All release notes
- Version 2.5.15
- Version 2.5.14
- Version 2.5.13
- Version 2.5.12
- Version 2.5.11
- Version 2.5.10
- Version 2.5.9
- Version 2.5.8
- Version 2.5.7
- Release Note 2.5.6
- Release Note 2.5.5
- Release Note 2.5.4
- Release Note 2.5.3
- Release Note 2.5.2
- Release Note 2.5.1
- Release Note 2.5.0
- Release Note 2.4.0
- Release Note 2.3.2
- Release Note 2.3.1
- Release Note 2.3.0
- Release Note 2.2.5
- Release Note 2.2.4
- Release Note 2.2.3
- Release Note 2.2.2
- Release Note 2.2.1
- Release Note 2.2.0
- Release Note 2.1.0
- Release Note 2.0.1
- Version 2.0.0
- Release Note 1.13.1
- Release Note 1.13.0
- Release Note 1.12.2
- Release Note 1.12.1
- Release Note 1.12.0
- Release Note 1.11.0
- Release Note 1.10.1
- Release Note 1.10.0
- Release Note 1.9.2
- Release Note 1.9.1
- Release Note 1.9.0
- Release Note 1.8.6
- Release Note 1.8.5
- Release Note 1.8.4
- Release Note 1.8.3
- Release Note 1.8.2
- Release Note 1.8.1
- Release Note 1.8.0
- Release Note 1.7.11
- Release Note 1.7.10
- Release Note 1.7.9
- Release Note 1.7.8
- Release Note 1.7.7
- Release Note 1.7.6
- Release Note 1.7.5
- Release Note 1.7.4
- Release Note 1.7.3
- Release Note 1.7.2
- Release Note 1.7.1
- Release Note 1.7.0
- Release Note 1.6.2
- Release Note 1.6.1
- Release Note 1.6.0
- Release Note 1.5.8
- Release Note 1.5.7
- Release Note 1.5.6
- Release Note 1.5.5
- Release Note 1.5.4
- Release Note 1.5.3
- Release Note 1.5.2
- Release Note 1.5.1
- Release Note 1.5.0
- Release Note 1.4.0
- Release Note 1.3.1
- Release Note 1.3.0
- Release Note 1.2.1
- Release Note 1.2.0
- Release Note 1.1.0
- Release Note 1.0.0
- Known limitations
Version 2.5.15
Released: January 2022
New features
This release contains no new features.
Changes in Functionality
When the Using cleansing property is set to No, the Inline cleansing data group is hidden.
Changes to third-party libraries
This release contains no changes to third-party libraries.
Closed issues
This release contains the following closed issues:
[DAQA-3894] An error message displays when running the Merge view service from the Light view.
[DAQA-3901] A
NullPointerExceptionoccurs when executing the Refresh relationships service.[DAQA-3902] The label input is validated when running the Statistics service from a dataspace.
Known issues
This release contains the following known issues related to matching functionality:
The EBX® session lifetime is limited for security reason, meaning the user is logged out automatically after a certain amount of time passes without activity. In some situations, this can open the login EBX® screen inside a frame of the EBX® Match and Merge Add-on views. To exit from this type of situation, select any action outside the frame, and then EBX® full login screen will appear. This limitation has no consequence on data integrity or security issues. This is an ergonomics known limitation.
When the search panel is active on the EBX® tabular view, it will be inherited in the matching views. Then, it is no longer possible to remote it at the level of the matching views. It is mandatory to remove it from the EBX® tabular view.
All EBX® Match and Merge Add-on services and triggers are deactivated on children data-sets.
If you want to use old configuration archive files from a previous version, after importing them, you must restart the system.
Search option on matching views is disabled for searching on foreign key which is configured as matching field with multi hop links.
Multi occurrence field and foreign key field with multi hop are not supported when executing 'Exact match at once' operation.
You should avoid matching with inherited fields or value functions because they are not indexed in EBX® and can lead to performance issue.
Matching is not enabled on D3 slave delivery dataspaces.
The enumeration fields are not taken into account when matching.
Only single-occurrence fields at the first level of a multi-occurrence group are considered when matching.
Match at once parallel does not support 'Data life cycle context' in Matching policy.
Exact match at once in memory does not support 'Matching policy context' in Matching policy.
In a surrogate matching, complex fields, foreign key fields, multiple-value fields and enumeration fields cannot be taken as alternative matching fields.
When changes are made to the configuration while the 'Match at once' service is running, the add-on reloads the index and executes matching with the new configuration.
When data referenced by foreign keys, or contained in linked tables, is modified during a matching operation, the system automatically clears and reloads the cache.
If a related table's foreign key is in a list, you cannot run the Align foreign key of merged record service on the golden, or pivot record.
The Restore from history service is not available on tables containing the DaqaMetaData group.
This release contains the following known issue related to cleansing functionality: The cleaning procedure 'Foreign key fixing' does not support multi-valued FK. It is not possible to fix a FK that is a part of a primary key.
This release contains the following known issue related to the crosswalk feature: The crosswalk function does not support matching on foreign keys.
Version 2.5.14
Released: December 2021
New features
This release contains no new features.
Changes in Functionality
This release contains no functionality changes.
Changes to third-party libraries
This release contains the following third-party library updates:
The Spring Framework was updated to version 5.2.15.
The jQuery UI library was updated to version 1.13.0.
Closed issues
[DAQA-3890] Validate data in the Table/Field trusted source configuration.
Known issues
This release contains the following known issues related to matching functionality:
The EBX® session lifetime is limited for security reason, meaning the user is logged out automatically after a certain amount of time passes without activity. In some situations, this can open the login EBX® screen inside a frame of the EBX® Match and Merge Add-on views. To exit from this type of situation, select any action outside the frame, and then EBX® full login screen will appear. This limitation has no consequence on data integrity or security issues. This is an ergonomics known limitation.
When the search panel is active on the EBX® tabular view, it will be inherited in the matching views. Then, it is no longer possible to remote it at the level of the matching views. It is mandatory to remove it from the EBX® tabular view.
All EBX® Match and Merge Add-on services and triggers are deactivated on children data-sets.
If you want to use old configuration archive files from a previous version, after importing them, you must restart the system.
Search option on matching views is disabled for searching on foreign key which is configured as matching field with multi hop links.
Multi occurrence field and foreign key field with multi hop are not supported when executing 'Exact match at once' operation.
You should avoid matching with inherited fields or value functions because they are not indexed in EBX® and can lead to performance issue.
Matching is not enabled on D3 slave delivery dataspaces.
The enumeration fields are not taken into account when matching.
Only single-occurrence fields at the first level of a multi-occurrence group are considered when matching.
Match at once parallel does not support 'Data life cycle context' in Matching policy.
Exact match at once in memory does not support 'Matching policy context' in Matching policy.
In a surrogate matching, complex fields, foreign key fields, multiple-value fields and enumeration fields cannot be taken as alternative matching fields.
When changes are made to the configuration while the 'Match at once' service is running, the add-on reloads the index and executes matching with the new configuration.
When data referenced by foreign keys, or contained in linked tables, is modified during a matching operation, the system automatically clears and reloads the cache.
If a related table's foreign key is in a list, you cannot run the Align foreign key of merged record service on the golden, or pivot record.
The Restore from history service is not available on tables containing the DaqaMetaData group.
This release contains the following known issue related to cleansing functionality: The cleaning procedure 'Foreign key fixing' does not support multi-valued FK. It is not possible to fix a FK that is a part of a primary key.
This release contains the following known issue related to the crosswalk feature: The crosswalk function does not support matching on foreign keys.
Version 2.5.13
Released: October 2021
New features
This release contains the following new features:
The Align foreign key of all merged records service allows you to align tables configured in the Relationship table.
You can now configure a permission for the Modify record service.
A workflow is automatically launched when a Suspicious record is modified.
The latest timestamp is now applied for most trusted source records.
You can now specify a Matching policy when using the
MatchingOperations.matchSelection()API.The Search before create service now redirects to the initial screen, where it starts.
The API's new
MatchingOperations.disableMatchingPolicy()andMatchingOperations.enableMatchingPolicy()methods allow you to disable/enable a list of Matching policies.You can now configure to display the Toolbars button on the Data quality stewardship view.
Changes in Functionality
This release contains no functionality changes.
Changes to third-party libraries
This release contains no updates to third-party libraries.
Closed issues
This release contains the following bug fixes:
[DAQA-3863] An impacted cluster is not fixed when a record becomes Suspicious.
[DAQA-3873] There are two Pivot records in one cluster after running the Match table service.
[DAQA-3879] A
Performanceissue occurs when executing a matchBestCluster() operation.[DAQA-3880] A
Deadlockoccurs when executing a simulateMatchTable operation while a cache update is in progress.
Known issues
This release contains the following known issues related to matching functionality:
The EBX® session lifetime is limited for security reason, meaning the user is logged out automatically after a certain amount of time passes without activity. In some situations, this can open the login EBX® screen inside a frame of the EBX® Match and Merge Add-on views. To exit from this type of situation, select any action outside the frame, and then EBX® full login screen will appear. This limitation has no consequence on data integrity or security issues. This is an ergonomics known limitation.
When the search panel is active on the EBX® tabular view, it will be inherited in the matching views. Then, it is no longer possible to remote it at the level of the matching views. It is mandatory to remove it from the EBX® tabular view.
All EBX® Match and Merge Add-on services and triggers are deactivated on children data-sets.
If you want to use old configuration archive files from a previous version, after importing them, you must restart the system.
Search option on matching views is disabled for searching on foreign key which is configured as matching field with multi hop links.
Multi occurrence field and foreign key field with multi hop are not supported when executing 'Exact match at once' operation.
You should avoid matching with inherited fields or value functions because they are not indexed in EBX® and can lead to performance issue.
Matching is not enabled on D3 slave delivery dataspaces.
The enumeration fields are not taken into account when matching.
Only single-occurrence fields at the first level of a multi-occurrence group are considered when matching.
Match at once parallel does not support 'Data life cycle context' in Matching policy.
Exact match at once in memory does not support 'Matching policy context' in Matching policy.
In a surrogate matching, complex fields, foreign key fields, multiple-value fields and enumeration fields cannot be taken as alternative matching fields.
When changes are made to the configuration while the 'Match at once' service is running, the add-on reloads the index and executes matching with the new configuration.
