Using a Simple Moving Average
A simple moving average is a series of arithmetic means calculated with a specified number of values from a field. Each new mean in the series is calculated by dropping the first value used in the prior calculation, and adding the next data value to the calculation.
Simple moving averages are sometimes used to analyze trends in stock prices over time. In this scenario, the average is calculated using a specified number of periods of stock prices. A disadvantage to this indicator is that because it drops the oldest values from the calculation as it moves on, it loses its memory over time. Also, mean values are distorted by extreme highs and lows, since this method gives equal weight to each point.
Predicted values beyond the range of the data values are calculated using a moving average that treats the calculated trend values as new data points.
The first complete moving average occurs at the nth data point because the calculation requires n values. This is called the lag. The moving average values for the lag rows are calculated as follows: the first value in the moving average column is equal to the first data value, the second value in the moving average column is the average of the first two data values, and so on until the nth row, at which point there are enough values to calculate the moving average with the number of values specified.
Example: Calculating a New Simple Moving Average Column
This request defines an integer value named PERIOD to use as the independent variable for the moving average. It predicts three periods of values beyond the range of the retrieved data.
DEFINE FILE GGSALES SDATE/YYM = DATE; SYEAR/Y = SDATE; SMONTH/M = SDATE; PERIOD/I2 = SMONTH; END TABLE FILE GGSALES SUM UNITS DOLLARS BY CATEGORY BY PERIOD WHERE SYEAR EQ 97 AND CATEGORY NE 'Gifts' ON PERIOD RECAP MOVAVE/D10.1= FORECAST(DOLLARS,1,3,'MOVAVE',3); END
The output is:
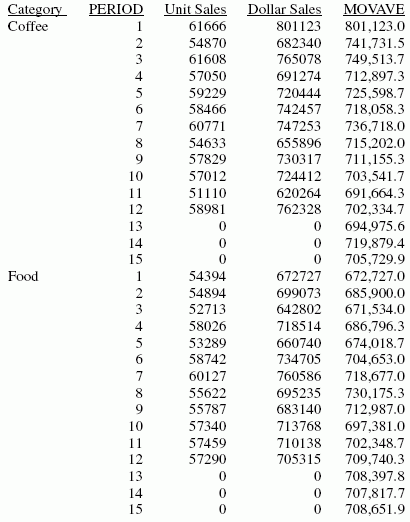
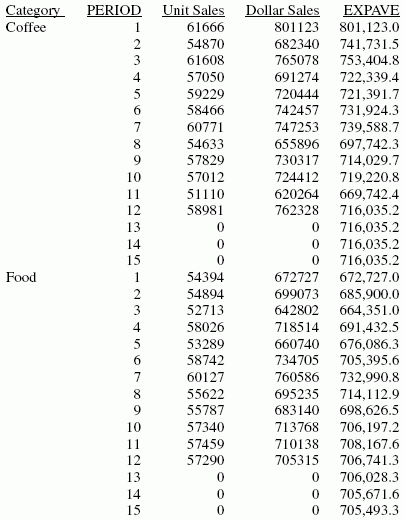
In the report, the number of values to use in the average is 3 and there are no UNITS or DOLLARS values for the generated PERIOD values.
Each average (MOVAVE value) is computed using DOLLARS values where they exist. The calculation of the moving average begins in the following way:
- The first MOVAVE value (801,123.0) is equal to the first DOLLARS value.
- The second MOVAVE value (741,731.5) is the mean of DOLLARS values one and two: (801,123 + 682,340) /2.
- The third MOVAVE value (749,513.7) is the mean of DOLLARS values one through three: (801,123 + 682,340 + 765,078) / 3.
- The fourth MOVAVE value (712,897.3) is the mean of DOLLARS values two through four: (682,340 + 765,078 + 691,274) /3.
For predicted values beyond the supplied values, the calculated MOVAVE values are used as new data points to continue the moving average. The predicted MOVAVE values (starting with 694,975.6 for PERIOD 13) are calculated using the previous MOVAVE values as new data points. For example, the first predicted value (694,975.6) is the average of the data points from periods 11 and 12 (620,264 and 762,328) and the moving average for period 12 (702,334.7). The calculation is: 694,975 = (620,264 + 762,328 + 702,334.7)/3.
Example: Using an Existing Field as a Simple Moving Average Column
This request defines an integer value named PERIOD to use as the independent variable for the moving average. It predicts three periods of values beyond the range of the retrieved data. It uses the same name for the RECAP field as the first argument in the FORECAST parameter list. The trend values do not display in the report. The actual data values for DOLLARS are followed by the predicted values in the report column.
DEFINE FILE GGSALES SDATE/YYM = DATE; SYEAR/Y = SDATE; SMONTH/M = SDATE; PERIOD/I2 = SMONTH; END TABLE FILE GGSALES SUM UNITS DOLLARS BY CATEGORY BY PERIOD WHERE SYEAR EQ 97 AND CATEGORY NE 'Gifts' ON PERIOD RECAP DOLLARS/D10.1 = FORECAST(DOLLARS,1,3,'MOVAVE',3); END
The output is: