Contents
- Types of Container Connections
- Specifying Container Connections
- Syntax for Expressing Container Connections
- Container Connection Predicate Filters
- How the Server Makes Container Connections
- Using Container Connections to Share a Stream
- Container Start Order
- Schema Matching for Container Connections
- Dynamic Container Connections
- Synchronous Container Connections
- Remote Container Connection Parameters
- Related Topics
This topic discusses how to establish and maintain connections between streams in different application modules running in different containers. See StreamBase Container Overview for an introduction to StreamBase containers.
StreamBase supports stream-to-stream container connections and CSV file container connections.
In this configuration, you set up an EventFlow module's input stream in one container to receive tuples from an output stream of another module in another container. Both containers must be running in the same JVM engine.
Stream-to-stream connections can be of two types:
-
Asynchronous. In the default form of stream-to-stream container connection, the flow of tuples is set to run asynchronously, with a queue automatically set up by StreamBase to manage the flow through the connection.
-
Synchronous. You can optionally specify low latency, direct connections between container streams without the benefit of queue management. This option offers a possible latency improvement for certain circumstances. In general, asynchronous connections improve throughput, and synchronous connections improve latency. See Synchronous Container Connections.
Stream-to-stream connections can also be made from an output stream to an input stream within the same container, where the destination and source container name is the same. Intra-container connections must be Asynchronous, and the same access restrictions apply: that is, streams you wish to connect to or from in sub-modules must be marked as Always exposed in EventFlow modules.
In the following diagram, we add two reader modules (B and C) to a running EventFlow engine that was already hosting module A:
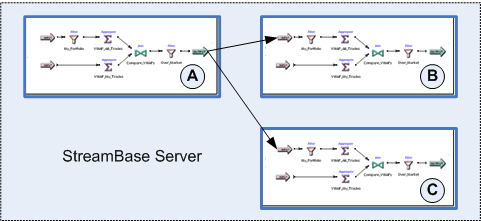
|
In the next diagram, we add two writer modules (B and C) to a running engine that was already hosting module A.
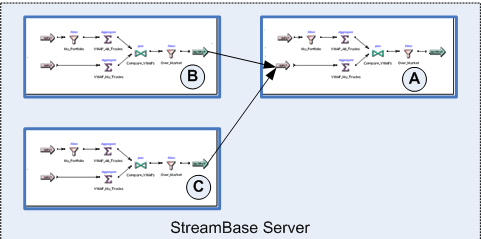
|
Notes
-
In the diagrams above, the EventFlow modules are shown for simplicity as having the same components. This is for illustration only; modules in containers are not required to have the same set of components. However, the streams used in container connections between modules must have the same schema.
-
When removing containers and modules from a running server process, try to remove them in the reverse order that they were added.
In this configuration, you connect a container's output stream to a URI that specifies the absolute path to a CSV file. All tuples sent on this port are then written to the specified file. You can also connect a CSV file's URI to an input stream; in this case, the input stream is read from the CSV file. See Connecting Container Streams To a CSV File.
StreamBase provides several methods of specifying a connection between containers. Some methods are interactive (for testing and management of containers on running servers), while some methods specify that the connection is made immediately when the enclosing server starts (or when the enclosing container on that server starts). However, all methods are equally effective. Use the method that works best for your application and its stage of development or deployment, but only specify one method per connection for a given run of StreamBase Server. For example, do not specify a connection between containers A and B in both the Run Configuration dialog and in the Advanced tab of a stream.
Each container connection must be specified only once for each connected pair of containers. Do not specify a container connection in the output stream of the sending container and again in the input stream of the receiving container. You can specify the connection in either the sending or receiving container to the same effect. Do not specify the container connection in both places.
The methods of specifying container connections are:
-
In a server configuration file (deprecated)
-
From the command line, using the sbadmin addContainer or sbadmin modifyContainer command to communicate with a running server.
-
Using StreamBase Manager, with commands in the context menu for servers and containers.