When data referenced by foreign keys, or contained in linked tables, is modified during a matching operation, the system automatically clears and reloads the cache.
If a related table's foreign key is in a list, you cannot run the Align foreign key of merged record service on the golden, or pivot record.
The Restore from history service is not available on tables containing the DaqaMetaData group.
This release contains the following known issue related to cleansing functionality: The cleaning procedure 'Foreign key fixing' does not support multi-valued FK. It is not possible to fix a FK that is a part of a primary key.
This release contains the following known issue related to the crosswalk feature: The crosswalk function does not support matching on foreign keys.
Version 2.5.12
Released: August 2021
New features
This release contains the following new features:
The API's new
MatchingOperations.checkSimilarity()method allows you to check similarity between two records.A new Match best cluster service allows you to put a record in the best cluster.
You can no longer configure the Is prebuilt property when creating a new custom algorithm.
The Matching operation is now improved to protect existing clusters.
The Exact match without the In memory mode operation is now improved to protect existing clusters.
Changes in Functionality
This release contains no functionality changes.
Changes to third-party libraries
This release contains the following third-party updates:
Apache Commons Compress to version 1.21.
Closed issues
This release contains the following bug fixes:
[DAQA-3838] An
ArrayIndexOutOfBoundsExceptionoccurs when executing a Matching operation when the Matching policy has a matching policy context of another table.[DAQA-3840] A performance issue occurs when executing the Align foreign key service.
[DAQA-3842] A performance issue occurs when executing the Matching service on a multi-valued foreign matching field.
Version 2.5.11
Released: June 2021
New features
This release contains the following new features:
The Auto create new golden property is now applied when fixing an invalid cluster.
The API's new
MatchingOperations.matchBestCluster()method allows you to put a record in the best cluster.
Library updates
Spring Data was removed from ui-framework-dependencies.jar.
Bug fixes
This release contains the following bug fixes:
[DAQA-3518] An incorrect survivorship result is returned when the Field trusted sources property does not contain the source value of the survivor record.
[DAQA-3817] The error message Cannot access the service is displayed in the Merge view when executing merge manually with the Automatically create new golden option activated.
[DAQA-3819] An incorrect Merged field logging message is returned when executing the Merge record service.
[DAQA-3831] An incorrect result is returned when executing a Simulate match table operation.
Version 2.5.10
Released: May 2021
New features
This release contains the following new features:
You can now configure the Number of processed records to update status property to decide when the Matching process will update the status of monitoring.
To ensure cluster retention, a record is moved to an existing cluster that has a Golden record when the record and the Golden record match.
Bug fixes
This release contains the following bug fixes:
[DAQA-3786] Multi-occurrence data is not merged into the Golden when executing merge data manually from the Merge view.
[DAQA-3787] An incorrect result is returned when modifying a record when the No match records when same source property is activated.
[DAQA-3789] A Pivot does not become Golden when the cluster has only Merged and Deleted records.
[DAQA-3790] An exception is improperly handled when executing a Survivorship operation.
[DAQA-3796] An incorrect result is returned when executing a Match table operation when the On not suspect with property is activated.
[DAQA-3799] An incorrect result is returned when executing a Match table operation on a broken foreign key field.
Version 2.5.9
Released: March 2021
Updates
An update was applied to correct an issue with the Apache Standard Taglibs library.
Version 2.5.8
Released: February 2021
New features
This release contains the following new features:
The add-on was renamed to TIBCO EBX® Match and Merge Add-on.
Clusters are now fixed after executing a Run match operation or the
MatchingOperations.matchSelection()method in the API.Merged records will follow their target record if the record is moved out of a cluster.
Version 2.5.7
Released: January 2021
New features and upgrades
This release contains the following new features and upgrades:
The progress bar was enriched to include additional information when executing the Set state and the Set at once operations.
The Back to tabular view button is always displayed when accessing into the (Light) Data quality stewardship from a tabular view.
The Matching operation was optimized to reduce processing time when using the Levenshtein algorithm with long string data.
The following libraries were updated:
Apache Standard Taglibs library to version 1.2.3.
Spring framework library to version 5.2.9.
Jackson Databind library to version 2.11.2.
Bug fixes
This release contains the following bug fixes:
[DAQA-3730] An incorrect result is returned when executing a Matching operation when the Filtering field rule and the Handle null value matching properties are configured.
[DAQA-3732] A Null pointer exception occurs when executing the Check add-on configuration service.
[DAQA-3758] An incorrect matching score is returned when executing the Simulate matching operation on a composite foreign matching field and the Exact algorithm.
[DAQA-3761] The MatchingOperations.matchSelection() is not applicable for the Golden record.
[DAQA-3763] A hidden record is still displayed when accessing to the Merge view from the Matching view.
Release Note 2.5.6
Release Date: October 20, 2020
New features
This release contains the following new features:
It is now possible to execute the Align foreign key of all merged records operation in a specific dataspace or dataset.
The API's new
MatchingOperations.alignForeignKeysInDataspace()method allows you to execute the Align foreign key of all merged records service in a specific dataspace.The Table services button is always displayed when access the (Full) Data quality stewardship through a workflow.
Bug fixes
This release contains the following bug fixes:
[DAQA-3710] An incorrect result is returned when executing the Matching operation when using matching through relation and the Handle null value matching is configured.
[DAQA-3725] The status screen is flickering continuously at the end of the process when executing the Set state service.
Release Note 2.5.5
Release Date: September 18, 2020
New features and enhancements
This release contains the following new features and enhancements:
Table services have been grouped into a collapsed list.
The On not suspect with property will be checked when removing a record from the Cluster. This will be the case despite the Suspect record retention property setting.
The Trusted source list configuration has been enhanced with the ability to move up, down, left and right.
It is now possible to execute the Unmerge operation using history from a parent dataspace.
It is now possible to change the Pivot record when executing the Check similarity service.
The Matching operation has been optimized to use less memory when using Exact and Fuzzyfulltext algorithms.
The add-on has been updated to support the OpenJDK8 and OpenJDK11 libraries.
Libraries were updated to fix some potential issues.
The MatchingOperations.matchSelection() API has been enhanced to inject a list of Matching states.
The MatchingOperations.alignForeignKeys() API has been enhanced to align records in same dataset.
Bug fixes
This release contains the following bug fixes:
[DAQA-3649] An incorrect result is returned when executing the Match table operation on a record having the Pivot in the Not suspect with list and the On not suspect property is activated.
[DAQA-3650] An incorrect number of records in group is displayed when executing the Match at once by groups service.
[DAQA-3651] An incorrect result is returned when creating a new record and the On not suspect with property is activated.
[DAQA-3652] An IndexOutOfBounds Exception occurs when executing the Match table operation when the Matching field and the Filter by properties are configured the same field.
[DAQA-3653] An incorrect result is returned when creating a new record and the On not suspect with property is activated.
[DAQA-3655] The Final score is displayed incorrectly in the Check similarity screen with one matching field.
[DAQA-3656] An incorrect result is returned when executing the Records linking analysis service.
[DAQA-3660] An incorrect result is returned when executing the Match table operation with FuzzyFullText algorithm.
[DAQA-3661] Merged records were not included in the Survivorship progress when executing the Exact match at once service.
[DAQA-3706] An incorrect condition can be configured for the Condition for field value survivorship property.
Release Note 2.5.4
Release Date: June 23, 2020
New features and enhancements
This release contains the following new features and enhancements:
The Check similarity service allows you to compare the similarity of two records in the same table. To test, you choose one of the matching policies configured for the table. The policy specifies which fields to compare and the algorithms to use. You can look at the resulting scores to get a preview of how the add-on would handle these records during a matching operation with the selected policy. For additional documentation, see Testing a matching policy.
The Search before create service no longer re-displays the search screen when accessing from a completed workflow.
You can now display the Table services button when accessing the (Full) Data quality stewardship through a workflow by configuring the Display 'Table services' button property on the workflow.
The API's new
matchSelection()method allows you to execute matching on a specific selection against the target states.You can now configure the Russian and FuzzyRussian algorithms to execute matching on a Russian character set.
When a record is put in the deleted state, merged records that target the deleted record are automatically updated with new target records.
The Repair old clusters service aligns merged records, those that target a deleted record, with a new pivot or golden. This allows you to repair defective clusters from older versions of the add-on.
Bug fixes
This release contains the following bug fixes:
[DAQA-3591] An incorrect result is returned when executing the Match table operation on a record having a null matching field and the Funneling matching property is activated.
[DAQA-3594] An incorrect result is returned when executing the Match table operation when the Funneling matching property is activated and the Filter by option is configured.
[DAQA-3597] An incorrect result is returned when executing the Exact match at once service with the Exclude records from matching property configured.
[DAQA-3598] An incorrect result is returned when executing the Match at once full mode service with the Exclude records from matching property configured.
[DAQA-3606] All groups are not listed when executing the Match at once by groups service.
[DAQA-3609] An incorrect result is returned when executing the Match at once full mode service while having a large of number records in excluded records.
[DAQA-3615] A Null pointer exception occurs when attempting to merge two unmatched records in the Merge view and the Automatically create new golden property is activated.
[DAQA-3630] A Null pointer exception occurs when attempting to merge two auto-created golden records in the Merge view and the Customize source value for new golden property is activated and the Source field is not defined.
[DAQA-3634] The batchOperationCode of all records are cleansed after executing the MatchingOperations.executeSurvivorshipOnClusters() API.
[DAQA-3635] All records are displayed in the Simple matching view when a view configured as the default view is applied.
Release Note 2.5.3
Release Date: April 20, 2020
New features and enhancements
This release contains the following new features and enhancements:
The behavior of the Align foreign key of merged records service has been improved in terms of precision.
The new Base record attribute has been added into the DaqaMetaData group to store the auto-created golden when it is created.
The display of error messages in the Merge view has been arranged to be more consistent.
The Merged by attribute has been updated to be more user-friendly.
When executing the Search before create service, the add-on now checks for differences between the parent and child dataspaces. If it does not find any differences, it only indexes the parent dataspace.
The Survivorship policy is now applied when executing the AutoCreateNewGolden operation on a single golden.
It is now possible to cancel the Run match operation when it is in progress.
