High Level Design
ibi Data Qualityhas several application components that provide a rich set of services to the consumers of data quality services, as well as the producers of those services.
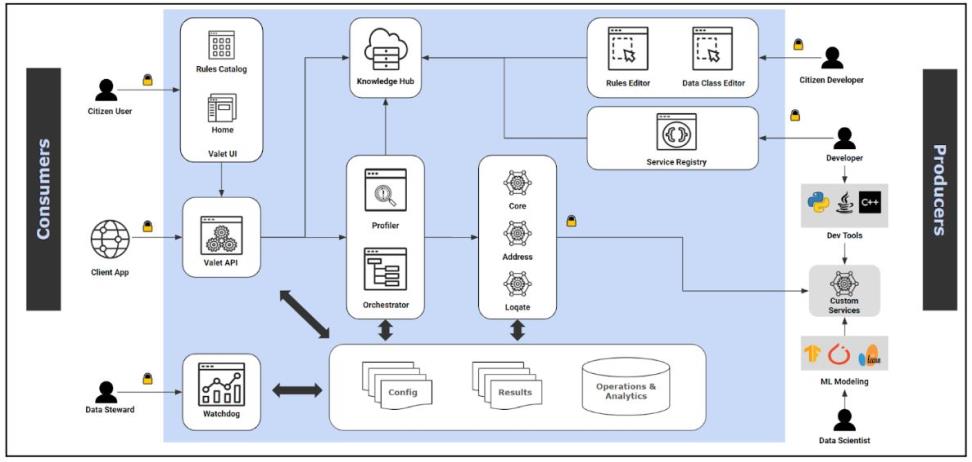
Producers
Producers are users who play the role of citizen developer or advanced developer. These users will interact with the application to create new Services, define new Data Classes, or author new Rules. For more information on Data Classes, Rules, and Services, see Concepts.
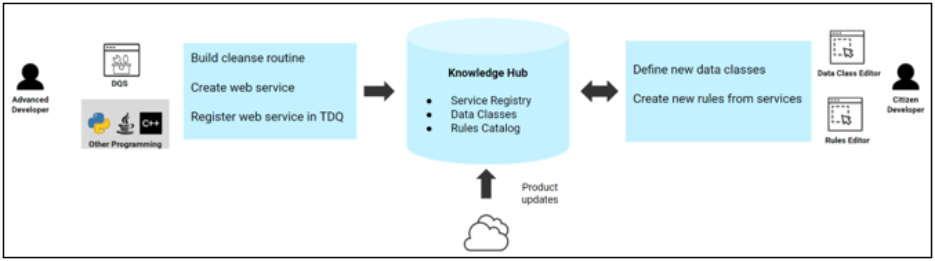
The ibi Data Quality has an open Service authoring architecture (i.e., developers have several different options to create new Services):
- Option 1. Use built-in Services to author new Rules.
- Option 2. Use ibi Omni-Gen Data Quality Server (DQS) as an authoring tool to create new or custom cleanse plans.
- Option 3. Create and register a RESTful Service using any other tool or language, such as Python, Java, etc.
Consumers
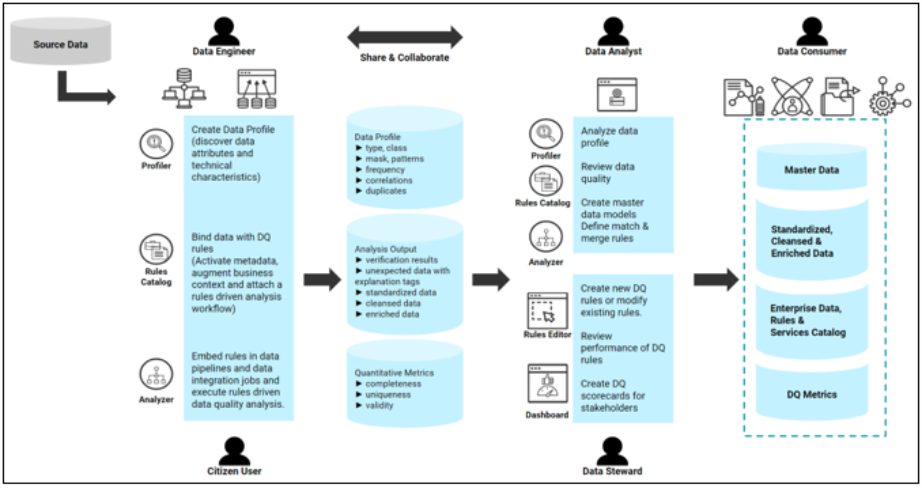
Consumers are users who play the role of citizen user, data engineer, data analyst, data scientist, data steward, etc. These users will interact with the application to discover data attributes and other technical characteristics, discover attribute relationships, detect outliers and anomalies, embed data quality analysis in data pipelines and data integration jobs, evaluate and review data quality scores and monitor and govern their data assets on different data quality dimensions.
