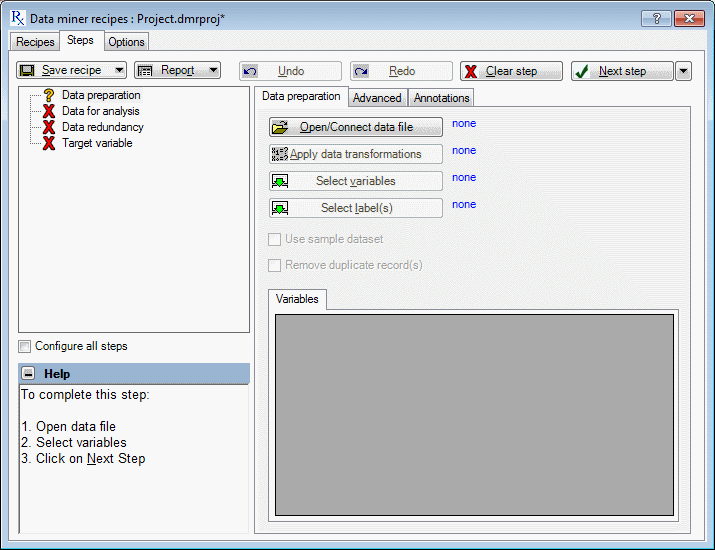
Steps Tab
The Steps tab of Data Miner Recipes dialog box is used to create new projects or edit existing ones. The upper-left pane, the Step-nodes pane, consists of options and user configurations for creating data mining models, and the right pane contains tabs specific to the step node in use. There is an information panel in the lower-left corner of the dialog box, which displays useful instructions regarding the current step and how to proceed to the next step.
The information in this topic pertains to the Step-nodes panel and buttons (Save recipe, Report, Next step) that are always available on the Steps tab regardless of which tab is selected. For topics on tab-related options, see Data Preparation - Data Preparation tab, Data Preparation - Advanced tab and Data Miner - Annotations tab.
Step-nodes
 ,
,
 or
or
 .
.
(ready state) to
(completed state). The change is made if the step is complete.
The Data Miner Recipes steps are arranged in a logical and sequential order. This ensures that all the information required for successful completion of any given step is in place when the step is started. For example, in any model building task, data are used as examples for the model to learn the underlying process relating the input and target variables. Therefore, you can only start the Target variables step when you have successfully completed the Data preparation and Data for analysis steps. Below is a summary list of the Data Miner Recipe steps and the states in which they can exist. Note that not all steps have three states.
If required, the initial state of a step is
(with the exception of the
Data preparation
step which is
). You can change the state from
to by clicking the
Next step
button. If the step is complete, the status of the step is changed from
to
and the following step is changed from
to
. If you click the
Next step
button when the step is not complete, a message is displayed prompting you to complete the step.