In StreamBase Studio, in the Advanced tab of the Properties view for either an input stream or output stream, use the Container connection field to specify a StreamBase expression that resolves to the qualified name of a stream in another container. A qualified stream name follows this syntax:
container-name.stream-name
When using the Advanced tab for an output stream, you are already in the source stream, so you only need to specify the qualified name of the destination stream. Similarly, in the Advanced tab for an input stream, you are in the destination stream, and only need to specify the qualified name of the source stream.
You must express the container-qualified stream name as a StreamBase expression. To express a known container and stream name, enclose the qualified name in single or double quotes to render the name as an expression.
The container connection expression can optionally include variables, constants, and expression language functions that resolve to a qualified container and stream name. However, remember that the container connection is established at container start time, so your container connection expression cannot reference tuple field names or contents, since no tuples have yet passed through at container start time. For the same reason, the container connection expression cannot resolve any value of dynamic variables, including the default value.
Specify each container connection only once, in either the sending or the receiving stream. Do not specify the container connection in both places.
When you use the Advanced tab to specify a container connection, the connection is stored as part of the EventFlow XML definition of the module, and thus travels with the module. As long as the container names are the same, the same connection will be made whether the module is run in Studio or at the command prompt with the sbd command.
The icons for input and output streams show an overlay decoration on their upper back corner to indicate that this stream initiates a container connection to another stream by means of the Advanced tab's Container connection field.
|
|
Streams on the other side of the connection in the receiving container are not decorated. Decorations are not applied for connections specified to start at runtime in a deployment file, in a Studio launch configuration, in StreamBase Manager, or from the command line with the sbadmin command.
There are restrictions on the order in which you start connected containers, both at the command line and in Studio. See Container Start Order for details.
When you use the sbadmin addContainer or sbadmin modifyContainer commands, either at the command prompt or in a script, you can specify a container connection at the same time. The syntax is:
sbadmin addContainer container-name application.[sbapp|ssql|sbar] connection1 connection2 ...
The following example cascades tuples through three applications, each running in its own container, A, B, and C:
sbadmin addContainer A preprocess.sbapp sbadmin addContainer B mainprocess.sbapp B.InputMain=A.OutputPre sbadmin addContainer C postprocess.sbapp C.InputPost=B.OutputMain
A tuple enqueued into container A has the following itinerary:
-
Processed by
preprocess.sbappin container A. -
Exits container A through output stream
OutputPre. -
Queued to container B's input stream
InputMain. -
Processed by
mainprocess.sbappin container B. -
Exits container B through output stream
OutputMain. -
Queued to container C's input stream
InputPost. -
Processed by
postprocess.sbappin container C.
The syntax for expressing container connections with sbadmin is always in the order destination=source
dest-container.instream=source-container.outstream
See the sbadmin(1) reference page for more on the sbadmin command and its options.
When using StreamBase Manager to monitor a running application (either in the SB Manager perspective in Studio or when run as a standalone utility), you can use it to:
-
Add a container and optional container connection to a running server.
-
Remove a container from a running server.
-
Pause, resume, or shut down the application running in a container on a running server.
To do so, select a server name in the Servers view on the left, and open the tree to select an entry in the Containers tree. Right-click and select options from the context menu, as described in Context Menu Actions for Servers and Context Menu Actions for Containers.
In releases before 7.0, container connections could be specified in the
<runtime> element of server configuration files,
using a syntax similar to the current deployment file syntax. Such configuration
files are still supported for backward compatibility. However, TIBCO strongly
recommends migrating the <runtime> portion of
existing server configuration files to deployment files.
