Contents
By default, user accounts on Linux have a setting equivalent to ulimit -n 1024, which caps the maximum number of
concurrently open file descriptors to 1,024 for all processes launched concurrently
by that user. However, LiveView Server opens a new file descriptor for each new
services-layer connection. The upper boundary set by LiveView is 3000, which is
higher than the default per-user LInux value.
You may want to increase the ulimit setting for the user
accounts running LiveView Server, to allow for up to 3000 connections allowed by
LiveView, plus an additional number to account for network socket connections held
open concurrently by StreamBase EventFlow applications in the same server, plus all
other concurrent processes. A good starting value when running LiveView Server on
Linux is to specify ulimit -n 4096 for the
user account that will run the server. You may need to adjust this number higher.
By default, TIBCO LiveView and TIBCO StreamBase use the platform's default character encoding when reading files or communicating over certain network protocols. If you require another character encoding, you can change the default settings as follows. This example uses UTF-8 as the new character encoding.
To set the file encoding for StreamBase Studio, edit the system properties for file.encoding and streambase.tuple-charset. These properties are set locally in a project's sbd.sbconf file.
Edit the sbd.sbconf file for your project as shown:
<java-vm> <sysproperty name="file.encoding" value="UTF-8"/> <sysproperty name="streambase.tuple-charset" value="UTF-8"/> </java-vm>
This tells all StreamBase processes to emit tuples in UTF-8 encoding.
To set the default Java encoding for reading character data from files, set the environment variable STREAMBASE_STUDIO_VMARGS. In Windows, you can do this at the StreamBase Command Prompt with the set command (this one-line command is shown on two lines for clarity):
set STREAMBASE_STUDIO_VMARGS=-Dfile.encoding=UTF-8 -Dstreambase.tuple-charset=UTF-8
-Xms256m -Xmx1500M
This environment variable changes the default Java encoding when reading character data from files (file.encoding) and instructing the API to transfer character data as UTF-8 (streambase.tuple-charset). Start StreamBase Studio with the environment variables you just changed by using the command-line tool from the same StreamBase Command Prompt:
sbstudio
Once the STREAMBASE_STUDIO_VMARGS variable is set in StreamBase Studio, the character encoding for LiveView server will also be set to the new encoding.
To tell TIBCO LiveView Desktop to read the new character encoding, start LiveView Desktop with the -vmargs argument. To do this at the command line, use this command:
lv-desktop -vmargs -Dstreambase.tuple-charset=UTF-8
This tells LiveView Desktop that incoming tuples are encoded as UTF-8.
Note
If your application uses a Feed Simulation that reads files and you start the simulation from outside StreamBase Studio, you need to give the same options to the simulation. For example, to use UTF-8, use the following:
sbfeedsim -J-Dfile.encoding=UTF-8 my-feedsim.sbfs
Readers familiar with the StreamBase environment may be comfortable connecting to StreamBase Server from the command prompt with the sbc command. Those readers can still use sbc to connect to LiveView Server as a basic way to enqueue data into a running LiveView table.
To test the example in this section, load and run the LiveView Minimal sample as described in Starting LiveView Server from StreamBase Studio.
The following information will clarify some of the important features of LiveView Server tables:
-
Each LiveView table is defined in a single LiveView configuration file. The basename of the lvconf file and the table name must be the same.
-
When LiveView Server loads the configuration file and generates one LiveView table per lvconf file, it places each table in its own container. The container's name is always the same as the table. Thus, the Minimal sample defines one table named Minimal that LiveView Server places in a container also named Minimal.
-
Each table container has exactly one input stream, always named
DataIn. -
Since we know the name of the container for each table, we know the StreamBase path to the
DataInstream for each table. For the Minimal sample, this path isMinimal.DataIn.
Using this information, we can obtain a description of the schema for the
Minimal.DataIn stream using the sbc describe command:
sbc describe Minimal.DataIn
This returns the following output:
<stream input="true" name="Minimal.DataIn" schema="DataSchema"
uuid="E31A63B852D8DD9D15B0BD6CD1BA88B2">
<schema name="DataSchema" uuid="4AB4515006E401E64FFED374ABD55947">
<field description="" name="PublisherID" type="string"/>
<field description="" name="PublisherSN" type="long"/>
<field description="" name="CQSReferredCount" type="long"/>
<field description="" name="CQSDataUpdatePredicate" type="string"/>
<field description="" name="CQSDelete" type="bool"/>
<field description="" name="pkey" type="string"/>
<field description="" name="val" type="string"/>
</schema>
</stream>
LiveView Desktop shows us only two fields for the Minimal table, but sbc describe shows us seven fields. The first five fields are required by the inner workings of LiveView, and are handled internally by LiveView Desktop. To enqueue data manually to a running LiveView table with sbc enqueue, we must specify values for all seven fields. We can use any values that match the specified data types for the two Publisher* fields, but you must set CQSReferredCount and CQSDataUpdatePredicate to null, and must set CQSDelete to false.
