
R Models
This page explains the use of R models in TIBCO ModelOps. The Models page provides general information about all supported TIBCO ModelOps model types.
Contents
Overview
R objects that provide an implementation for the generic predict function can be scored in TIBCO ModelOps; such objects can be serialized into one of the following two formats:
These R objects are called R models in TIBCO ModelOps. Input and output schemas must be bound to an R model before the model becomes available for use in the Score Data step.
R Object Models
R object models refer to models that are saved in the RDS format. These models contain a single R object that provides an implementation for the generic predict function.
The following example R script describes how to create an R object model.
library(rpart)
# load iris data and rename columns
data(iris)
colnames(iris) <- c("Sepal_Length", "Sepal_Width", "Petal_Length", "Petal_Width", "Species")
# create classification tree model
iris_rpart <- rpart(Species ~ Sepal_Width + Petal_Width, data=iris)
# save model
saveRDS(iris_rpart, "iris_rpart.rds")
The RDS model saved in the example above is scorable by using the predict function.
# load model from file
iris_rpart_loaded <- readRDS("iris_rpart.rds")
# score records in df_new dataframe
predict(iris_rpart_loaded, newdata = df_new)
R Data Models
R data models refer to models that are saved in the RData format. They contain one or more R objects.
To successfully load in TIBCO ModelOps, R data models must contain exactly one object that provides
an implementation for the generic
predict
function. If an R data model has no objects supporting the generic predict function or contains more than
one object that provides implementations for the predict function, model loading fails.
The following example R script describes how to create an R data model.
library(rpart)
# create R regression partitioning tree model
tree_model <- rpart(Species ~ Sepal_Length + Petal_Length, data = iris)
# alternatively: save(tree_model, "tree_model.rda")
save(tree_model, "tree_model.rdata")
The rdata (shortened form: rda) model saved in the example above is scorable by using the predict function.
# load model from file
tree_model <- load("tree_model.rdata")
# score records in df_new dataframe
predict(tree_model, newdata = df_new)
R Objects with User-defined Predict Implementations