Bug fixes
This release contains the following bug fixes:
[DAQA-3522] A Null pointer exception occurs when executing manually a merge in the Merge view.
[DAQA-3523] It takes too long to manually merge two records in the Merge view.
[DAQA-3525] The Last survivorship policy code is not updated when executing the Automatic merge operation.
[DAQA-3526] The Last survivorship policy code is updated incorrectly when executing the Merge manually operation.
[DAQA-3527] The Merged field logging is updated incorrectly when executing the Merge manually operation.
[DAQA-3533] An incorrect result is returned when executing the Match at once operation with full mode and the Auto create new golden for single golden option is activated.
[DAQA-3562] The Handle null value matching option is not taken into account when executing the Matching option with the FuzzyFullText algorithm configured.
[DAQA-3563] The Survivorship operation merges data from the record even when its score is lower than the Stewardship max score.
[DAQA-3574] A golden record is not created when executing the Move to a new cluster operation with the Auto create new golden for single golden activated.
[DAQA-3575] An incorrect result is returned when executing the Match at once operation when the Exclude records from matching property is configured.
Release Note 2.5.2
Release Date: January 15, 2020
New features and enhancements
This release contains the following new features and enhancements:
The add-on now provides an alternative option to import archived configuration settings. When importing an archive to update an existing, or migrate to a new environment, this option does not overwrite latest cluster ID values. You can access this functionality via the new Import configuration service. For information on migrating between environments and using the new service, see the Migrating configuration settings section in the User Guide.
The Output variable for a record in the EBX® Match and Merge Add-on script and user tasks is now the returned record's absolute location path.
The EBX® Match and Merge Add-on now does not check a null matching field before executing a Matching operation.
The Matching operation has been optimized to reduce processing time.
You can now configure the Handle no relationships matching property to ignore Relationship matching when executing matching on a record without a relationship.
Bug fixes
This release contains the following bug fixes:
[DAQA-3448] No results are returned when executing Search before create on a default label foreign key.
[DAQA-3451] The wrong button is displayed on the record form when accessing the Search before create service from a workflow.
[DAQA-3464] An error message is displayed when configuring the Crosswalk fields property.
[DAQA-3465] The Display relation records and Display merge record services are not displayed when accessing the Matching view.
[DAQA-3466] A blank page is displayed when running the Search before create wizard with read-only permission.
[DAQA-3467] An incorrect result is returned when executing the Match table operation with Field to exclude records from match configured as a Date or time field.
[DAQA-3502] The On workflow by state property is not taken into account when creating a new golden record.
Release Note 2.5.1
Release Date: December 10, 2019
Bug fixes
[DAQA-3460] A NullPointerException occurs when starting the repository.
Release Note 2.5.0
Release Date: November 8, 2019
New features and enhancements
This release contains the following new features:
Add-on configuration can now be completed using the new configuration wizard. Administrators can access the wizard using the New configuration service.
A User interface tab has been added under Data Quality Configuration > Table. From this tab, it is now possible to customize the data quality stewardship, simple matching, and merge views. From this tab, the states filter can also be hidden by configuring the State(s) to filter from selection property.
You can now configure a Korean algorithm to execute matching on a Korean character set.
It is now possible to set the matching state for selected records using the Set state service located in a table's Actions menu.
The Record XPath property in EBX® Match and Merge Add-on script and user tasks can be configured as either a relative or an absolute location path of an existing record.
The EBX® record form view is now applied when creating a new record with the Search before create service.
It is now possible to use some add-on features with a relational data model.
You can now configure a constant value for the Survivorship field by using the Constant survivorship fuction.
The following list describes updated behavior in this release:
The Force orphans golden option will set all records with no identified suspect into single golden.
It is now possible to match through a relationship table across dataspaces and datasets.
The Fix relation records is now applied to fix related records in a relationship table across dataspaces and datasets.
If the link is broken, the raw value is used to match when executing the matching operation on a foreign key field.
The Matching policy with a context is now prioritized when executing the Match at once operation.
The bottom part of the Simple matching view will be reloaded when updating a suspicious record.
The DoubleMetaPhone and the Soundex algorithms have been enhanced to improve performance.
The Most trusted source configuration has been simplified.
When a merged record is modified, the add-on executes the Match table operation on the merged record after executing on its target.
When executing a matching operation on a Golden or Pivot record, its merged records are not included in the operation regardless of the Merged records is recycled property setting.
The target of a merged record is only updated if its target record is not in the same cluster.
When a merged record is modified on a non-matching field, the add-on only executes the Merge operation.
When accessing the Simple matching view after creating a new record, if executing the Make Golden, Make definitive golden and Delete operations the add-on will navigate to the EBX® record form view.
Bug fixes
This release contains the following bug fixes:
[DAQA-713] The value of Latest cluster number is increased even though no new cluster is created.
[DAQA-3015] A JavaScript error occurs when clicking on the Selector pop-up of a foreign key matching field in the Search before create screen.
[DAQA-3089] The Main tab dissapears when accessing the Inline cleansing data under the metadata tab.
[DAQA-3117] An unexpected error is displayed when executing the Add into cluster operation on a record in a read-only dataspace.
[DAQA-3161] A
NullPointerExceptionoccurs when transferring data through the TIBCO EBX® Data Exchange Add-on.[DAQA-3211] The auto-created golden state becomes deleted when moving all merged records outside.
[DAQA-3265] The display layout breaks in the Process policy screen when viewing the screen with 4K resolution.
[DAQA-3269] A Snapshot property does not display correctly when configuring the Search before create user task in a workflow.
[DAQA-3275] The Relationship configuration is deleted when accessing the Merge view.
[DAQA-3276] An incorrect score is returned when executing the Match table operation on a multi-valued field.
[DAQA-3281] An orphan suspect occurs when executing the Run stewardship on defined pivot service.
[DAQA-3334] Incorrect behavior occurs when adding more input parameters in a Cleansing procedure configuration.
[DAQA-3344] An error occurs when updating a record in the Search before create workflow.
[DAQA-3380] The Matching cache is reloaded after the loadCache API is called.
[DAQA-3408] The Survivorship is not applied for an auto-created single Golden when executing the Exact match at once operation.
Release Note 2.4.0
Release Date: June 20, 2019
New features
This release contains the following new features:
The new Run match service—available from a table's Actions menu—has been added to the matching services catalog. This service allows you to select one or more records to include in a matching operation. If you run the service without making any selections, matching runs on the entire table.
Administrators can now enable the Search before create service. This service helps users avoid creating duplicate records by allowing them to search existing records prior to creating a new record.
You can now configure matching algorithm input parameters to reach expected results.
Merge view
It is now possible to merge a null value on a mandatory field if the Check null input property is inactive in the Merge view.
The Merge view has been enhanced to allow paging in the dependency table.
You can configure an output parameter to retrieve the Golden record when accessing the Merge view from a workflow.
You can now select two or more auto-created records then access the Merge view.
It is now possible to switch the Pivot in the Merge view by setting the Apply EBX permission on merge view property to true in the Process policy configuration.
Workflows
It is now possible to select a dataspace, dataset from a combo box when configuring a workflow.
By configuring the Hide the Back to tabular view button property, the Back to tabular view button can now be hidden when accessing the Matching view workflow.
The Align foreign keys service is now available from a workflow script task.
Updated functionality
The (Light) Data quality sterwardship and the (Full) Data quality stewardship menu items have been merged into the Data quality stewardship option.
In the Matching configuration, when there is more than one attribute in a multi-valued group, you no longer have to select an attribute and save to refresh the other drop-down lists.
The Table trusted source value is now applied for all fields by default if the Field trusted source is not configured.
The Search feature has been removed from the Matching view.
The Align foreign key of all merged records operation now fixes records across different dataspaces and datasets.
A progress bar is added to display status when executing the Align foreign key of all merged records operation.
You can now configure a condition for the Default survivorship function.
An auto-created golden record cannot stand alone in a cluster or being a single golden.
If a record no longer exists when executing the Display metadata service, the raw value is displayed instead of the link to the record.
API updates
This release contains the following API updates:
The API's new
executeSurvivorshipOnClusters()method allows you to execute survivorship on a list of clusters.The API's new
unmerge()method allows you to execute unmerge on a record.The MatchingOperations.matchSelection() API has been enhanced to get better results.
It is possible to disable or enable the trigger when executing the MatchingOperations.exactMatchAtOnce(TableContext,ExactMatchAtOnceContext) API.
You can now execute the simulateMatch operation through the Matching REST service.
You can now execute the Align foreign keys of all merged records or Align foreign key of merged records services through the Align foreign keys script task.
It is now possible to configure the Source record(s) property as a table record XPath expression in the Records linking analysis script task.
Bug fixes
This release contains the following bug fixes:
[DAQA-1004] An incorrect result is returned when running the Fix relation records service and the relation table has no matching configuration.
[DAQA-3073] A blank page is displayed when running a Cleansing operation.
[DAQA-3136] A NullPointerException occurs when executing the Records linking analysis script task.
Release Note 2.3.2
Release Date: March 25, 2019
New features
This release contains the following new features:
The Match table operation is executed when modifying an Unmatched record with the On Modification option activated.
Permissions are now by-passed when executing an Automatic merge operation.
The Match table operation is executed when modifying a Merged record with the On suspect record retention option activated and the Merged record is not matched with its target.
Bug fixes
This release contains the following bug fixes:
[DAQA-2957] Survivorship is not applied when accessing the Merge view.
[DAQA-2959] An incorrect result is returned when using the simulateMatchTable(SearchContext) API on a large set of records.
[DAQA-2992] After executing the Match table service, all records are displayed when accessing the Light view via a workflow.
Release Note 2.3.1
Release Date: December 13, 2018
New features
This release contains the following new features:
The EBX® Match and Merge Add-on has undergone extensive updates to ensure compatibility with the EBX® 5.9.0 Fix A release.
All add-on functionality now works as expected on the Firefox web browser.
When fixing an impacted cluster, the Auto create new golden for single golden option is applied to set the record as the Single Golden.
The Handle null value matching property is now applied when executing matching with the Funneling matching mode activated.
Matching operations have been enhanced to get better results.
The Unmerge operation will unmerge all merged records that target the Golden or the Pivot.
The number of active records in the cluster cannot be greater than the value specified by the Max number of records in cluster property plus 1.