The two fields of interest hold a generic key-value string pair. Start LiveView Desktop and connect to the running Minimal sample as described above, and double-click to open the Minimal table.
Then open a terminal window on OS X or Linux, or open a StreamBase Command
Prompt on Windows, and type the following commands in sequence, watching the results
in the LiveView Desktop window. This example uses "sbc"
as an arbitrary string for the PublisherID field, and arbitrarily increments the
second field by one for each input line. As required, the example sends null and false to the three CQS fields.
The last two fields, pkey and val, hold the values that show up in LiveView Desktop:
sbc enqueue Minimal.DataIn sbc, 1, null, null, false, City, London sbc, 2, null, null, false, Nation, France sbc, 3, null, null, false, City, Paris sbc, 4, null, null, false, Region, Buckinghamshire sbc, 5, null, null, false, City, "High Wycombe" sbc, 6, null, null, false, Nation, England ...
Continue entering geographical information or switch to another set of related
key-value pairs, as you prefer. Rows with the same pkey
primary key field replace previous rows with the same pkey text. For the entries above, the Minimal table in LiveView
Desktop shows the following results.
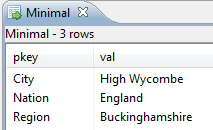
|
Alert rules can be set to read-only status. This is useful if you want alert rules to be preserved for multiple clients. Follow these steps:
-
Right-click in the project's root directory and select → . This opens the New StreamBase Server Configuration File dialog.
-
Select the root directory for your project.
-
Enter
sbd.sbconfin the Server Configuration file name field. -
Click . This creates an XML file with root element
<streambase-configuration>and opens the file in StreamBase Studio. -
Copy the following text into the file:
<java-vm> <sysproperty name="liveview.alert.disable.changes" value="true"/> </java-vm>
Save this file and run the project. When LiveView Server next runs, directives in the
sbd.sbconf file that you just created is automatically
merged into the primary configuration file for the server. Thus, once LiveView Server
starts, any non-local host client sessions that connect to the LiveView Server will
receive a "Not authorized" message if the client tries to edit configured alert
rules. Clients running on the same machine as the server process (localhost) are
allowed to change alert rules.
Alert rules can be disabled with a system property so configured alert rules will not run with LiveView starts. This is useful if you have created an alert rule that might damage your system. The system properties liveview.alert.register.startup and liveview.alert.enabled control whether a project's alerts are registered and whether the alert service starts when the server starts. By default, these properties are set to true. If you set these properties to false, you can start LiveView Server without your configured alerts, and still use StreamBase Studio to edit or disable the alerts. To set either of these properties to false, follow these steps:
-
Right-click in the project's root directory and select → . This opens the dialog.
-
Select the root directory for your project.
-
Enter
sbd.sbconfin the Server Configuration file name field. -
Click . This creates an XML file with root element
<streambase-configuration>and opens the file in StreamBase Studio. -
To prevent configured alerts from being registered at startup, copy the following text into the file under the java-vm tag:
<sysproperty name="liveview.alert.register.startup" value="false"/>
Setting this property to false means that configured alerts will not be registered. This means that you can start the server and edit or disable the problem alerts.
-
To prevent the alert service from starting, copy the following text into the file under the java-vm tag:
<sysproperty name="liveview.alert.enabled" value="false"/>
LiveView Server has the ability to process table queries in parallel, but does not do so by default. You can customize the parallelization and concurrency for each table to improve query performance. However, it is possible to over-specify these features and thereby overload the hardware that runs your LiveView Server instance. Thus, you must use the configuration elements described here with caution and careful testing.
In the lvconf file that defines each LiveView table, there are two attributes of the
table's root element, snapshot-parallelism and
snapshot-concurrency, that control the parallelism and
concurrency of query processing. You can also specify these settings in a Table Space
type table, then specify that Table Space in a <table-space-ref> element in the lvconf for some of the data
tables in your project.
Snapshot parallelism determines the number of data regions
used in parallel to publish to and scan from tables. Each data region contains
approximately 1/N of the total rows in the
table, where N is the snapshot-parallelism value. Use snapshot parallelism to improve load
performance and query performance where a query needs to scan many rows of a table.