Consumer-Focused Components
Valet API
This is the main pillar of ibi Data Quality. It powers all the other components of the solution. It also provides API services for programmatic interaction with ibi Data Quality.
Valet UI
This is a no-code user interface that enables citizen users to upload data, run profiling analysis, associate Rules with the data to execute data quality analysis, and download the results.
Rules Catalog
This is a discovery-focused user interface that enables data analysts to search for Rules applicable to their data.
Watchdog
This is a reporting user interface that allows data stewards to track, monitor, and report data quality metrics.
Producer-Focused Components
Rules Editor
This is a no-code user interface that allows data experts and data owners to author and publish new Rules from existing Services.
Data Class Editor
This is a no-code user interface that allows data experts and data owners to define new data classes using character masks/patterns, regular expressions and lookups.
Service Registry
This is a set of API services that allows developers to test new Services and register those Services in their ibi Data Quality instance.
DQ Studio
This is a Service authoring tool that allows developers to build new Services.
Internal Components
Knowledge Hub
This is the central repository of definitions and related artifacts for Data Classes, Services, and Rules.
Profiler
This is a scalable engine that performs comprehensive technical analysis of data.
Butler
This is an orchestration engine that interprets incoming requests and routes those requests to Service Providers.
Service Providers (Core, Address, DQS)
This is a set of Service Providers that accept requests from the Butler, execute data quality analyses, and respond with output results.
Analytics Repository
This is a relational data store used for persisting profiling and data quality stats, metrics, and scores.
Results Repository
This is a persistent file storage system used for storing profiling and data analysis results (input data, deduplicated data, cleansed output, detailed results, and summarized reports).
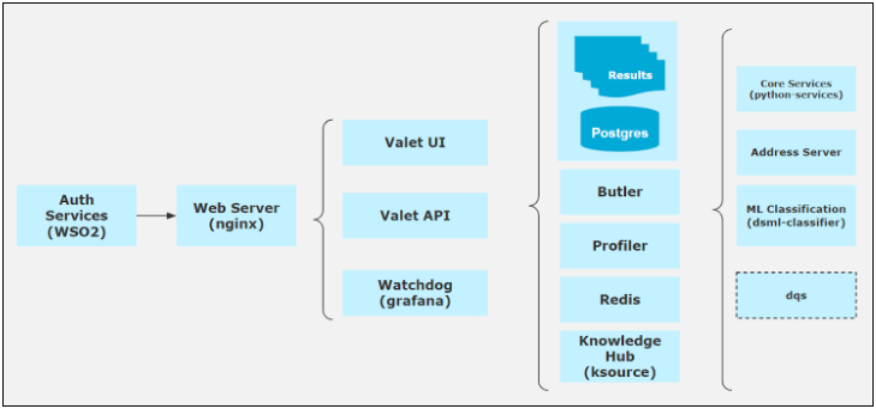
Containers
The following table lists and describes the containers that comprise ibi Data Quality.
|
Container Name |
Description |
||
|---|---|---|---|
|
address-server |
Performs address cleansing using Loqate. |
||
|
butler |
Orchestrates DQ analysis by interpreting Rules and routing requests to underlying services (python or DQS). |
||
|
dqs |
(Optional) Runs DQS workflows if the customer opts to use DQS to author and run data quality workflows. |
||
|
dsml-classifier |
Provides DSML models to classify data. |
||
|
grafana |
Hosts the Watchdog app that provides reports and dashboards on DQ metrics. |
||
|
ksource |
Provides API to manage data classes, rules and services. |
||
|
nginx |
Provides main ingress for ibi Data Quality. |
||
|
postgres |
Provides relational data store for shared application configuration and operational data. |
||
|
profiler |
Performs technical analysis on input data to generate data profile. |
||
|
python-services |
Performs data quality analyses on input data to generate data quality results. |
||
|
redis |
Provides a simple queue service for profiler. |
||
|
valet-services |
Provides back-end services for the Valet UI and APIs for programmatic interactions with ibi Data Quality. |
||
|
valet-ui |
Provide user interface for citizen users to interact with ibi Data Quality via web browser. |
Security Features
All external interactions with ibi Data Quality use HTTPS. For more information on steps to change the default certificate for the Kubernetes ingress or the nginx proxy used by the Docker Compose, see Deploying ibi Data Quality.
The ibi Data Quality requires that valet-ui, valet-services, and watchdog be exposed to the external network, along with endpoints in the WSO2 Identity Server that are required for OAuth2 and OpenID Connect. For convenience when running in trusted environments, Postgres and the WSO2 Identity Server console are exposed by default. In production or untrusted environments, you can disable access to these services by following the steps described in Deploying ibi Data Quality.
Authentication and Authorization inibi Data Qualityuse the OAuth2 and OpenID Connect protocols, with signed JSON web tokens. Any access to the application requires authentication, and specific operations require roles or permissions as described in Managing Users.
The valet-services API provides an authentication service that allows an API user to acquire a bearer token. You must supply this token in the HTTP Authorization header for all requests made through the API. The bearer token expires after one hour. For more information, see Authorize.