Contents
When you start using a new product, you often have some basic questions, such as:
-
What is it?
-
How will it help me do my job?
-
What is the development cycle and environment?
-
What are the product's components, and what new terms do I need to understand?
This topic addresses those initial questions in enough depth to understand the various lessons taught in the tutorial.
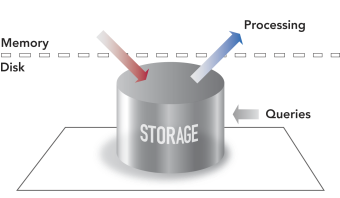
StreamBase is a new type of computing platform, designed specifically to meet the performance requirements of high-volume, real-time streaming applications. At its core, StreamBase implements a unique Stream Processing Engine™ named StreamBase Server. In contrast to the traditional database model where data is first stored and indexed and then subsequently processed by queries, StreamBase processes the inbound data while it is in flight, as it streams through the server.
Data arrives on a stream as discrete messages called events. Each message contains a tuple, and is processed by StreamBase Server in real time, using the business logic that you defined. Results are delivered as they are produced, typically in milliseconds. Events are inherently transient: their data can be stored, but it is optional. In many cases, client programs that you write will consume the processed results in real time, and take appropriate actions based on your code's direction.
StreamBase can also connect to an external data source, enabling applications to incorporate selected data into the application flow, or to update the external database with processed information.
The following diagrams illustrate the conceptual differences between the older Outbound Processing model and the new StreamBase Inbound Processing model.
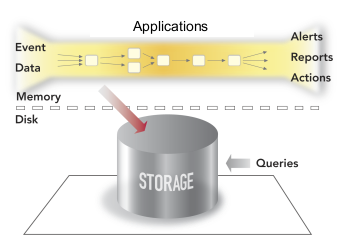
In StreamBase applications, events are represented by data records called tuples that flow through the query and application processing steps, which may in turn produce new events with data derived from this data. Tuples consist of one or more name-value pairs of data, called fields. Each field value has a specific data type. StreamBase provides a set of operators, data processing units that you can add and configure to apply your business logic on the streaming data. With the operators and a supporting cast of data constructs, you can perform such tasks as:
-
Applying aggregating functions to windows of real-time data
-
Computing new field values by applying mathematical expressions, adding new fields, or dropping fields, from the data streams
-
Filtering data into separate streams for conditional processing
-
Performing approximate buffered sorts of the real-time data
-
Joining previously split streams of data based on key values
-
Within the StreamBase application's process, populating a shared data table so that other portions of the application can look up data based on key values
StreamBase also features a graphical rapid-development environment, called StreamBase Studio. It lets you design, test, and deploy streaming applications. StreamBase users report that by using StreamBase Studio, their development teams are able to build streaming applications in less time and at lower costs, when compared with their efforts to create or redesign streaming applications.
For developers and administrators, StreamBase provides graphical, text-based, and command-line tools to build streaming applications quickly and efficiently.
In StreamBase Studio, a collection of views called the SB Authoring perspective lets you design the StreamBase application either graphically, using the text-based StreamSQL language, or with a combination of both. As part of this design step, you define properties for the operators and other components that will apply your business logic on the inbound data. We'll discuss the SB Authoring perspective's features in the next section.
Whether you are developing the application on Windows or Linux, you can use StreamBase Studio to start a StreamBase Server instance. The StreamBase Server loads the application, processing the inbound data according to your definitions in the operators, and responding to any other requests, such as requests for data from Java, C++, or .NET clients that you write. The StreamBase Client Libraries are documented, and we provide examples of writing enqueuer clients (sometimes called producers) that feed data into the application, and dequeuer clients (sometimes called consumers) that accept data from the application for further processing.
Once the server is started, StreamBase Studio provides a second perspective, Test/Debug, that contains tools to enqueue or dequeue data on the running application, or run a debugger to pause the application and step through its processing units, or view performance statistics.
Finally, StreamBase provides Client libraries for Java, C++, and on Windows, .NET, that you can use to develop client applications that enqueue to (or dequeue data from) StreamBase applications.
The following diagram illustrates the StreamBase development cycle and platforms. Note that StreamBase Studio is supported on all platforms except for Solaris, and that StreamBase Server runs on all platforms.