In general, a higher snapshot-parallelism value means
that individual table scan snapshot queries can run faster — if your server has
available CPU cores to support the value you specify.
Snapshot concurrency specifies the number of extra threads
used to service the snapshot portion of queries. By default, snapshot concurrency is
not enabled, which means that LiveView Server's single data-region thread also
services all snapshot queries. Setting the snapshot-concurrency attribute to X means there will be X extra independent threads for snapshot processing.
Additional snapshot query threads are most beneficial when you have ad hoc queries
that cannot use indexes and your table size is several hundred thousand rows or
larger.
For example, setting snapshot-concurrency=1 for a data
table results in two threads: one thread available to run snapshot queries, while the
default data-region thread remains available to handle data being published and to
handle all continuous query processing.
With no snapshot-concurrency setting, or by setting it equal to the default of 0, only one task operates at a time. That task could be an update or a snapshot scan. With snapshot-concurrency set to 2, for example, up to three tasks can run simultaneously. These three tasks would be one publish and continuous query process, and two snapshot table scans.
Your LiveView deployment should have more CPU cores than the aggregate total number
of (snapshot-parallelism times snapshot-concurrency). The ideal configuration provides one core for
every (snapshot-parallelism setting times snapshot-concurrency setting times the
number of LiveView data tables that will be actively queried). For
snapshot-parallelism=2 and snapshot-concurrency=1, the ideal LiveView Server would provide 2 *
2 = 4 cores for each active LiveView data
table.
LiveView allows you to control the rate of data outflow from a source table to an
aggregation table. This is called data conflation. The
publish-interval-millis attribute of the <data-table> tag, if set, adds latency and reduces volume by
limiting output from the base table to the aggregate table to the specified
publication rate. When set, the update delivers only the current row value (at most
one row per pkey) instead of "as fast as the data arrives." Updates into the base
table still happen at the as fast as data arrives.
For tables with an <aggregation> data-source only (not other data-source types)
you can add conflate-data=true which only changes how often the aggregate-processor
emits results into the table. This period is synchronized with
publish-interval-millis. With the default behavior of conflate-data=false, the aggregate-processor emits frequently from
the source table. With conflate-data=true the last
aggregate result per pkey is delivered to the table to be processed by the
<insert-rule> and <update-rule> expressions.
If you license a TIBCO® Suite that includes Live Datamart as a Suite Component, then your license for TIBCO Live Datamart includes a limit on the amount of customer data under management. This is the sum total of your data made available to client applications served by TIBCO Live Datamart. The exact limit in gigabytes of customer data under management authorized by your Suite license is stated on your TIBCO Order Form.
You can track the amount of your customer data served by TIBCO Live Datamart with a simple query sent to the server. You can issue the following query from any client application, including TIBCO LiveView™ Web, TIBCO LiveView™ Desktop, the lv-client command line tool, or from a client application you write using the TIBCO LiveView™ Client APIs in Java or .NET (on Windows only):
select sum(MBMemoryUsed) as UserDataUnderManagement from LiveViewStatistics
This command returns a single integer value in megabytes.
To determine which of your TIBCO LiveView tables is using the most data, view the LiveViewStatistics system table in a client application. The MBMemoryUsed column shows the approximate data for each table in megabytes.
Live Datamart Server releases before 2.1.0 explicitly specified the ConcurrentMarkSweep (CMS) collector as its Java garbage collector.
Live Datamart Server in releases 2.1.0, 2.1.1, and 2.1.2 do not specify an explicit Java garbage collector, which means the garbage collector setting falls back to the JVM's default. Live Datamart versions since 2.1.0 use JDK 8 by default, whose default garbage collector is the throughput collector.
To use the G1 garbage collector instead of the throughput collector with releases
2.1.0, 2.1.1, and 2.1.2, add the following lines to the sbd.sbconf file at the root of your Studio project:
<java-vm>
<param name="jvm-args" value="
-XX:+UseG1GC
-XX:MaxGCPauseMillis=500 "/>
</java-vm>
Starting with Live Datamart Server 2.1.3, the G1 garbage collector is explicitly specified, using internal settings equivalent to the following:
<java-vm>
<param name="jvm-args" value="
-XX:+UseG1GC
-XX:MaxGCPauseMillis=500
-XX:ConcGCThreads=1 "/>
</java-vm>
If you specify a different JDK to run Live Datamart, that JDK's default garbage collector is used. For example, if you use the Azul Zing JDK, it has its own garbage collection implementation.
If you have a site policy that specifies using a different Java garbage collector than the defaults specified above, contact TIBCO Technical Support for assistance.