
Working with Python models
This page explains how Python models can be used in TIBCO ModelOps Score Data Processing step of scoring flows. Details that apply to all models can be found on the Working with Models page.
Contents
Overview
Two types of Python models are supported in TIBCO ModelOps:
- Python Script Models
- Python Binary Models
For both types, input and output schemas have to be bound before they become available in the Score Data Processing step (see Binding Schemas to Models).
Python Binary Models
Python scikit-learn models can be persisted for future use after training. Scikit-learn Pipelines trained and persisted using joblib.dump can be used for scoring data in the Score Data Processing step. Adding dependencies to Python binary models does not apply and has no effect. The loaded pipeline's predict method is invoked to score input data.
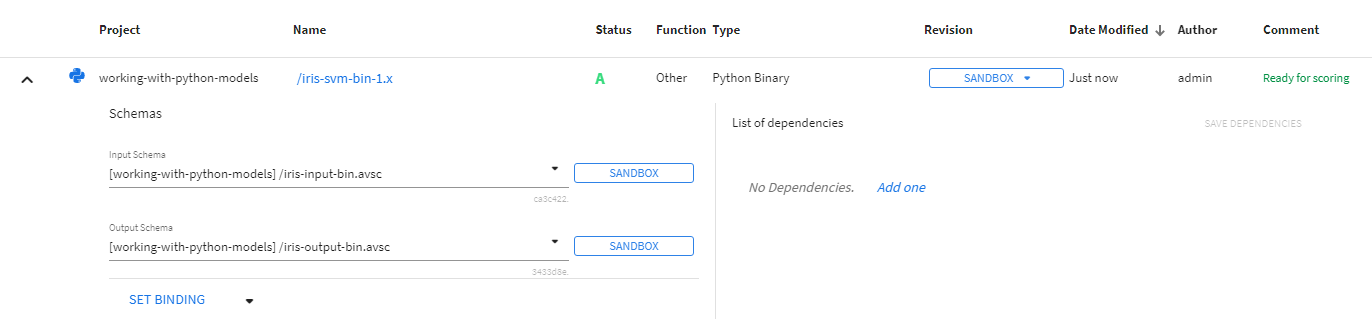
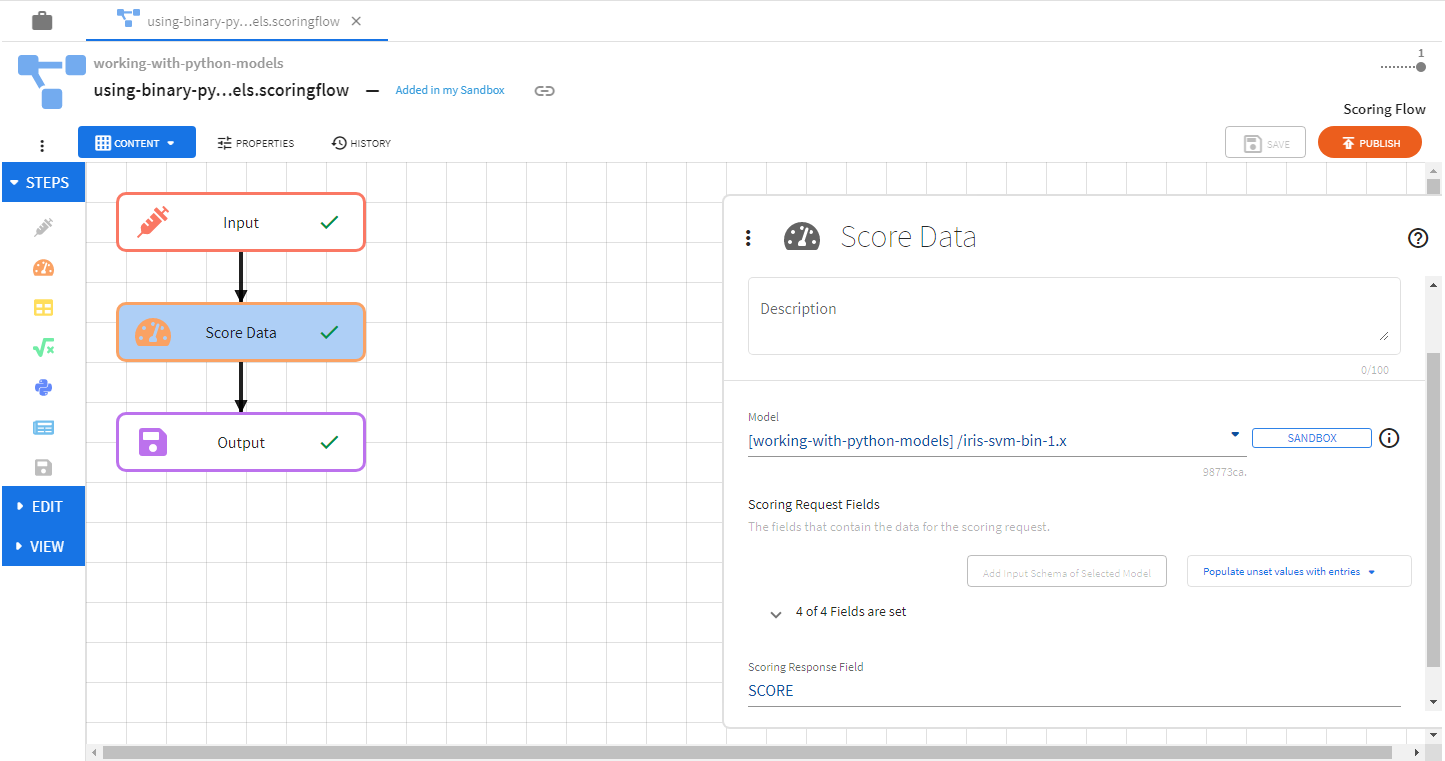
Python Script Models
You can also use Python scripts as models to be used for scoring data in the Score Data Processing step. Artifact dependencies can be added to a Python script model through the Models tab on the TIBCO ModelOps UI.