Models that provide a user-defined implementation for the predict function
can also be scored in TIBCO ModelOps. A user-defined predict implementation
can be provided for an existing model by creating a “wrapper”
model using the
structure
function with attributes.
User-defined predict functions can be used to implement before and after scoring
processes such as normalizing input data, missing value imputation, and augmenting raw scores.
# Define a custom scoring function
scoring_function <- function(model, newdata, ...) {
# scoring logic goes here
# return a data frame
}
# create wrapper model
wrapper_model <- structure(
original_model,
predict.model_class = scoring_function,
class = "model_class"
)
# Save model and function in RData format
save(wrapper_model, original_model, scoring_function, file = "model.rdata")
The name of the predict method attribute must follow the naming convention used by
UseMethod
to dispatch the predict call to the user-defined implementation correctly.
For example, if the wrapper model's class is named customer_churn, the structure call would be:
wrapper_model <- structure(
original_model,
predict.customer_churn = scoring_function,
class = "customer_churn"
)
User-defined predict functions must receive data as a
data frame
into a parameter
named newdata and return a
data frame as output.
For more information, see the Technical Notes section.
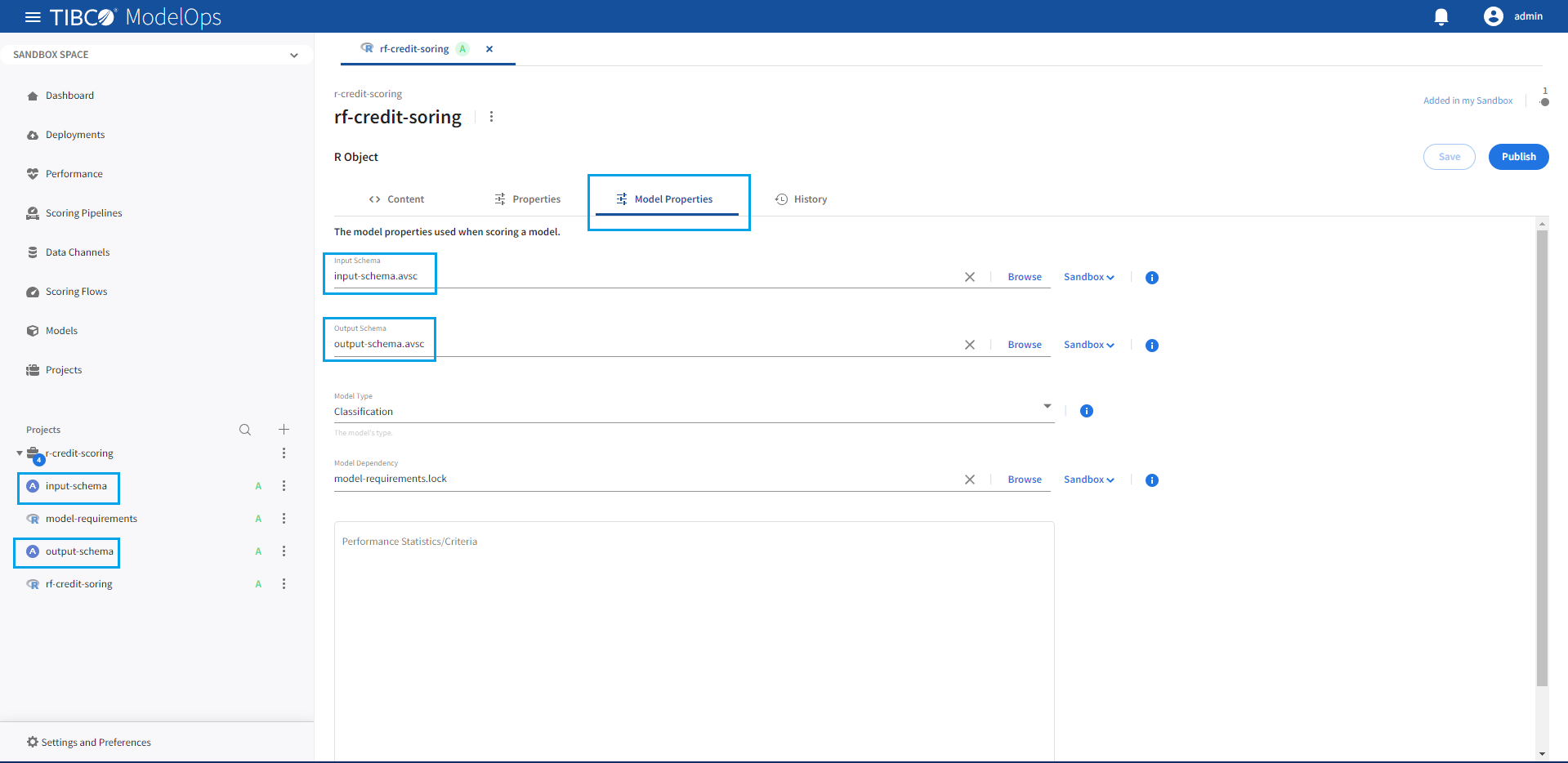
R Model Dependencies
R model package dependencies must be specified using an renv lockfile. The lockfile contents store the package dependencies of a specific R environment in the JSON format. Include an renv lockfile as an R model dependency on the ModelOps server Model Properties page.
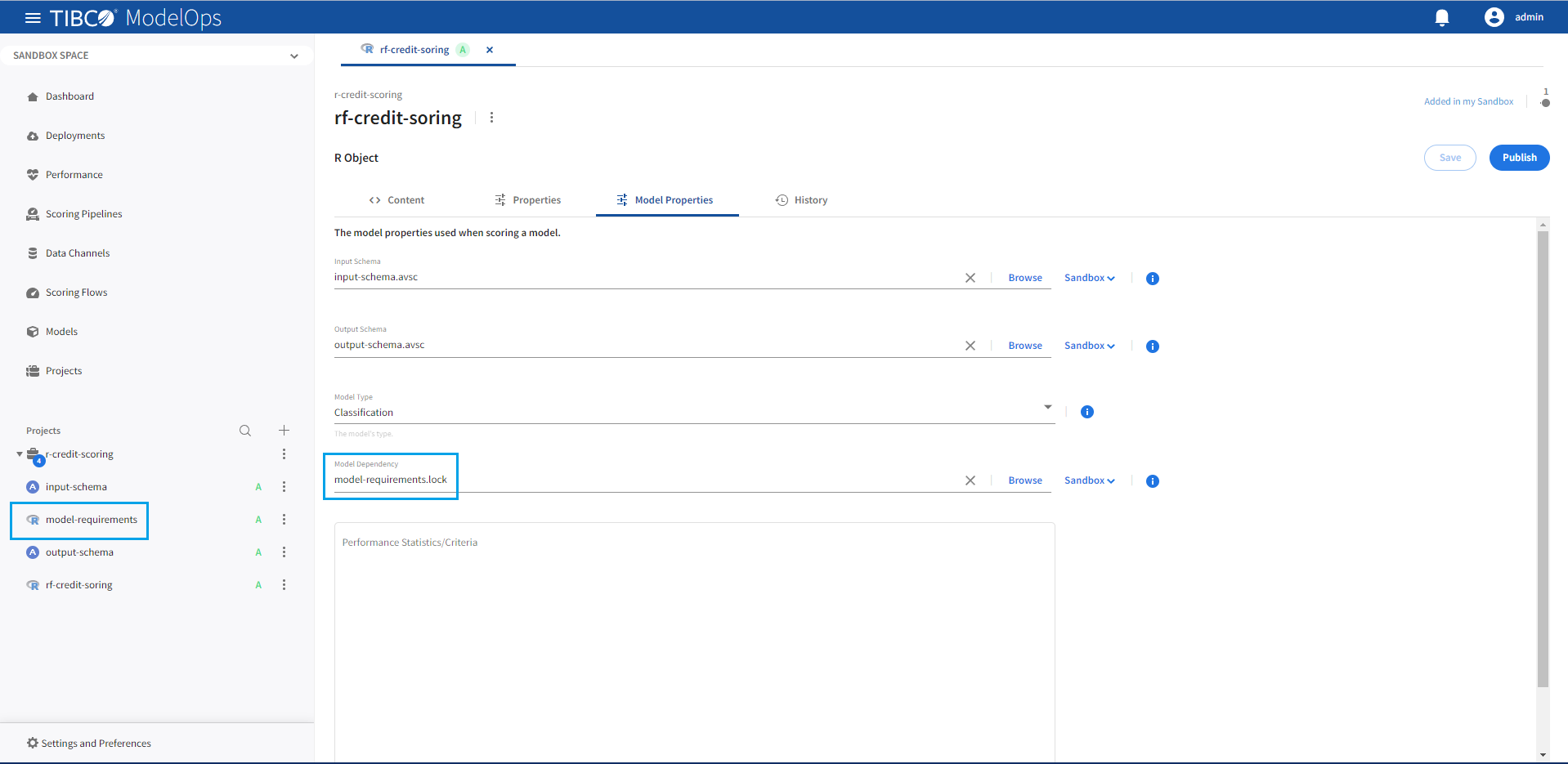
Lock files can be created using renv::snapshot() during model creation. For fast model load times, it is recommended that renv::snapshot be used by specifying only the packages needed by the model using the packages parameter. Lock files containing packages not required by the model can cause a significant slowdown of the model loading phase.
The following are some recommended practices to create lock files to use in TIBCO ModelOps. Example R commands are provided for illustration purpose.
-
Create a new R project within your R development environment.
-