When a Pivot record is manually removed from a cluster, the add-on fixes the cluster to improve results.
The add-on executes matching on the Pivot or the Golden when modifying a Merged record with the Modify merged without match option deactivated. The add-on follows this behavior regardless of whether the Pivot or Golden is auto-created.
Bug fixes
This release contains the following bug fixes:
[36849] When a configuration uses multiple relationships on the same table to find possible matches, only the score found using the last relationship is returned.
[36850] The API's
MatchingEventListener.onUnmerge()is not taken into account when executing anUnmergeoperation.[36851] An incorrect result is returned when executing matching using a multi-valued matching field and the Funneling matching property is activated.
[36853] A Null pointer exception occurs when accessing the Merge view when the Options for direct matching UI merge property is not defined.
[36872] A Deadlock happens when executing Simulate match table and modifying the matching configuration at the same time.
[36972] An incorrect result is returned when executing matching on a large number of records and the Max number of records in cluster property is set to a small value.
Release Note 2.3.0
Release Date: October 26, 2018
Updates and enhancements
This release contains the following updates and enhancements:
The EBX® Match and Merge Add-on has undergone extensive updates to ensure compatibility with the EBX® 5.9.0 GA release.
The Bottom view is now hidden by default when accessing the Full view.
Bug fixes
This release contains the following bug fixes:
[33934] An incorrect number of selected values in [List] is returned in the Merge view.
[34607] Executing the Exact match at once unmatched service does not return the correct number of records that have undergone a matching operation.
[34618] An incorrect message is displayed when executing the Exact match at once service with the Execute survivorship option activated.
[34637] An error message is raised when running match table when a Condition for field value survivorship is configured.
[34649] An incorrect result is returned when executing the Exact match at once service with the Auto create new golden in match at once option activated.
[34837] An incorrect result is returned when matching Kanji text with Japanese as the second algorithm.
[34852] An unexpected error occurs when executing the Match at once (unmatched) service.
[34995] An incorrect result is returned when executing matching with a foreign key matching field and the Score calculation option as Real Score.
[35065] All records are displayed when accessing the Light view via the perspective mode.
[35253] If a group has at least two auto-created records, it is not fully collapsed after executing the Match at once service.
Known limitations
When using the Firefox browser, some add-on functionality does not work as expected.
Release Note 2.2.5
Release Date: October 26, 2018
New features
The API's new matchSelection() method allows you to execute matching on a specific selection.
Bug fixes
This release contains the following bug fixes:
[36121] All records are displayed when accessing the Light view via the perspective mode.
[36199] The Cancel and Back to main view buttons do not work when accessing the Merge view via the perspective mode.
Release Note 2.2.4
Release Date: October 12, 2018
Bug fixes
This release contains the following bug fixes:
[36047] A 404 error is returned when opening the Merge view on a WebLogic server.
Release Note 2.2.3
Release Date: October 5, 2018
New features
This release contains the following new features and enhancements:
The
SurvivorFunctionSpecAPI now allows you to return the currentProcedureContext.The Survivor record is now selected from among the active records in the cluster regardless of their scores.
Bug fixes
This release contains the following bug fixes:
[35619] The incorrect survivor record is selected to create a new golden when using Auto create new golden in match at once and Merge all records in cluster.
[35710] The Auto create new golden property is not applied when no default survivorship policy is configured.
[35730] The second algorithm score is empty when using Real score for Score calculation and the second algorithm is applied.
Release Note 2.2.2
Release Date: July 31, 2018
Bug fixes
This release contains the following bug fixes:
[33907] When a Golden record in a cluster is modified and no survivorship policy is defined, its state is set to Pivot.
[34372] The Real score option is not applied when executing matching on a foreign key field.
Release Note 2.2.1
Release Date: July 17, 2018
Enhancements
Memory usage has been enhanced when executing the simulateMatchTable API with SearchContext.
Release Note 2.2.0
Release Date: June 22, 2018
New features and enhancements
This release contains the following new features and enhancements:
Merged records are now taken into account in all Merge operations.
A merged record's target is now updated when the merged record is moved to a new cluster.
The Auto create new golden for single golden option is now applied for the Set golden and Remove and set golden operations.
All built-in Survivorship function on field(s) take into account the Condition for field value survivorship for every record.
A default Survivorship policy is no longer required.
When a Suspect record is manually removed from a cluster, the add-on checks if there are any remaining suspects left in the cluster, and turns the Pivot into a Golden.
The Survivorship function is re-calculated when a Merged record is manually removed.
A new purgeAtOnce API has been added to physically delete all records in the specified Matching state.
EBX® permission settings are now applied to the Merge view.
An error message is displayed in the DEBUG mode only when the Activity Monitoring Add-on is not deployed.
After a cluster has undergone a matching operation, if it contains only Suspects, a Pivot will be selected and the add-on will run Match cluster based on the new Pivot.
A new Run survivorship on clusters table service has been added to execute Survivorship on all existing clusters for Merged records.
A new Update the latest cluster number service has been added to update the Latest cluster number field in the Table configuration.
The RemoveWordFilter filter has been enhanced.
Any redundant auto-created records will become Deleted in the cluster.
The survivorship process can now be applied to clusters that contain records with surrogate matching scores.
Bug fixes
This release contains the following bug fixes:
[32521] The timestamp of auto-created record is not updated after the state is changed as Pivot/Golden or the data is updated.
[32798] A matching operation returns less results than expected when using the Filter by option.
[32864] Users cannot proceed from the merge summary screen when merging a read-only field without applying EBX® permission.
[32883] Users cannot select data of a list field by clicking on the cell in the Merge view.
[33137] A Null pointer exception occurs when executing Match at once in Full mode.
[33581] An unexpected error occurs when modifying a record in the unset state.
Release Note 2.1.0
Release Date: April 20, 2018
New features
The value of an auto-created record is ignored when using the Most frequent survivorship function.
When the Automatically create new golden property is set to Yes, the Pivot record is now re-selected based on the Survivor record selection mode property setting. This process occurs before the new golden record is automatically created.
A cluster cannot have more than one auto-created record.
The Real score calculation strategy is now applied for all algorithms and scoring criteria.
An exception is thrown to avoid an invalid TableContext being passed to MatchingOperations.removeFromNotSuspectWith(TableContext, PrimaryKey).
An auto-created record is always prioritized to be selected as Golden regardless of the Auto create new golden configuration.
Bug fixes
[31842] The Last survivorship policy code field is not updated correctly after merging data in the Merge view.
[31971] The Preview button of a single foreign key inside a list shows the wrong record.
[32040] The Triggered action output variable is set to null after completing a Merge view workflow.
[32091] When moving a golden record into a new cluster, it becomes Suspect (-1).
[32138] In the Merge view, the Preview button does not work on a foreign key list, or the list included in the summary step.
[32193] The Merge view displays incorrectly when the primary key field is hidden in the permission settings.
[32297] The lower view in the Full stewardship screen is not refreshed after running table services.
[32309] A new auto-created golden is not created when On process driven, On simple matching and Embedded at submit are activated.
[32379] An auto-created record that is in the Deleted state is taken into account when running Match at once by group.
Release Note 2.0.1
Release Date: March 28, 2018
New features
The data in the Relationship table is automatically updated upon start-up and data model change.
Bug fixes
[31827] The Accept button does not appear after merging a record in a workflow.
[31829] The Set to Golden and Set to definitive golden steps cannot be by-passed for Merge view in workflow.
[31873] An infinite loading screen is shown when accessing Merge view workflow on a table without the Table configuration.
[31883] A JavaScript error appears when including the Merge view inside an Iframe, or other domains.
Version 2.0.0
Release Date: March 16, 2018
New features
As discussed in the following sections, the Merge view has undergone significant interface updates and improvements.
Navigation improvements
The Merge view now walks you through steps to complete the merge process. The number of steps depends on your data structure and configuration settings. For example, the merge process may impact data not directly involved in the merge due to foreign key relationships with other tables. You will be given the opportunity to address each one of these dependencies.
The bottom of the page includes Next and Back buttons to move one step at a time. The upper-left part of the view contains a navigable dropdown list of all steps required to complete the current merge operation. The list allows you to return to any previously completed step.
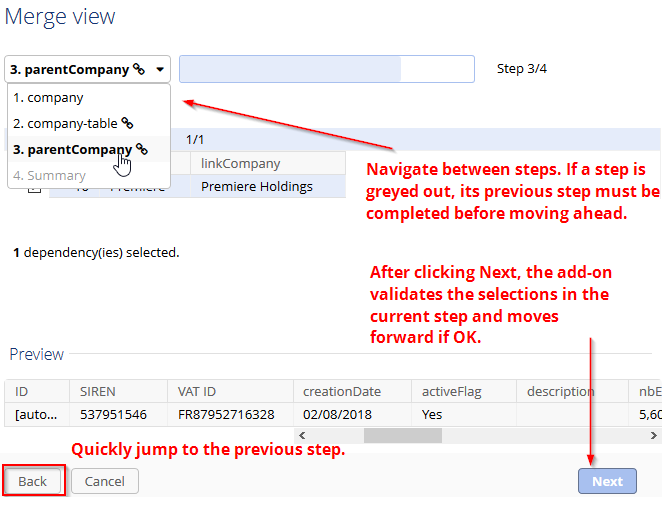
You can lock columns to keep them visible while scrolling through others. Click the ![]() icon when hovering over a column's title. Locked columns stack left to right after the primary key column. Hover over a column's primary key and click the
icon when hovering over a column's title. Locked columns stack left to right after the primary key column. Hover over a column's primary key and click the ![]() icon to display a preview of the record. Additionally, horizontal scrolling is synchronized so that you see the same information in the main table and the preview record.
icon to display a preview of the record. Additionally, horizontal scrolling is synchronized so that you see the same information in the main table and the preview record.