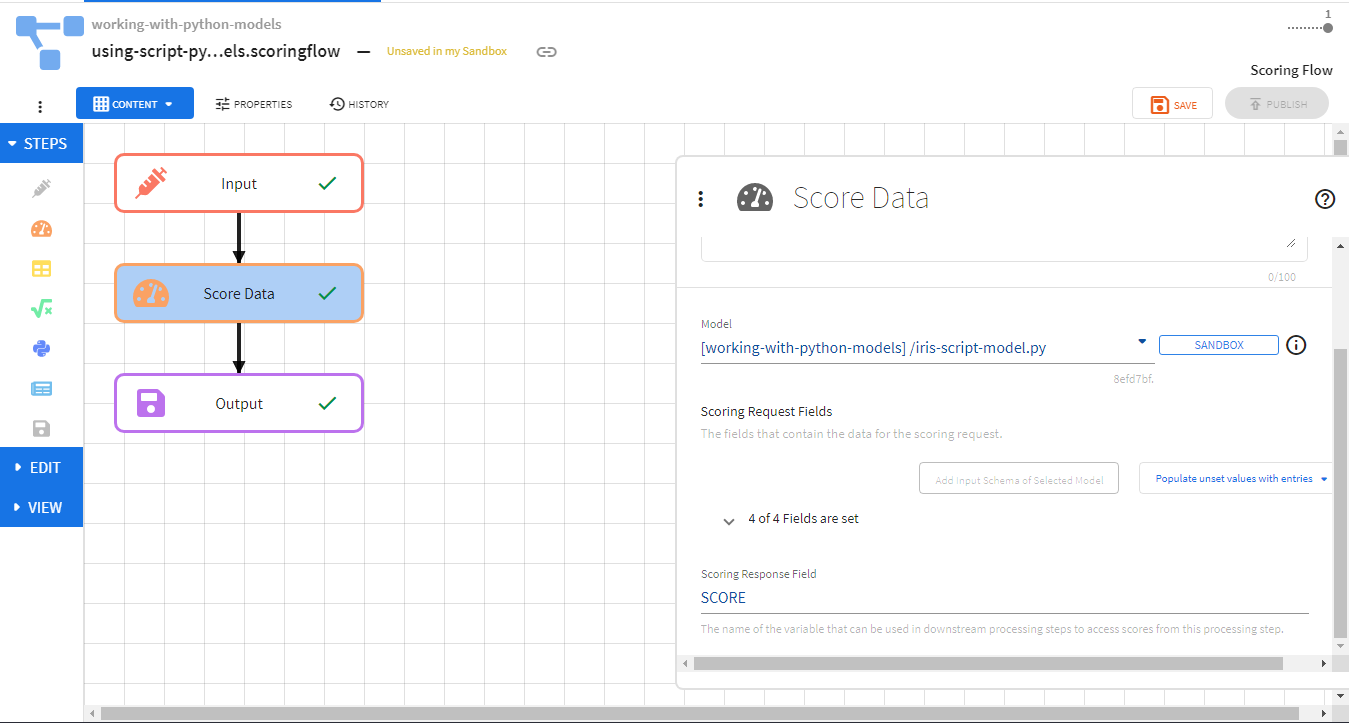
Script
The Python script to be used as a model needs to contain exactly one instance of a scoring function. The scoring function is a Python function that implements the following signature (see Function Annotations). TIBCO ModelOps framework uses this signature to identify the function to use for scoring data.
def function_name(data: np.ndarray, column_names: Iterable[str]) -> Tuple[np.ndarray, Iterable[str]]
Input data to be scored is passed as a numpy ndarray into the first parameter. The column names for the input data are passed as a string iterable into the second parameter. The function is expected to return a tuple with two values. The first value is expected to contain scores as a numpy ndarray. The second value is expected to contain column names for the scores as a string iterable. There are no specific restrictions on the name of the scoring function; it can be any valid Python function name. If the Python script (or its dependencies) does not contain a function matching the prescribed signature or has more than one instance, model loading fails.