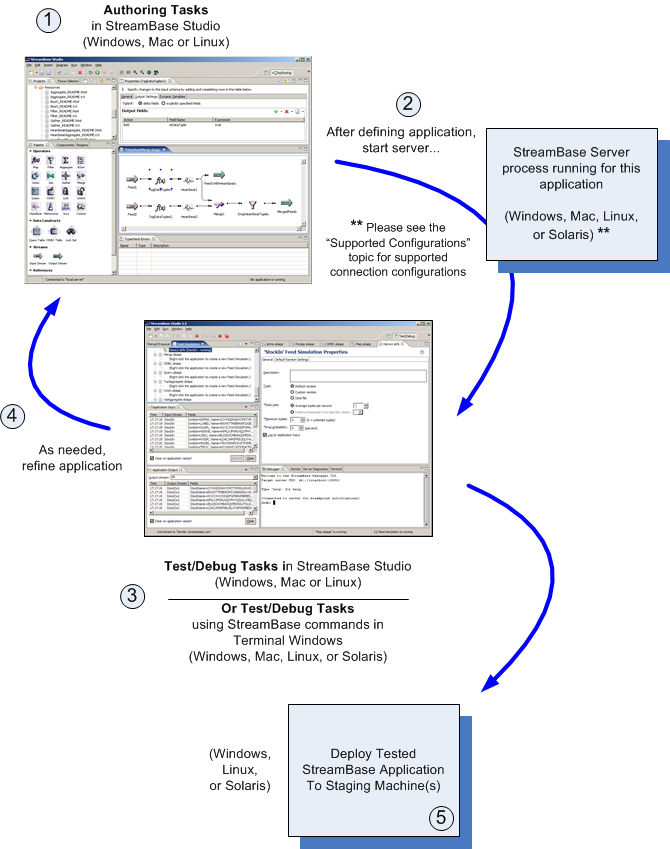
So far you have learned that StreamBase Studio has a graphical development environment for building StreamBase applications. Let's take a closer look at the product's components and terms.
To begin with, what is a stream? A stream is a sequence of data records called tuples. A tuple is similar to a row in a database table. In a high-volume streaming application, the streams flow into the application and
are processed in real time, before any (optional) on-disk storage occurs. The tuples in a stream have a schema, which defines each field's name, data type, and position. A field is simply a named value in a tuple, such as a stock's
Symbol in a trade record. A field is similar to a column in a database table. The following diagram illustrates a stream of data
containing tuples:

A schema for the stream in the above diagram might be {Symbol string, Name string, Description string, Volume int, Price double}.
During the course of processing streaming data, you can add, remove, or modify the fields that comprise the tuples, in a highly dynamic fashion. In other words, the initial schema of the stream does not determine its contents during the entire processing execution.
Of course, an important step in building any application is determining which fields will comprise the inbound data, how that data should be organized, named, and typed (examples: string, int, long, boolean, double, timestamp), and usually which field(s) will contain key values. Often, though, you have already made those metadata decisions for your existing applications, and you want to know how to define the schemas for StreamBase. We will introduce the schema definition steps later in this tutorial. For now, notice how in the screen below the schema for an application component is defined:
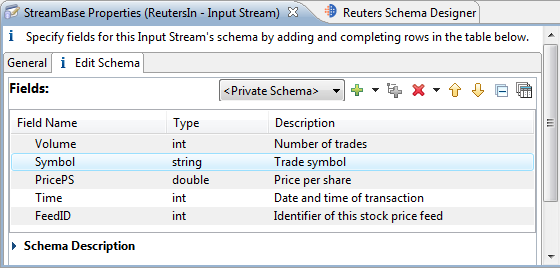
The sample screen above is a peek at just one of many features in StreamBase Studio, our graphical development environment. Let's take a step back, though, and learn how data gets into a StreamBase application.
The entry points for a StreamBase application are called input streams. Your application may define one or more input streams. The previous sample screen showed the schema definition for a Reutersin input stream. But how is data sent to a named input stream? The options are:
-
From an adapter program that performs the conversion from an external source (such as a stock market data feed) into the StreamBase protocol. For example, StreamBase provides an adapter that converts TIBCO® Rendezvous™ messages into StreamBase tuples, and vice versa.
-
From an enqueue client program (Java, C++, or .NET) that submits inbound data to one or more input streams defined in your StreamBase application. A client extends the documented StreamBase Client library to interact with a running StreamBase application.
-
From an external database connected to your StreamBase application, using SQL queries to read the data. Currently you can connect to a JDBC database. This method enables your application to work with long-lived (historical) data along with the streaming data from its input streams.
-
And you can use StreamBase commands in terminal windows to perform an even greater level of enqueuing operations with running applications.
-
While designing your application, you can use a graphical feature of StreamBase Studio, called the Feed Simulation Editor, to submit randomly generated data or pre-recorded data from an input file such as a comma-separated value (CSV) file. The Feed Simulation Editor includes defaults or customized settings to control the rate of inbound test data.
You can define output streams that serve as named exit points in your StreamBase application. There are several ways to perform dequeue operations:
-
Using an adapter program that can return the processed data from StreamBase to the original external source.
-
Using a dequeue client program that listens for outbound data on the application's streams. A client can be written in Java, C++, or .NET, extending the documented StreamBase Client library to interact with the running application.
-
Using insert or update queries to an external JDBC-compliant data source that is connected to your StreamBase application.
-
You can also use a graphical feature of StreamBase Studio to view the Application Output.
-
And you can use a StreamBase command to dequeue tuples from streams.
The following high-level diagram illustrates the different ways that data can enter and exit a running StreamBase application.