To specify a container connection, you must specify both source and destination stream names, and you must qualify the stream names with their container names. The following syntax is explicitly required when using the sbadmin command, and is expressed in other ways with the other container connection methods:
dest-container.instream=source-container.outstream
If the incoming or outgoing stream is in a module called by a top-level application in a container, then you must specify the module name as well:
dest-container.moduleA.instream=source-container.outstreamProperty Data Type Determines Generated Control dest-container.instream=source-container.moduleB.outstream dest-container.moduleA.instream=source-container.moduleB.outstream
If the source container is running on a remote StreamBase Server (or if the server is running on a different port on the same host), specify a full StreamBase URI enclosed in parentheses:
dest-container.instream=(sb://remotesbhost:9955/app3.outstream) dest-container.instream=(sb://localhost:10001/default.outstream6)
You can use a StreamBase URI for the receiving container, as well. For example:
(sb://remotehost:8855/app2.instream)=source-container.outstream (sb://localhost:10001/default.instream4)=source-containter.outstream
You can use the same syntax for remote hosts in both the dest and source attributes in a
deployment file:
<deploy ...>
<runtime>
<application file="primary.sbapp" container="A" />
<application file="secondary.sbapp" container="B" />
<container-connections>
<container-connection dest="B.InputStream1"
source="(sb://remotesbhost:9955/app3.outstream)"/>
<container-connection dest="B.InputStream2"
source="A.OutputStream2"/>
</container-connections>
</runtime>
</deploy>
The remote host syntax also works in the Advanced tab of input and output streams, but not when using the Run Configuration dialog in Studio or StreamBase Manager.
In three of the ways to define a container connection, you can specify a predicate expression filter to limit the tuples that cross to the destination container. The expression to enter must resolve to true or false, and should match against one or more fields in the schema of the connection's stream. You can specify a container connection predicate filter in:
-
With the
--where "argument to the sbadmin modifyContainer command (but not using the addContainer command).expression" -
With the
where="attribute of theexpression"<container-connection>element in StreamBase deployment files. -
With the Container connection filter expression field in the Advanced tab of the Properties views for input streams and output streams.
There is no mechanism to specify a predicate filter for container connections specified in Studio's Launch Configuration dialog, in StreamBase Manager, or in the server configuration file.
For example, a deployment file could have a <container-connection> element like the following:
<container-connections>
<container-connection dest="holder2.input1"
source="default.output3" where="tradeID % 2 == 0"/>
</container-connections>
When using sbadmin:
sbadmin modifyContainer holder2.input=default.output3 --where "tradeID % 2 == 0"
When using the filter expression field on the Advanced tab in the Properties view of
an Input Stream or Output Stream, enter only the expression: tradeID % 2 == 0
With a valid container connection specified, when the module containing the connection starts, the hosting server locates the specified container and stream, and makes the connection. As the application runs, tuples exiting one container's output stream are consumed by the specified input stream in the other container.
The schema of both sides of a container connection must match, as described in Schema Matching for Container Connections.
If the hosting server cannot make the container connection for any reason, it stops and writes an error message to the console. The likely reason for a failure to make a container connection is a failure to locate either the specified container or the specified input stream in the module running in that container. In this case, check the spelling of your container connection specification.
When a container is removed, the input or output to any dependent container disappears. The dependent container continues to function, but its input or output is removed.
Stream-to-stream container connections are not limited to one container on each side of the connection. That is, you can configure:
-
Two or more containers to share the same input stream.
-
Two or more containers to share the same output stream.
When input and output streams are shared, the streams are still owned by the original container. This means that any input or output to the shared stream ultimately needs to go through the original container. When tuples are passed between asynchronous container connections, they are passed using the same queuing mechanism used between parallel modules. This means that the tuple is queued for the other containers. When the tuple is queued, the original container must wait for the tuple to be pushed onto the queue, but will not be blocked by the processing of the tuple (which is done in another thread). Because of the queuing architecture, there is no guarantee of the order of tuples when they are shared between multiple containers.
In the following example, containers A and B share the stream A.InputStream1. When a tuple is enqueued into A.InputStream1 the tuple is first passed to all containers that
share that stream (in this case, container B) and then it is processed to completion
by itself.
sbadmin addContainer A app.sbapp sbadmin addContainer B app.sbapp B.InputStream1=A.InputStream1
Nothing prevents you from enqueuing directly to an input stream in container B while that stream also receives input from an upstream connection from container A. Because upstream tuples are queued, any input directly into container B is randomly interleaved with input from container A.
The use of container connections imposes some restrictions on the startup order of containers, especially when making connections with sbadmin commands. The general rule is: the container that holds the receiving end of a container connection must be running when attempting to connect the containers.
