Which Processes Are Set-based?
You can use set-based processing for the following types of operations:
- Selecting records. You can select a group of data source records at one time using the NEXT command with the FOR prefix. Maintain Data retrieves all of the data source records that satisfy the conditions you specified in the command and then automatically puts them into the data source stack that you specified.
- Collecting transaction values. You can use forms to display, edit, and enter values for groups of rows. The rows are retrieved from a data source stack, displayed in the form, and are placed back into a stack when the user is finished. You can also use the NEXT command to read values from a transaction file into a stack.
- Writing transactions to the data source. You can include, update, or delete a group of records at one time using the INCLUDE, UPDATE, REVISE, or DELETE commands with the FOR prefix. The records come from the data source stack that you specify in the command.
- Manipulating stacks. You can copy a set of records from one data source stack to another and sort the records within a stack.
The following diagram illustrates how these operations function together in a procedure:
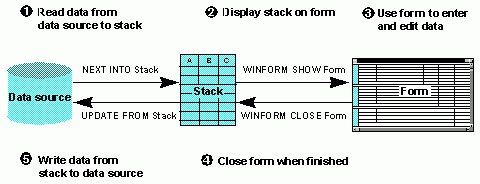
The diagram is explained in detail below:
- The procedure selects several records from the data source and, for each record, copies the values for fields A, B, and C into the data source stack. It accomplishes this using the NEXT command.
- The procedure displays a form on the screen. The form shows multiple instances of fields A, B, and C. The field values shown on the screen are taken from the stack. This is accomplished using a form and the Winform Show command.
- The procedure user views the form and enters and edits data. As the form responds to the activity of the user, it automatically communicates with the procedure and updates the stack with the new data.
- The procedure user clicks a button to exit the form. The button accomplishes this by triggering the Winform Close command.
- The procedure writes the values for fields A, B, and C from the stack to the selected records in the data source. The procedure accomplishes this using the UPDATE command.