Example 1: Discriminant-Based Univariate Splits for Categorical Predictors
This example illustrates the use of classification trees for pattern recognition. The data for the analysis were generated in a manner similar to the way that a faulty calculator would display numerals on a digital display (for a description of how these data are generated, see Breiman et. al., 1984). The numerals from one through nine and zero that were entered on the keypad of a calculator formed the observed classes on the dependent variable Digit. There were 7 categorical predictors, Var1 through Var7. The levels on these categorical predictors (0 = absent; 1 = present) correspond to whether or not each of the 7 lines (3 horizontal and 4 vertical) on the digital display were illuminated when the numeral was entered on the calculator. The predictor variable to line correspondence is Var1 - top horizontal, Var2 - upper left vertical, Var3 - upper right vertical, Var4 - middle horizontal, Var5 - lower left vertical, Var6 - lower right vertical, and Var7 - bottom horizontal. The first 10 cases of the data set are shown below. The complete data set containing a total of 500 cases is available in the example data file Digit.sta. Open this data file via the File - Open Examples menu; it is in the Datasets folder.
Specifying the analysis
With two exceptions (the specifications for Priors and V-fold for cross-validation), we will use the default analysis options in the Classification Trees module. Select Classification Trees from the Statistics - Multivariate Exploratory Techniques menu to display the Classification Trees Startup Panel. On the Quick tab, select the Variables button to display the standard variable selection dialog. Here, select Digit as the Dependent variable,Var1 through Var7 as the Categorical preds., and then click the OK button. Next, click on the Methods tab and select the Equal option button under Prior probabilities. Then, click on the Sampling options tab and enter 10 in the V-fold cross-validation, v value field. Finally, click the OK button on the Classification Trees Startup Panel to first briefly display the Parameter Estimation dialog (from which you can monitor the progress of the classification tree computations) and then the Classification Trees Results dialog when the computations are completed.
Reviewing the results
Click on the Tree structure tab and then click the Tree sequence button to display the spreadsheet shown below.
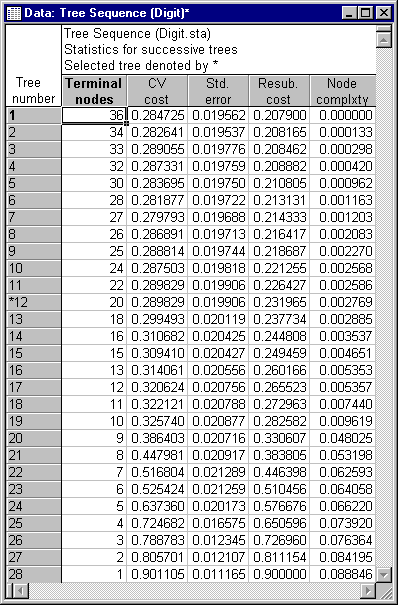
As the spreadsheet shows, the selected tree (Tree number 12, denoted with a *) has a CV cost of .2898 with a Standard error of .0199, costs for the learning sample, labeled as Resub (Resubstitution) cost, of .2320 and a "smoothed" Node complexity value of .0028. The minimum CV cost tree (Tree number 7) has a CV cost of .27979 with a Standard error of .01968, and the selected tree is the simplest tree with a CV cost not exceeding .27979 + .01968 = .29947, using the default 1.0 Standard error rule (see the Stopping options tab).
Click the Misclassification matrix button on the Predicted classes tab to display the spreadsheet shown below.

This spreadsheet shows the number of cases in each observed class misclassified as each of the other nine classes. It is interesting that the most frequent misclassification is of the numeral 8 as the numeral 9, and of course, the depiction of these two numerals on a digital display differs by only one (the lower-left) vertical line. Note also that 8's are never misclassified as 1's 2's, or 7's, numerals from which 8's differ by several lines.
Now click the Predictor importance button on the Tree structure tab to display a spreadsheet that displays the importance ranking on a 0 - 100 scale for each predictor variable in the analysis.
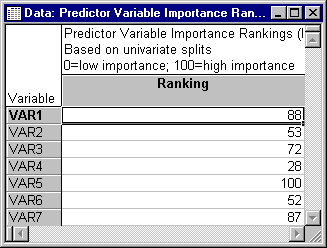
As the rankings show, Var5, corresponding to the lower-left vertical line in the digital display, is the most important predictor variable, and as noted above, it is the lower-left line in the digital display that distinguishes the numeral 8 from the numeral 9. These same results can be displayed graphically by clicking the Importance plot button on the Tree structure tab to produce a bar chart of the rankings for each predictor variable.

Now, on the Cross-validation tab, enter 10 in the v-fold for GCV field and then click the Perform global CV button to display the Global cross-validation dialog. Click the Global CV misclassification matrix button, which will first display the Global CV Parameter Estimation dialog from which you can monitor the progress of the global cross-validation computations. Upon completion of the cross-validation procedure, the Global CV Sample Misclassification Matrix spreadsheet is displayed.

The Global CV cost and its standard deviation (s.d. CV cost) are fairly similar to the CV cost and its Standard error for the selected tree (Tree number 12, see above), indicating that the "automatic" tree selection procedure fairly consistently selects a tree with close to the minimum estimated costs.
See also, Classification Trees Index.