Enhanced value selection
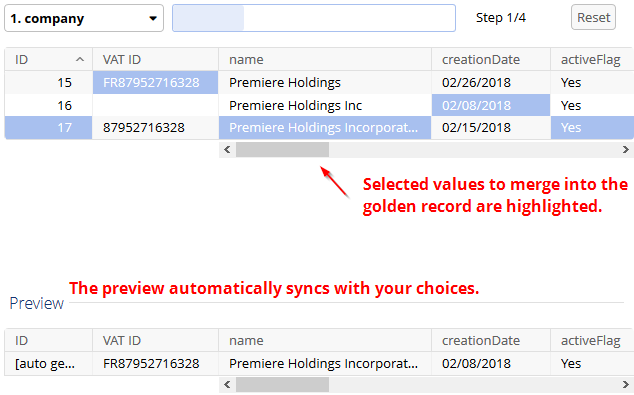
A significant part of a merge operation involves selecting the values you want to be merged into a golden record. The updated interface allows you to select values in the following ways:
Selecting field values: Click a field to select its value for inclusion in the golden record. If you click the first field of a record, the entire record gets selected. You may want to perform this step first to provide a reference record that will be displayed in the preview section. All subsequent selections are reflected in the preview record at the bottom of the page.
Selecting list values: Some fields, such as enumerations and groups, can contain a list of values. You have control over which of these values are included in the merge. To choose the values, click the field's
 icon and select the desired values. The counter shows how many of the possible values are included.
icon and select the desired values. The counter shows how many of the possible values are included.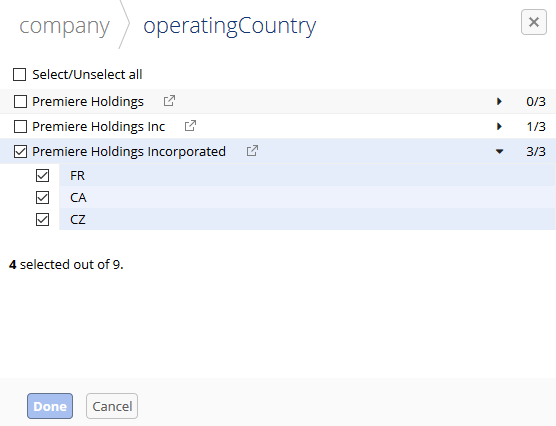
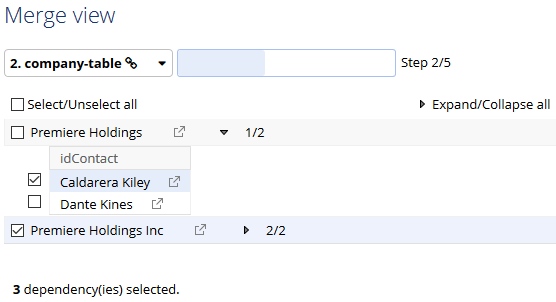
Selecting dependencies: After completing the first page in the Merge view, you will be guided through choosing which dependencies (from related tables) are included in the merge. The add-on presents a different page for each dependency.
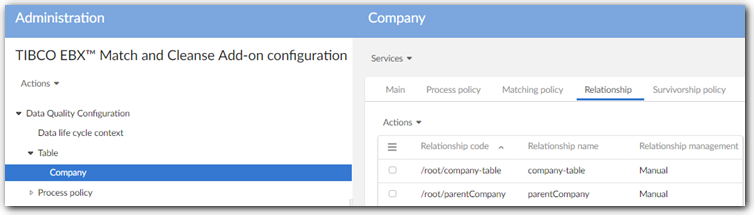
New Relationship tab
This release includes the addition of the Relationship tab. The tab displays information about relationships between a table configured for matching and related tables.
The add-on automatically performs a lookup and populates this table. Administrators can set the relationship management behavior for each relationship.
Additional updates and improvements
This release contains the following new features and enhancements:
A matching algorithm to search Japanese text is now available.
Descriptions have been added to each algorithm in the Matching algorithm table.
Only Unset records become Unmatched when modifying a record with the On modification property set to False.
It is now possible to get Crosswalk results directly without saving them into the crosswalk data set.
A new Narrow search property has been added to the Matching policy table to reduce the memory usage for matching operations.
Bug fixes
[30122] An error occurs when modifying a Suspect record with the On cluster retention for matching suspect property activated.
[30260] An incorrect result is returned when matching with the Exact algorithm and the synonym group contains numeric and special characters.
[30285] An incorrect result is returned when matching a multi-occurrence list with the Exact algorithm and the Ignore case property activated.
[30310] It is not possible to match with a multi-occurrence matching field when using the Filtering field rule and the Exact algorithm.
[30327] It is not possible to match a multi-hop foreign key with the Exact algorithm.
[30616] An error occurs when running the Match at once and Exact match at once operation at the same time.
[30697] The crosswalk matching field cannot be updated when there is an error in the crosswalk matching configuration.
[30701] An incorrect result is returned when matching multi-occurrence foreign key hop with smart synonym.
[30718] Results are inconsistent when executing the Crosswalk service twice.
[30753] An incorrect score is returned when executing the Crosswalk service with at least two matching fields configured.
[31697] The Change the record's state to Suspicious workflow script task only works with the Golden and Suspect states.
[31700] The Change the record's state to Suspicious workflow script task does not work when the Specific tracking info to use property is defined.
[31710] The Check if record is in a given state workflow condition does not work properly.
Release Note 1.13.1
Release Date: February 28, 2018
New features
This release contains the following new features and enhancements:
It is now possible to configure auto create new golden when the primary key fields are not auto-incremented.
Release Note 1.13.0
Release Date: January 31, 2018
New features
This release contains the following new features and enhancements:
You can now configure the Latest cluster number property to define the most recently used cluster number. Additionally, the Reinitialize the latest cluster number service has been improved to cover all datasets.
When a matching operation entails moving a target record to a new cluster, the add-on now recursively moves the target's merged records to the new cluster.
A new Score calculation property has been added to Matching field to provide a new strategy for score calculation and can be applied to filtering field and smart synonym.
The clusters containing only the Pivot and Merged records are now fixed.
The Ignore case property is now applied for Synonym matching.
A new Always apply survivorship property is added to merge records even if their scores are less than the maximum score but greater than the minimum score.
RemoveValueFilter is now optimized, the filtered values are sorted in descending order and you can put a space at the beginning or the end of the string.
Bug fixes
[30289] In some cases the combination of Filter By option with context matching policies can lead to an incorrect result.
[30794] A NullPointerException is thrown when using simulateMatchTable API on a table on which one of the records has a broken foreign key.
[30815] An incorrect score is returned when using simulateMatchTable API on a table without the Daqa metadata.
[30988] An error occurs when executing the Exact match at once operation with the Auto create new golden and On survivorship options activated.
Release Note 1.12.2
Release Date: December 22, 2017
New features
Case sensitive search can now be disabled for all algorithms.
A new RemoveWordFilter class is available for the field filtering feature. Only whole words will be filtered.
A new API is available to listen to the Unmerge event.
Bug fixes
[30159] A blank page is displayed when running the Align foreign key of merge records service on a record with a composite primary key.
[30193] The navigation context is lost after using the Display metadata service.
[30199] An incorrect matching result is returned when running Match at once by group with Business ID and Exact Literal score defined.
[30258] An exception is thrown when using the API to run
simulateMatchTable(SearchContext)on a table without Matching metadata.
Backward compatibility
Due to an API update in this release, all custom code that uses the
MatchingEventListenermust be recompiled and redeployed.
Release Note 1.12.1
Release Date: December 15, 2017
Bug fixes
[29668]
ClassCastException is thrown when matching with a multi-valued Date or Numeric field.[29893] Workflow context is not taken into account when executing the MatchAtOnce operation via APIs.
[30003] An incorrect matching result returns when executing matching on Multi-occurrence foreign key field with the Handle null value matching mode activated.
[30010] An incorrect matching result returns when executing matching on an empty Multi-occurrence foreign key field.
[30011] A NullPointerException is thrown when updating a Matching field record via the Import XML service.
Release Note 1.12.0
Release Date: November 10, 2017
New features
It is now possible to apply the Automatically create new golden property when creating a new record.
It is now possible to apply Survivorship to merge data even if the Golden is preserved for selection property is activated.
You can set a value of up to two billion for the Max nb. of matches per state property.
The Auto-created golden will be retained in the cluster.
The Auto-created DaqaMetaData field will not be reset at any time.
A record will be ignored when applying Survivorship function if its survivor field value is null.
Bug fixes
[29042] An incorrect result is returned when running The Align foreign key of merged records service.
[29054] An incorrect result is returned when Running Match cluster on Pivot record using matching through relation(s).
[29126] Merged record becomes Suspect (-1) after running Match table on its target record with the Modify merged without match property activated.
[29129] An exception occurs when matching with the Auto create new golden and Customize source value for new golden property activated.
[29138] The records' scores are not re-computed against the pivot record after changing algorithm and adding a record in the cluster.
[29158] Executing the Match cluster operation with synonym group configured return incorrect result.
[29198] Executing the Match cluster operation with the Exact algorithm and numeric value on matching field returns incorrect result.
[29205] The surrogate score returned is smaller than Field stewardship min score (%).
[29246] A
NullPointerExceptionis thrown when saving a matching field record with an invalid hop configuration.[29292] Suspect becomes Suspect(-1) when running Match cluster operation with Handle null value for filter by.
[29298] Monitoring is activated when running parallel matching.
Release Note 1.11.0
Release Date: October 16, 2017
New features
You can now execute the Record linking analysis service on a set of selected records.
It is now possible to specify the target data spaces and datasets when executing the Record linking analysis service from the API, or workflow script task.
A new Crosswalk API allows you to select the configured target table at execution time.
You cannot execute Match at once in parallel mode when there is a configured replication in commit mode.
A new cache mechanism has been used to optimize performance.
The relational model is no longer supported in matching.
The SearchDate and Exact algorithm for a date data type or SearchNumber and Exact algorithm properties can be configured for a numerical data type.
The search result has been optimized to remove irrelevant results.
The Handle null value matching property for multi-hop foreign key is no longer supported.
A new API has been added to preload the cache.
The Filter by option in relational tables is now applied for relational matching.
Bug fixes
[26174] An incorrect relational matching configuration screen displays when defining multi-relational matching.
[26521] A JavaScript error occurs, but no error messages display when running Crosswalk with an incorrect configuration.
[26565] Stewardship min score can be set to equal to or greater than Stewardship max score in the Process policyand Matching policy.
[26595] A blank page displays when running the Statistics service on a table that contains Unset record.
[26596] An exception occurs when there is more than one process policy with defined context activated at dataset is applied to all dataspace.
[26598] A blank page displays when users choose more than one record, then run the Reinitialize the latest cluster number service.