For example:
import numpy as np
from typing import Iterable
from typing import Tuple
# do some useful model load-time initialization
def score(data: np.ndarray, column_names: Iterable[str]) -> Tuple[np.ndarray, Iterable[str]]:
# scoring logic goes in this function
score_data = None # replace with np.ndarray
score_columns = None # replace with column names
return score_data, score_columns
# other useful Python script model code and functions
Package Dependencies
If certain Python packages are required for the Python model script to run successfully, those requirements can be specified through an artifact named requirements.txt added in the List of Dependencies that follows the standard pip requirements file format. Specifying the package dependencies can be skipped if no packages outside of the Standard Python library are needed.
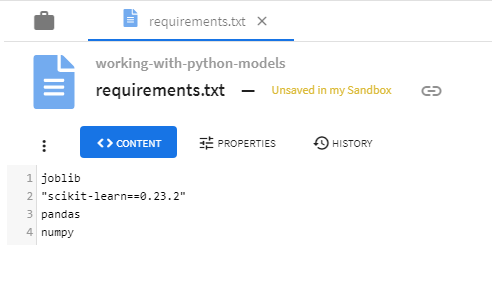
Artifact Dependencies
If certain artifacts are required for the Python model script to run successfully, those files can be added to the List of Dependencies. Specifying artifact dependencies is optional.
For example, the following Python code would access the iris_svm.x and lookup.json artifact dependencies described in the figure above:
import json
import joblib
import numpy as np
import pandas as pd
from typing import Iterable
from typing import Tuple
# load and use iris-svm.x
model_file = "iris-svm.x"
user_model_object = joblib.load(model_file)
lookup_table = None
# read & load look up table from JSON file
with open("lookup.json", "r") as json_file:
lookup_table = json.load(json_file)
# now use one of those artifacts while scoring
def score(data: np.ndarray, column_names: Iterable[str]) -> Tuple[np.ndarray, Iterable[str]]:
y1 = user_model_object.predict(data)
y2 = user_model_object.predict_proba(data)
y3 = pd.DataFrame([[x[0], *x[1]] for x in zip(y1, y2)]).values
return y3, None
# other useful code ...
Data Type Mapping
While receiving data into the Score Data Processing step (for scoring with a Python model) and sending data from the Score Data Processing step (to downstream steps), the mapping between Python data types and supported field types in Scoring Pipelines is as follows:
| Open API Type | Open API Format | Python Data Type | Comments |
|---|---|---|---|
| boolean | bool | ||
| integer | int32 | int | 32 bit signed value |
| integer | int64 | int | 64 bit signed value |
| number | double | float | Double precision floating point value |
| number | float | float | Single precision floating point value |
| string | str | UTF 8 encoded character data | |
| string | Not supported | Base64 encoded binary data (contentEncoding=base64) | |
| string | date | Not supported | RFC 3339 full-date |
| string | date-time | Not supported | RFC 3339 date-time |
| array | Not supported | ||
| object | dict | Supports all types in this table and can be nested |
Technical Notes
Execution Overview
When operating on Python models, the Score Data Processing step operates in three phases: a model initialization phase, a model scoring phase, and a model termination phase.
During the model initialization phase, the Python model, any artifact dependencies specified, and any package dependencies specified are made available to a Python engine that attempts to load the model. The Score Data Processing Step loads binary models using pre-packaged methods. The Score Data Processing Step loads script models as modules into the Python process.
During the model scoring phase, the Score Data Processing Step scores input records as follows:
- converts incoming data into a numpy array
- Sends the numpy array as input to:
- a pre-packaged scoring function for binary models
- the user-defined scoring function for script models
- converts and retrieves numpy array output back into the record
During the model termination phase (when the scoring pipeline is shut down), the Python engine servicing the Score Data Processing step and the related execution context are ended.
The initialization and termination phases are opaque to the Python models – the models do not receive any notifications during those phases.
Persisting Values Over Records
For Python Script models, Score Data Processing Step imports the user script containing the scoring function as a module. To persist values over the span of processing of several input records, store them in the module's namespace.
The following Python script model example maintains
a cumulative sum and count of the input data in a module-scoped
dictionary values_to_persist (using keys cumulative_sum and cumulative_count).
The dictionary values_to_persist is initialized when the Python script is loaded
as a module; the key-value pairs of that dictionary can be accessed and updated
during subsequent calls to the scoring function.
## a running count and a running sum are
## saved in a dictionary in the module-scope
## to persist the values across several records
import numpy as np
from typing import Iterable
from typing import Tuple
# initialized once when the model loads
# ----
C_SUM = "cumulative_sum"
C_COUNT = "cumulative_count"
C_ID = "ID"
values_to_persist = {
C_SUM: 0.0,
C_COUNT: 0
}
SCORE_COLS = [C_SUM, C_COUNT, C_ID]
DUMMY_ID = -1
# ----
# the scoring function is called for every record
def score(data: np.ndarray, column_names: Iterable[str]) -> Tuple[np.ndarray, Iterable[str]]:
values_to_persist[C_SUM] += sum(data[:, 0])
values_to_persist[C_COUNT] += len(data[:, 0])
scores = np.array([[values_to_persist[C_SUM], values_to_persist[C_COUNT], DUMMY_ID]])
return scores, SCORE_COLS
Python Interpreter Used
See the Platforms page for information on the version of Python used to load and score run Python models.