When you run a deployment file, it starts all containers first, then tries to make any specified container connections. Because all containers are running, all container connections succeed. Thus, container start order issues do not arise when using deployment files.
However, it is possible to specify a container connection as part of an sbadmin addContainer command. In this case, the receiving end of the container connection must be started first.
You may need to control the start order of an application's containers. For example, one container might need to contact an external market data feed or an external adapter before other containers can start. Container start order might be significant for ordering the start of Java operators.
You can control container start order in the following ways:
- Launch Configuration dialog
-
In Studio, in the Containers tab of the launch configuration dialog, use the and buttons to arrange your containers in the desired start order, top to bottom.
- Using sbadmin commands
-
Containers specified with sbadmin commands at the command prompt or in scripts are started in the order of the commands, and in the order of arguments to any one sbadmin command.
In the following example for UNIX, the sbd server is started without specifying a top-level application, and containers are added in A-B-C sequence:
sbd -b sbadmin addContainer A preprocess.sbapp sbadmin addContainer B mainprocess.sbapp B.InputMain=A.OutputPre sbadmin addContainer C postprocess.sbapp C.InputPost=B.OutputMain
Because of the way Windows launches processes, you must specify at least one argument when specifying sbd without an application argument. You can specify a port number for this purpose, even if you only re-specify the default port. Run the same commands as above at a StreamBase Command Prompt on Windows by starting with a command like the following:
sbd -p 10000 sbadmin addContainer A preprocess.sbapp ...
You can emulate the behavior of deployment files by starting all containers first, then making container connections with the
modifyContainersubcommand:sbd -b sbadmin addContainer A preprocess.sbapp sbadmin addContainer B mainprocess.sbapp sbadmin addContainer C postprocess.sbapp sbadmin modifyContainer B addConnection B.InputMain=A.OutputPre sbadmin modifyContainer C addConnection C.InputPost=B.OutputMain
StreamBase Studio imposes additional restrictions on running or debugging modules with container connections:
-
Studio always starts its primary application in a container named
default. -
You cannot use the launch configuration's Containers tab to specify a container connection for streams in the primary application. However, you can instead:
-
Use the launch configuration Containers tab to specify the same connection from the point of view of the other container in the connection.
-
Specify the same connection in the Advanced tab of an input or output stream in the primary application.
-
Even with these restrictions, it is possible to use Studio to run or debug a pair of modules with a container connection between them, as long as the following conditions are met:
-
Use the Containers tab of the Run Configuration dialog to load your secondary module into a separate container, and give the separate container a name.
-
Specify the container connection in one of two ways, but not both:
-
In the Advanced tab of the Properties view of a stream in either the primary or secondary module, OR
-
In the Run Configuration dialog, for the secondary module only
-
-
If necessary for your container connection, use the and buttons in the Containers tab to make sure the container that holds the receiving end of the connection starts first.
The schemas of the outgoing and incoming streams in a container connection must exactly match, or be coercible to match. That is, the connected streams must share exactly the same field names, field data types, and field positions between the two streams. If the two streams share the same field types, sizes, and names, but are in different order, StreamBase cannot map the streams together.
Tip
To make sure your input and output stream schemas exactly match, use a named schema in one module and use the imported schemas feature of the Definitions tab in the EventFlow Editor of the other module. Assign the same named schema to both streams.
Use sbadmin modifyContainer to dynamically add or remove a container connection from an existing container while StreamBase Server is running:
sbadmin modifyContainer container-name [addConnection | removeConnection]
connection-expression1 connection-expression2 ...
where each container-expression has the
syntax destination=source as in this example:
containerA.instream1=containerB.module1.outstream1
By default, connections between containers are set up to run asynchronously, with a queue to manage the flow of tuples through the connection.
StreamBase also supports synchronous container connections, which are low latency, direct connections between containers, and do not have queue management.
Specify a synchronous container connection with the sbadmin command by using := (colon-equals) instead of = (equals)
in your container connection assignment statement. For example:
sbadmin addContainer A app1.sbapp sbadmin addContainer B app2.sbapp sbadmin modifyContainer addConnection B.incoming:=A.outgoing
You can also specify a synchronous container connection in a deployment file by
adding the synchronicity attribute to the <container-connection> element that specifies your connection:
...