[26730] All clusters are hidden after running the Hide cluster service on a record.
[26851] A user should not have the permission to modify system data.
[26858] The close button is hidden when opening a pop-up window.
[27053] An Unset record is hidden in the Apply the same value to the selected record(s) section.
[27070] An incorrect result is returned when users run matching operation with a date list field and use the Exact algorithm.
[27162] An incorrect result is returned when the values of synonym group have the same prefix.
[27163] The value of Fields in Matching meta data is not updated after running the Set at once service.
[27308] The value of Fields in Matching metadata is removed after matching on suspect record.
[27385] An error message displays when running the Group at once service with a void matching policy.
[27425] It is possible to configure a surrogate field with a computed data type.
[27500] A blank page displays when configuring a filter in Matching policy configuration.
[27515] The pivot is displayed after running Future merged records in the Merge view.
[27529] The value of Fields(%) field is not updated in the metadata after running the Exact match at once operation.
Release Note 1.10.1
Release Date: May 9, 2017
New features
The Auto create new golden in match at once is now applied for Exact match at once operation.
Bug fixes
[25674] The progress bar does not update when running Exact match at once with a void Matching policy.
[25685] An unexpected error occurs when merging a record automatically without defining a Survivorship function for the Survivor field.
[25732] The Display record service returns the wrong record in simple matching screen.
[25799] Clicking on the Merged record primary key link under the Merged field logging group metadata displays an incorrect record.
Release Note 1.10.0
Release Date: April 18, 2017
New features
A new Keep not matched records untouched property has been added at the matching policy level to retain the current states of records that do not produce a match. The property only applies to Match at once and Exact match at once operations.
It is now possible to define a condition as a predicate expression that determines whether a field is survived.
When a match results in a single golden, if Auto create new golden for single golden is activated, a copy of the single golden record is automatically created and these two records are put in a new cluster.
The Exact match at once operation with a void matching policy completes even in memory mode.
Release Note 1.9.2
Release Date: March 31, 2017
New features
The performance when using matching with synonyms has been optimized.
Bug fixes
[25093] An exception occurs when a Data life cycle context referring to a deleted dataspace is called during matching.
Release Note 1.9.1
Release Date: March 20, 2017
Bug fixes
[24860] A JavaScript error occurs when accessing the Full matching, Light matching, Simple matching and Merge views through a specific portal.
Release Note 1.9.0
Release Date: March 6, 2017
New features
It is now possible to apply Survivorship when Pivot selection mode is different from New updated.
The Modify merged without match property has been added to the Matching Policy table.
New APIs
The new MatchingStateFactory API has been published.
Release Note 1.8.6
Release Date: February 23, 2017
Bug fixes
[24366] It is not possible to modify the To this date input parameter while configuring a Deprecated cleansing procedure.
[24368] When running Deprecated records cleansing, the Current record and Next record display incorrectly in the Manage manually screen.
[24373] The Apply the same value to the selected record(s) field is blank when the input parameters include special characters.
[24514] The
ExcludeMatchingFieldFilteris applied regardless of whether the Exclude records from matching property is configured in the Matching policy table.
Release Note 1.8.5
Release Date: January 23, 2017
New features
When a field's score is lower than the configured Stewardship min score, the add-on matches with a surrogate field instead of using the defined matching field.
The Match at once operation will ignore the void matching policy to proceed, provided that it does not run in memory mode.
It is now possible to run all records' services with the void Matching policy.
When a match is executed on Suspect records with the On suspect record retention option deactivated, all Suspect (-1) records are moved to the Unmatched cluster.
New APIs
It is now possible to get the Pivot record when using
MatchingRecordFilter.A new API was added to execute Exact match at once on a record with the Automatic merge option activated.
Bug fixes
[23732] The Exact match at once service still functions normally, although both In memory and Is forced to void options are activated.
[23734] It is impossible to input integer values in the second input parameter of the Deprecated records cleansing procedure.
[23801] Running Crosswalk with SearchDate algorithm activated returns an incorrect result.
[23808] The Merged record is still modifiable after you manually replace a missing field value in the cleansing screen.
[23873] It is impossible to export the statistics information into an Excel file in Full or Light view perspective screen.
[23874] The Hide state filter and Display cleansing buttons options in Full or Light view perspective are not applied.
[23908] Running Match table on a Suspect does not change the best record's state to Pivot with the On survivorship option deactivated.
Release Note 1.8.4
Release Date: December 16, 2016
New features
The Unset Golden recursively operation is now available on Golden records.
When using a table in more than one Crosswalk matching field, it must occupy the same location in each field. For example, a field from a Party table may be defined first in one Crosswalk matching field. If you use a different field from the Party table in another Crosswalk matching field it must also hold the first position.
When modifying a merged record, the survivorship policy is applied to merge data to its Pivot or Golden target record.
Filtering record rule is now applied when matching through related tables.
New APIs
It is now possible to filter records when searching with
SearchContext.An API method has been added to simulate a match table operation with
TransientRecordContext.Two APIs have been added in
MatchingEventListenerto record whenever a new Golden or Pivot record is automatically created.
Bug fixes
[23271] The Handle null value options are not taken into account when executing relational matching.
[23655] When modifying a Merged record, the Most recently acquired survivorship function does not work properly.
Release Note 1.8.3
Release Date: November 18, 2016
New features
It is now possible to configure Matching policy context using a foreign key raw value.
The same number of crosswalk fields has to be used and they must belong the same target table.
When running crosswalk, the target table selection has been optimized to be more user-friendly.
Bug fixes
[23090] An incorrect score is returned when running crosswalk with different Stewardship min score.
Release Note 1.8.2
Release Date: October 28, 2016
New APIs
It is now possible to launch Crosswalk using the API.
The
simulateMatchTable(RecordContext)API was enhanced with the ability to compare records.
Release Note 1.8.1
Release Date: October 12, 2016
New features
A non-empty matching field context can now be defined.
A Match at once operation can be performed simultaneously on groups of data.
It is now possible to select the configured target table at execution time in crosswalk.
A Bidirectional not suspect with property has been added to the Process policy table to save the Pivot record information into the metadata's Not suspect with list on the Suspect record.
The Switch pivot and Not suspect services are now available on Suspect records in the Merge view.
Bug fixes
[22178] An incorrect score is returned when running matching using two algorithms with foreign key or foreign key hops matching fields.
[22302] An incorrect result is returned when running Match at once with the Auto create new golden in match at once option active.
[22456] An exception is thrown when running Match at once using the In memory and Matching policy context.
[22560] An incorrect result is returned when running Match table with the Funneling matching option activated and Handling null value matching checked.
Release Note 1.8.0
Release Date: September 9, 2016
New features
Matching
Clean up merged field log is a newly added service available on all states (except Merged and Deleted) to delete saved Merged field logging in metadata.
It is now possible to view relation records in the Merge view to determine whether the current suspect record is a duplicate.
The Merge view can be launched by selecting records in the tabular view and executing the Merge records service.
It is now possible to apply Automatically create new golden to Match at once operations.
The Foreign key property is now available in Matching field configuration records. This property allows you to define a path to another foreign key field that you want to run matching on by creating hops to navigate the relationships.
The Activate monitoring option is now available when configuring a table and allows you to determine whether the EBX® Activity Monitoring Add-on saves Match at once execution status.
The Match at once (on clusters) service is available in the full matching view to execute the Match cluster operation on selected clusters.
You can now view matching statistics and export them to an Excel file.
It is now possible to select a matching policy context by using a Java class.
A merged record will be moved to its target's cluster when executing the Add into cluster operation.
The Add into cluster service is now available on merged records.
The Ignore case for Exact match property has been added to allow you to ignore case when matching.
Null values are now taken into account when executing matching with any algorithms.
SearchDate and SearchNumber algorithms are now available.
The Simulation result output parameter has been added to the Simulate match table script task to return search results formatted in JSON.
Null values are now taken into account when applying Filter by.
You can now clean up the list of Not suspect with.
The Item in group table is now visible by default.
It is possible to merge records with a score of -1 in all merge operations.
It is possible to match fields under multi-value groups.
The Check EBX® Match and Merge Add-on configuration service validates the Source field value when the Most trusted source mode is selected.
The new Smart synonym matching option allows you to use matching with the advanced synonym mechanism.
Cleansing
It is now possible to manually fix a set of records.
The Save and apply fix to next button has been added to manual fix cleansing views.
The field value can be replaced with the derived value in the preview record screen.
Crosswalk
It is possible to match on multiple fields in crosswalk.
The Maximum number of results property has been added to the Crosswalk process policy table to set a threshold on the number of records saved in the Crosswalk additional result table.
Bug fixes
[19054] Records (except Golden and Pivot) have a List of not suspects value in metadata after running the Force records to merged service.
[19253] There are some matching services that cannot be run by read-only users.
[19289] Descriptions of cleansing procedure records with an [ON] prefix are not translated into French.
[19294]To be matched and Unmatched states are not translated into French in Set at once screens.
[19623] All predefined clusters display when running the Add into cluster service.
[19658] An execution procedure's state is terminated before the transaction finishes.
[19692] An exception is thrown when running Match table on suspect records with null score value.
[20336] A record with a score below the max score threshold becomes a survivor when running matching with was golden selected for the Survivor record selection mode property.
[20358] Merged records with a score of '-1' display after running Exact match at once with Execute survivorship and Filter by enabled.
[20397] Session times out when running Match suspicious in the data workflow.
[20399] Services on the State filter button do not work properly in Light view when accessed from a workflow.
[20401] The Select all check box does not work properly in set at once screens.
[20564] The suspicious record is selected as the best record in the simple matching view when Best record selection mode is set to Was golden.
[20755] It is not possible to use the scroll bar to view the whole Display record screen in Simple matching view at Submit time.
[20842] An exception occurs after creating a new record with the foreign key matching field containing render label.
[20916] A redundant scroll bar displays when running the Create new golden service on Internet Explorer browser.
[21142] The matching policy with defined workflow context is not applied when running services in Simple matching view under workflow.
[21182] The golden record becomes golden in cluster 001 when there is no record matched.
Release Note 1.7.11
Release Date: July 8, 2016
Bug fixes
[21265] Matching services are disabled in all the dataspaces of a slave or hub instance.