Call renv::init() to initialize a new project-local R environment.
Note: This step might require users to install the renv package when using a base R installation without the renv library.
-
A new renv.lock file with just the renv package dependency should be created and available for use within the project directory.
-
-
Install the packages required for creating the R model.
install.packages(c("MASS", "rpart")) -
Load the installed packages.
library(MASS) library(rpart) -
Create an R model. This step may involve installing and loading additional R packages needed for experimenting, testing and validating the created R model by the model author.
-
Update the lock file by calling renv::snapshot(). Using renv::snapshot() defaults to “implicit” style snapshots. It actually results in saving all packages which appear in your project. Although this helps ensure that only the packages in the project are saved in the lock file, it may slow down the package restoration if your project contains a large number of package dependencies that are irrelevant to the created R model. Therefore, we recommend saving only the packages that are required by the R model using the renv::snapshot packages parameter.
For example, consider a model that uses only the MASS and rpart packages. The recommended practice for creating the lock file for such a model would be to call renv::snapshot() as follows:
renv::snapshot(packages = c("MASS", "rpart")) -
The lock file generated by renv::restore() will specify only the MASS and rpart dependencies. It can now be used as a model dependency.
{ "R": { "Version": "4.2.1", "Repositories": [ { "Name": "CRAN", "URL": "https://cloud.r-project.org" } ] }, "Packages": { "MASS": { "Package": "MASS", "Version": "7.3-58.2", "Source": "Repository", "Repository": "CRAN", "Hash": "e02d1a0f6122fd3e634b25b433704344", "Requirements": [] }, "rpart": { "Package": "rpart", "Version": "4.1.19", "Source": "Repository", "Repository": "CRAN", "Hash": "b3c892a81783376cc2204af0f5805a80", "Requirements": [] } } }
Other dependencies (for example, data files or model parameters from files) required by the custom defined R object can also be specified on the Model Properties page.
For example, an R model might require values to scale the scored predictions from a CSV file. This file must be specified as a Model Dependency on the Model Properties page.