<container-connection dest="B.InputStream1"
source="A.OutputStream1"
synchronicity="SYNCHRONOUS" />
...
Caution
Synchronous container connections do not automatically improve the speed of your application. It is even possible to inadvertently degrade your application's speed; for example, by setting up a synchronous connection to a container that blocks.
To determine whether a synchronous container connection will improve your application, you must test your application with and without the synchronous setting, using a test input stream that emulates the actual conditions your application will face in production. Use the Rules of StreamBase Execution Order in the Execution Order and Concurrency page as general guidelines to help decide whether to use synchronous container connections.
StreamBase detects and prevents any attempt to make a synchronous container connection to:
-
Any stream in the system container
-
An endpoint that would cause a loop in processing
When using a StreamBase URI as part of a stream-to-stream container connection string to specify that one side of the container connection is on a remote StreamBase Server, you can optionally specify URI parameters as part of the remote URI.
The URI parameters you can specify for connections to remote servers depend on which side of the connection is remote. There are two cases:
-
If the URI for the remote server is on the right of the equals sign, then the remote server is the source of the container connection. For example:
boxA.instream1=("sb://remotehost:9900/boxB.outstr4")In this case, you can specify one parameter for the connection:
-
reconnect-interval
-
-
If the URI for the remote server is on the left of the equals sign, then the remote server is the destination of the container connection. For example:
("sb://remotehost:9900/boxC.instr2")=boxD.outstr6In this case, you can specify up to six parameters for the connection:
-
reconnect-interval
-
enqueue-buffer-size
-
max-enqueue-buffer-size
-
enqueue-flush-interval
-
ConnectOnInit
-
These parameters have the same meanings for container connections as the similarly named property of the StreamBase to StreamBase adapters described in StreamBase to StreamBase Output Adapter and StreamBase to StreamBase Input Adapter.
| Container Connection Parameter | SB to SB Adapter Property | Default Value | Units | Description |
|---|---|---|---|---|
| reconnect-interval | Reconnect Interval | 10000 (10 seconds) | milliseconds |
The period, in milliseconds, that the container connection waits between
reconnection attempts after the connected application fails or no compatible
stream is present. Set this parameter to zero to disable reconnection. When
reconnection is disabled, the connected application must be started first and
must have a compatible output stream from which the upstream application can
read.
NoteWhen specifying a reconnection interval as part of a container connection to a remote host, specify the interval value in milliseconds. (When specifying the reconnection interval in the StreamBase to StreamBase Output adapter, the value is in seconds.) |
| enqueue-buffer-size | Enqueue buffer size | 100 | tuples |
The numbers of tuples to enqueue before tuples are sent to the connected
application.
For a low-latency application, set the buffer size to zero. |
| max-enqueue-buffer-size | Max enqueue buffer size | 1000 | tuples | The maximum size of the enqueue buffer before tuples are dropped. Enter –1 to disable this setting. |
| enqueue-flush-interval | Enqueue flush interval | 100 | milliseconds |
The flush interval of the enqueue buffer in milliseconds.
For a low-latency application, set the flush interval to a small non-zero number. Do not set it to zero, which causes the adapter to perform a busy loop and consume excessive CPU cycles. |
| username | User Name | None | None | Only applies when using StreamBase local file authentication specified in configuration files. |
| password | Password | None | None | Only applies when using StreamBase local file authentication specified in configuration files. |
Append one or more container connection parameters to a StreamBase URI, each preceded by a semicolon. For example, to specify non-default buffer sizes for a destination connection, use a container connection string like the following:
("sb://remotehost:9900/boxC.instr2;enqueue-buffer-size=300;max-enqueue-buffer-size=2000")=boxD.outstr6
To filter data as it is enqueued, you can use a --where
predicate, as illustrated below for a field named Price:
("sb://remotehost:9900/boxC.instr2;enqueue-buffer-size=300;max-enqueue-buffer-size=2000")=boxD.outstr6 --where Price > 100
See StreamBase to StreamBase Output Adapter for a discussion of these property settings.