[21350] The incorrect result is returned after running matching on a record when the No match records when same source property is set to Yes.
Release Note 1.7.10
Release Date: May 19, 2016
New features
Additional Pivot record selection modes are now available.
Match at once full mode and Match table on suspect have been optimized to get more consistent results.
The cluster can be saved when matching suspect records using the new On cluster retention for matching suspect property.
The states of records in clusters that contain only Suspect or Pivot can be changed to Golden when running Match at once in Full mode.
Error messages are logged in Debug mode when the table is not configured and has only Daqa metadata.
The log has been enriched to specify an error when migrating a data model if the dataspace or dataset is deleted.
Match at once full mode now can be executed when there is no record in the corresponding state.
The record will not be moved into a cluster when the No match records when same source property is set to Yes and at least an record (except Merged and Deleted) from the same source already exists in the cluster.
Matching run on a pivot or golden record, when the Merged record is recycled option is on, causes the add-on to include previously merged records in the match operation.
When running matching on a golden record, it remains in its current cluster if there is no potential duplicate record found.
Bug fixes
[19982] An exception occurs when importing records with Use matching activated and On suspect record retention set to No.
[20073] An exception occurs when using
RemoveValueFilterand the value of the matching field is null.
[20373] Services on suspect record are hidden in the Merge view when On matching process is set to No.
[20419] The field values of golden or pivot records cannot be reverted to the previous values after running the Unmerge service.
Release Note 1.7.9
Release Date: March 18, 2016
New features
When executing Match at once full mode and Match table operation on suspect record, the record will be not match with the records in the same its cluster.
Bug fixes
[19666] Golden records that have scores equal to the min score are not matched after running the Match table service on suspect records.
Release Note 1.7.8
Release Date: February 4, 2016
Bug fixes
[19175] Matching's Purge at once services have extended execution times.
[19176] Records with scores lower than the min score threshold are returned.
[19221] A record gets successfully added into the new cluster even when it's score is '-1'.
[19337] It is not possible to return to the cluster view after running the Match suspicious service while in a perspective.
Release Note 1.7.7
Release Date: January 18, 2016
Bug fixes
[18690] The progress bar does not update and the Cancel button is inactive for a long period of time when executing the Match at once service with the Filter by property configured.
[18682] An error displays when creating a duplicate record in the workflow when the value of the Embedded at submit field is set to Yes.
[19018] An incorrect score is returned when searching on more than one field and when a field has a score lower than the minScore threshold.
Release Note 1.7.6
Release Date: November 25, 2015
Bug fixes
[18346] Records with invalid state exist in cluster after running Unmerge service on golden or pivot record.
Release Note 1.7.5
Release Date: November 19, 2015
New features
It is possible to modify merged record by setting the Merged record is recycled property in the process policy.
The survivorship policy now has new survivorship record selection named Was golden. With this selection mode survivorship record will be selected amongst Was golden records and current Golden. If many records with the Golden or Was golden identifier exist, the Most recently acquired record is used.
The tooltip and user guide for field Golden is preserved for selection now is enriched.
It is now possible to use a survivorship policy when running an Exact match at once service.
An Exact match at once service can now be executed in a single in-memory transaction to speed up the matching process. However, if any exception is thrown, all results will be lost.
New API
It is now possible to change the import mode value for a given process policy. See the
MatchingConfigurationOperations APIfor more information.
Release Note 1.7.4
Release Date: November 3, 2015
New features
The Profiling and Cleansing buttons can now be displayed or hidden in a workflow by setting the Display cleansing buttons property in the workflow configuration.
The Accept button can now be displayed or hidden in a workflow by setting the Auto complete property in the workflow configuration.
Bug fixes
[17840] It is not possible to access matching services in closed data spaces.
Release Note 1.7.3
Release Date: October 9, 2015
New features
Matching based on a multi-value field inside a terminal group is supported.
The source field's value in the newly created golden record can be customized by using the Source value property configured in matching policy.
Bug fixes
[17566] An empty result is returned when searching with a foreign key field using a programmatic label.
[17560] When you launch Profiling from the Full Data Quality Stewardship service, it raises a null pointer exception and results in a blank screen.
Optimization
Matching process has been optimized.
Release Note 1.7.2
Release Date: September 16, 2015
New features
EBX® Match and Merge Add-on has been adapted to fulfill requirements from EBX® Insight Add-on and EBX® Add-on for Oracle Hyperion EPM.
Release Note 1.7.1
Release Date: August 24, 2015
Bug fixes
[17418] An exception occurred when running matching on a FK field. The Localized label property is empty.
Release Note 1.7.0
Release Date: July 31, 2015
New features
Matching
You can now execute a Match table operation on a suspect record. When a record matches the suspect, it is considered a duplicate if its new score is higher or equal to its current score.
Match at once operations can now use a Full mode option to run a match against every record in the table, regardless of any existing configuration settings. This means that any property values which make up a "base" configuration are ignored. The number of matches executed is n*(n-1) for n involved records. This improves matching result relevance, but increases execution time.
The Matching policy table now includes a Filter by property that enables you to filter records before executing fuzzy matching. When faced with a large volume of data to match (millions of records), a good practice is to identify criteria on which the data can be grouped. Fuzzy matching is then applied on a suitable subset of records rather than on the whole table.
Matching view
When displaying a record's matching metadata, the merged record's target is now displayed through a user-friendly pop-up rather than embedded in a frame.
In a workflow, whether in full or light matching user tasks, the State button filter can now be hidden or displayed by setting a property in the workflow configuration.
Simple matching view
In a workflow (simple matching user task), the Keep in workflow service can now be hidden using a property in the workflow configuration.
The Cluster view button and the pop-up menu at the level of the suspect record can be hidden using a property in the configuration.
A new Display record service displays the selected duplicate record through a pop-up. This helpful feature allows you to make a decision on the record before the next stewardship operation.
Merge view
The Cluster view button and the Suspect record drop-down menu can be hidden using configuration options.
A new button allows you to hide/show fields not used in the merging process such as associations, computed attributes, selection nodes, etc.
Field values that aren't an exact are now highlighted in light coral color.
Hook
You can now configure an event listener java class at the table level. This allows you to add bespoke treatment when a matching state value change occurs on a record.
Release Note 1.6.2
Release Date: June 29, 2015
New features
You can now match on a field of any simple type.
Improvement
When using property Golden is preserved for selection, the Pivot record selection mode will prioritize records identified as was golden and records with Golden state existing in the cluster.
Release Note 1.6.1
Release Date: June 17, 2015
New features
Matching
In Simple matching workflow, when re-opening the simple matching task once the record is no more in a supicious state, the UI will adapt in order to redirect the user on the accurate screen.
Release Note 1.6.0
Release Date: June 10, 2015
New features
Matching
You can now separate the UI of Matching and Cleansing services by using the properties in Table configuration. For example, in the (Full) Data quality stewardship view, you can create a configuration that displays only Matching services, only Cleansing services or both.
The relation match feature can now apply to multiple relationships. For instance, the Address and Sales tables each have a relationship to the Party table. You can run a matching operation against the Party table by applying two matching configurations based on the relationships from the Address and Sales tables.
Relationship records involved in a merge process can now be fixed (merge, deletion, alignment). For instance, an Address table has a relationship to a Party table. At the time the parties are merged, you can merge, delete and realign the related addresses.
A new matching policy Is forced to void property allows you to short-circuit matching execution. This makes it possible to define an active matching policy that does not actually execute. This mechanism is useful when many matching policies are defined and depend on different contexts. For certain contexts, you may want to short-circuit matching.
When configuring a table, you no longer need to refer to a dataspace and dataset. Table configuration now relies on the list of data models to reach the desired tables.
You can now configure automatic execution of a workflow depending on the matching operation's result (per state value of the matching record: golden, pivot, suspect, etc.) or in the case of survivorship execution.
The groups of synonyms can now be arranged in a hierarchy mode. When matching uses the synonym mechanism, all groups of child synonyms can be used to look for a synonym.
The data views used for matching can now be configured by user-profile: full view matching up, full view matching bottom, light view matching, merge view matching, simple matching view.
A new option-Automatically align foreign keys-is now available in the merge UI. This option allows you to automatically execute alignment of foreign keys after the merge. The existing relationships to the merged records are updated to link to the related pivot or golden record.
In the simple matching view, you can now hide the suspicious record in the list of duplicate records.
On a table's tabular view, you can execute the Display metadata service on a record. This service provides you with the full matching and cleansing metadata.
You can now configure a null value for the Exclude records from matching feature.
The Merge view and Back to table view buttons are now displayed in the matching view in a workflow procedure.
Cleansing
New cleansing procedures:
Foreign key fixing - The broken foreign keys are automatically identified and a UI allows you to fix the defective relationships.
Deprecated records - This procedure allows you to get the list of the deprecated records (based on a time configuration) and decide to delete or keep the records.
Unused records - This procedure provides you with a set of rules to detect the unused records and process them (delete, keep, etc.). An unused record is not referenced by any other records in the repository.
The results from cleansing procedure execution (profiling and fixing) can now be kept over time to use in data analytics.
Crosswalk
The crosswalk feature is a new domain in the EBX® Match and Merge Add-on. It allows you to create a cross-reference table based on a matching policy executed over many tables. For instance, the Client, Party and Customer tables have duplicate records and you want to create a cross-reference table that shows how the same record is represented in multiple tables. This feature is not used to merge the records but provides a convenient place to view the linked records.
Release Note 1.5.8
Release Date: April 27, 2015
Bug fixes
[15351] Matching policy code meta-data is not updated correctly when using API:
MatchingOperations.matchTable()with workflow context.
Release Note 1.5.7
Release Date: March 17, 2015
Bug fixes
[14810] Exception when using API:
MatchingOperations.simulateMatchTable()to search with Date field.[14948] Matching policy code meta-data is not updated correctly when created/updated records become Golden after no duplicate matching.
Release Note 1.5.6
Release Date: January 26, 2015
New API
Ability to define the workflow context when simulating matching.
Release Note 1.5.5
Release Date: December 8, 2014
New features
Ability via the UI to merge without changing the records states.
Release Note 1.5.4
Release Date: November 10, 2014
New features
Add an algorithm to enable matching in Chinese.
New Java API are available.
Bug fixes
[13149] Matching context is not used correctly when matching context field is a Boolean field.
