loading factors to analyze how the variables contribute to a particular batch. If two variables appear close together in the scatterplot, it indicates that the two variables influence the batch in the same way. Furthermore, it also indicates that the two variables are positively corrected (see PCA and PLS Technical Notes for more information). Variables lying on opposite sides of a loading factor scatterplot imply negatively correlated variables.
As stated before, in MPCA. we aim to build a PC model based on historic and normal data taken from good batches. Using this model, we can then predict future batch observations and, hence, judge its quality by calculating the measures discussed here (see PCA and PLS Technical Notes). To predict a new observation xnew (KxJ) pertaining to a new batch, we first scale (preprocess) the data to
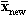 (KxJ), time-wise unfold it (1 xJK) and finally apply the equation:
(KxJ), time-wise unfold it (1 xJK) and finally apply the equation: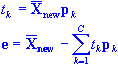
The above discussions can also be applied to batch-wise unfolding. The difference is a new observation
unfolded to a KxJ matrix instead of 1 xJK.Unlike MPCA, MPLS methods work on data that can be divided into cause and effect. In effect, MPLS is a predictive model that relates a set of dependent variables given a set of predictors. The predictor variables are the cause, and the dependent variables are the effects. Given the above, MPLS is mostly used for online monitoring and predictions of quality variables by mapping their relationship to the process variables. Thus, by taking measurements of the process (predictor) variables, MPLS can in effect predict the quality variables. A batch with low quality variables is likely to develop into an abnormal batch and possibly yield a poor quality product. For more details on the application of PLS, see PCA and PLS Technical Notes.
It should be noted that for BMPLS models, the time variable is taken to be the dependent variable. Thus, the time dependency is also used as the predicted variable. For TMPLS models, however, one or more dependent variable must be selected explicitly, and the selection is treated as quality variables, measuring various attributes of the end product.