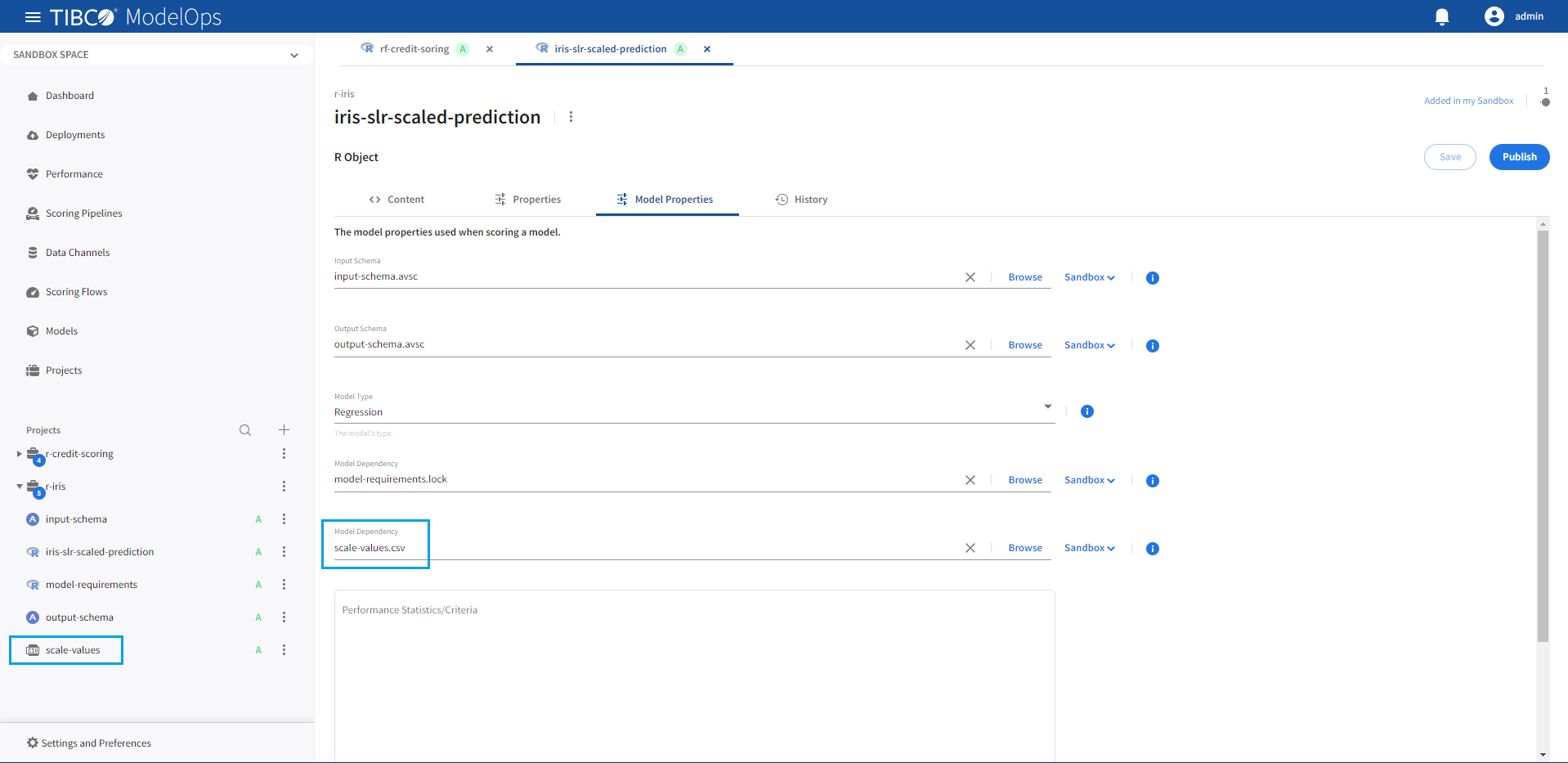
Note: model dependency files cannot have rdata, rda, or rds extensions. All other file extensions are supported as model dependencies.
Data Type Mapping
The following data type mapping is supported for R models in TIBCO ModelOps.
| OpenAPI Type | OpenAPI Format | R Type | Comments |
|---|---|---|---|
| boolean | logical | ||
| integer | int32 | integer | 32 bit signed value |
| integer | int64 | integer64 | 64 bit signed value |
| number | double | double | Double precision floating point value |
| number | float | double | Single precision floating point value |
| string | character | UTF 8 encoded character data | |
| string | character | contentEncoding=base64. OpenAPI content is Base64 encoded binary data. R uses the binary content without Base64 encoding | |
| string | date | Date | RFC 3339 full-date |
| string | date-time | POSIXct | RFC 3339 date-time |
| array | vector | Supports all the basic types in this table and can be nested | |
| object | list | Supports all the basic types in this table and can be nested |
Technical Notes
Execution Overview
When operating on R models, the Score Data step operates in a model load phase and a model score phase.
During the model load phase, the R model, any artifact dependencies specified, and any package dependencies specified are made available to an R engine. The R engine installs any package dependencies specified and loads them as libraries before loading the R model.
During the model scoring phase, the Score Data Step processes input records as follows:
- converts incoming data into a data frame
- invokes the
predictfunction on the model object sending:- the input data into the
newdataparameter - the location of the model on disk into the
projectparameter
- the input data into the
scores <- predict(loaded_model,
newdata = input_data_frame,
project = disk_location_of_model
)
- retrieves and converts the output data frame back into the flow