Release Note 1.5.3
Release Date: October 10, 2014
New features
Java API are available to run match at once, group at once and set at once operations.
Release Note 1.5.2
Release Date: September 30, 2014
Bug fixes
[12599] Java script error occurs after running Show cluster, State/Unmatched in group, State/To be matched in group in the light view.
[12587] Exception occurs after running Align foreign keys of all merged records/merged records with multi-value foreign key field.
Release Note 1.5.1
Release Date: September 12, 2014
Bug fixes
[11137] Log out screen is displayed after running Remove and set golden service on greater than or equal to 4 suspect records.
[12481] Exception occurs when using Not match when same source.
[12526] Exception when searching with null foreign key using Exact algorithm.
Release Note 1.5.0
Release Date: August 29, 2014
New features
Data cleansing
The EBX® Match and Merge Add-on integrates a new functional domain to manage data cleansing. New UI operations and an API are available to declare and customize a data cleansing procedures portfolio.
A predefined cleansing procedure that checks for and fixes missing values in tables is provided.
An API allows you to develop any bespoke cleansing procedures that are integrated automatically in the EBX® Match and Merge Add-on UI.
New service available for suspect records
A new service (Remove and set golden) is now available to handle suspect records. When running this service, the record is set to a golden state and moved to the golden cluster. The cluster is not modified.
New services on the Make golden action in the simple matching UI
The Make golden and force all records to merged service forces all suspicious records to the Merged state with their target record linked to the golden record.
The Make golden and force selected records to merged service forces only records that have been selected in the list of suspicious records to the Merged state.
Record selection on the Simple matching UI
It is now possible to configure a record selection policy to automatically identify the best record among the list of the potential duplicate records. Stewardship can be executed on this best record that is considered the pivot record.
Matching fields
It is now possible to manage the field order used in a matching policy. It is useful to prioritize the fields that are the most important in the matching execution, in particular when the funneling mode is activated.
Custom distance algorithms
It is now possible to create custom distance algorithms.
New matching metadata
Date of last operation code gives the matching last execution date on a record.
Last survivorship policy code gives the last survivorship policy executed on a record.
Release Note 1.4.0
Release Date: April 1, 2014
New features
Relation match
It is now possible to run matching on tables that have indirect relationships. For example, a table Address has a relationship to the table Party. Matching can be configured to de-duplicate the parties based on a policy defined on the Address. The relation match works also through join tables. Based on the previous example, a join table Party-Address is used to link the Party with the Address. The matching on Party now refers to the matching of Address through the join table Party-Address.
A new UI service Display relation records allows showing the records involved in the relation match. For instance, applied to a Party record, the Display relation records gives all the Address records for this party.
Synonym management
A repository of synonyms can now be configured. If a field value in the suspect record does not match with the pivot, then the synonym values are used to find new matches rather than the initial value in the suspect field. The first positive match is used to get the final score.
Match inside list of values
It is now possible to match within lists. Two lists of values match when at least one value is exactly the same in the two lists. For instance (John, Carl, Paul) will match with (Frank, Theo, John).
UI merge improvement
A new button Cluster view allows one to get the list of the future merged records corresponding to the current selection for the merge.
New UI service
Show cluster for merge. From the full matching view, a selected cluster containing a pivot record can now be loaded in the bottom panel of the view so that the Merge button is directly available.
Release Note 1.3.1
Release Date: January 3, 2014
Bug fixes
[9162] After a match at once, the simple matching cannot launch a workflow until the user logs out.
Release Note 1.3.0
Release Date: December 17, 2013
New functionalities
Display metadata. This service opens a pop-up with all the matching metadata of the current record.
Metadata Last process policy code and Last matching policy code has been added.
New partial merge options have been added: Keep unmerged record(s) as suspect, Set golden and set unmerged record(s) as not suspect with, Set golden and set unmerged record(s) as suspicious.
No merge option has been added to cancel the merge procedure.
New services have been addeed: Exact match at once (to be matched) and Exact match at once (unmatched). These services apply a fast matching policy to group records in large set of data.
New operation Match suspicious has been adeed to allow the matching of a suspicious record.
New operation Create new golden has been added for pivot records. This service opens a pop-up to create a new record that is considered as the pivot. The former pivot record becomes a suspect and the merge view is displayed automatically. If all primary key fields are auto-incremented, then the new golden is created automatically and the merge view is displayed.
Enhancement of existing operations
A score is now displayed in the simple matching view to get the matching results of a potential duplicate against a suspicious record.
Progression bars are now displayed for the services match at once and set at once.
During a merge, when a matching field does not match, its icon is displayed in red.
Configuration
Data life cycle context
The new property dataset is applied to any data space has been added.
Table
The new property Disable matching trigger deactivates the matching trigger and allows the direct use of the EBX® Match and Merge Add-on API. This implementation is useful when the EBX® Match and Merge Add-on triggers must coexist with other trigger actions, such as when integrated with the EBX® Insight Add-on.
Matching policy
The following new properties have been added to the matching policy:
Automatically create new golden, to force the creation of a new golden record in the case of a match. This feature is only available if the system can automatically supply the primary key of the new record. That is, if an auto-incremented primary key is used.
No match records when same source, to deactivate matching when two records come from the same source. The source is configured at the table level.
Process policy
The following has been added to the process policy:
Property to configure whether or not EBX® permissions are applied to a merge performed through the user interface.
Property to configure bespoke data views for Full view matching up, Full view matching bottom, Light view matching, Merge view matching and Simple view matching.
Configuration of which operations the user can execute to manage a suspicious record in the service Match suspicious.
Configuration of direct matching merge through the user interface, independant of the configuration of the user interface merge at submission. This allows specifying which operations the user can execute to manage the pivot and suspect records during the merge procedure.
API
New API has been added for simulate match table, which can be applied on either a record or a set of search criteria.
Other enhancements
The EBX® Match and Merge Add-on operations available in EBX® views have been simplified. There are now only two operations, full view and light view. The full view operation is displayed at the table level to allow matching that is applied on all records. The light view operation is displayed at the record level. It is now possible to select a record and directly open the light view on the corresponding cluster.
The tab Create view in full view and light view has been removed. Creation is now handled at the level of regular EBX® views. These views can be enriched with embedded inline matching at submission time to detect potential duplicate records on the fly, a feature already available in version 1.2.0.
Release Note 1.2.1
Release Date: September 19, 2013
Bug fixes
Record creation is blocked when configuration is erroneous.
Programmatic label renderers on foreign keys trigger an exception when used during matching operation.
Release Note 1.2.0
Release Date: September 17, 2013
New operations
Embedded matching. This feature allows to launch the data stewardship after the submit button directly.
Unmerge.
Reinitialization of the latest cluster number.
Enhancement of existing operations
Suspect record retention strategy can be configured. When the retention strategy is not applied, the suspect records that no longer match with the pivot record are pushed out the cluster.
In the merge UI, the matching fields are indicated with a dedicated icon. A bubble help gives the name of the matching algorithm used.
A matching policy context can now define a list of fields contexts (previously two fields were available only).
Configuration
A survivorship policy can be configured by contexts of dataspace and dataset.
A matching policy can be configured by contexts of dataspace and dataset.
A matching policy can be configured with matching thresholds that overwrite ones stemming from the process policy.
A matching field can be configured to exclude records.
A matching field can be configured to filter field values before the match execution.
Other
The add-on runs on the tables that are persisted in the relational mode. Some limitations must be taken into consideration compared to the semantic mode.
Doublemetaphone algorithm has been improved in order to produce matching scores more accurate.
Release Note 1.1.0
Release Date: June 3, 2013
New operations
Group at once (unmatched) and group at once (to be matched). These operations are used to group 'unmatched' or 'to be matched' records in order to apply the match operation on the scope of a group. Two operations group collapse (unmatched) and group collapse (to be matched) are available to undo the groups.
Match at once (suspicious).
Set definitive golden on suspicious and unmatched record.
Add into cluster on a suspicious record.
Not suspect with to decide that a record is no longer a suspect against a pivot record until a new scoring reaches a certain level of similarity or until the property On not suspect with is set to False in the related process policy.
Enhancement of existing operations
Match at once on the scope of groups of records collected by the operations group at once (unmatched) and group at once (to be matched).
Add into cluster allows to move the record into a new cluster (creation of the cluster).
Configuration
A matching policy can be configured for the operations match at once.
A matching policy can be configured for the operations group at once.
A matching policy can be configured for a workflow context.
A matching policy can be configured with fields values that exclude records from the matching.
Matching algorithm and scoring
Funneling matching.
New matching algorithms (DoubleMetaPhoneLevenshtein, Soundex).
Golden preserved for selection is available. Then, the pivot record selection mode will keep in priority a was golden record if it exists in the cluster.
New matching algorithm Exact that allows to force an exact matching (not fuzzy).
Matching policy with Exact literal score. When more than one Business ID fields is configured, two records are considered as Suspect if any of the Business ID field value is equal (in the previous version, two records are considered as Suspect if all of the business ID fields values are equal).
When a survivor field function returns more than one value, the record with the latest timestamp is used in priority (in the previous version it is a random selection).
Workflow
Script: change state of a record to suspicious.
Script: simulate the match table operation. The result is a list of all records that match but without changing their states.
Condition: check if a record is in a given state.
User task: the existing Simple Matching user task is enriched with several new properties (see Java doc directly).
User task: merge view.
API
Java API are now available to integrate the EBX® Match and Merge Add-on with external systems.
Release Note 1.0.0
Release Date: April 8, 2013
EBX® Match and Merge Add-on finds duplicate records in a table and its relations. Based on a user configuration of fields to match in a table, the add-on automatically identifies which records are suspected duplicates.
A rich EBX®-integrated end-user interface provides all the services required to govern duplicate records. Users can reject or merge duplicate records in order to build an accurate record, also known as a golden record.
Known limitations
The EBX® session automatically times out for security reasons, meaning the user is logged out after a certain period of inactivity. In some situations, this can result in the EBX® login screen opening inside a frame of the EBX® Match and Merge Add-on views. To rectify this situation, the user must select any action outside the frame to display the full EBX® login screen. This limitation has no impact on data integrity or security, however, it is a known ergonomics issue.
The EBX® Match and Merge Add-on is currently only available in English. The French translation will be added in a future version.