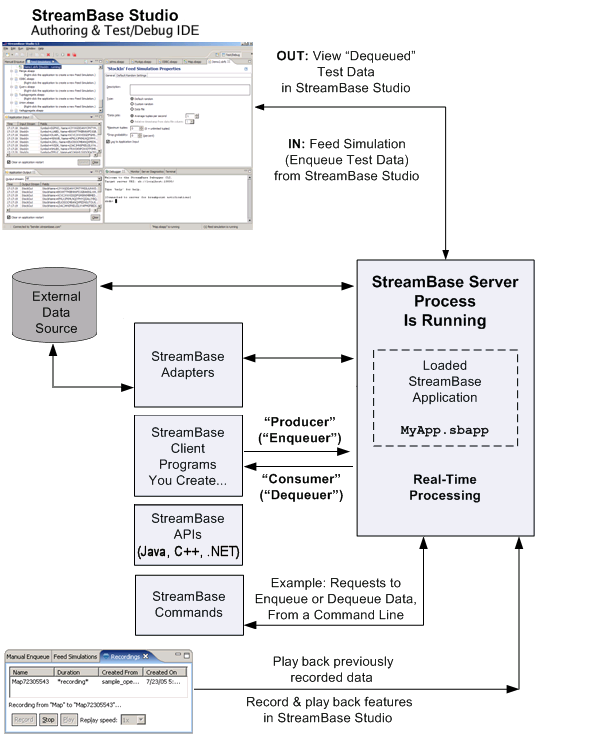
A set of "standard" adapters is provided with your StreamBase license. Other adapters (called Premium Adapters) are available separately from TIBCO, based on the terms of your license.
StreamBase Studio supports both graphical and text-based application development:
-
EventFlow applications are XML files that are edited graphically using StreamBase Studio's EventFlow Editor.
-
StreamSQL applications are coded using a query language to describe the application and query streams of data. StreamSQL Applications are stored in text files with a
.ssqlextension.
You can also build parts of applications, called modules, that can be included as components in other applications. In fact, any EventFlow or StreamSQL file can be used as a module in another application.
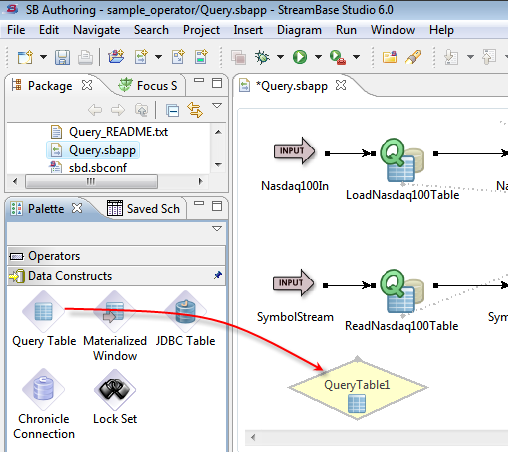
To create an EventFlow application in StreamBase Studio, you can drag and drop the icons for various components from a Palette View to the EventFlow Editor's drawing canvas. As noted earlier, the components include:
-
Input streams and output streams.
-
Operators that can apply your business logic on streaming data, such as aggregating tuples, or merging tuples, or retrieving data from a table. Each operator performs the work that you specify in its Properties view.
-
Data constructs that store information used by an associated StreamBase operator. For example, Query operators are associated with Query Table data constructs.
We will use some of these components during the tutorial, and you can read more about them in the Authoring Guide.
Here's an illustration that shows the drag and drop step, from the left-side Palette to the EventFlow Editor's drawing canvas.
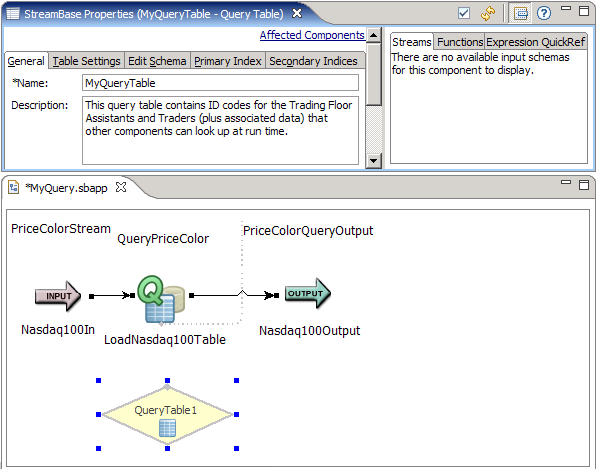
Once a component is placed on the canvas, you define its runtime behavior by setting parameters and (for most components) defining expressions in the Properties View. In the next screen, we have selected QueryTable1 in the EventFlow Editor to open its Properties view. In the General tab, we changed its name to MyQueryTable and added a description that documents our design. We can use the other tabs to define the behavior of the component.
If you prefer to work with SQL queries instead of boxes and arrows, you can build applications using StreamSQL. StreamSQL
will look familiar to SQL programmers, but there are some important differences. While SQL operates on tabular data that is
stored somewhere on disk or in memory, StreamSQL supports operations on streams of continuously changing data. The two application
formats are functionally equivalent; in fact StreamBase Studio provides a utility that converts EventFlow sbapp files to StreamSQL ssql files.
You can use any text editor to write StreamSQL applications. However, coding in StreamBase Studio offers several advantages:
-
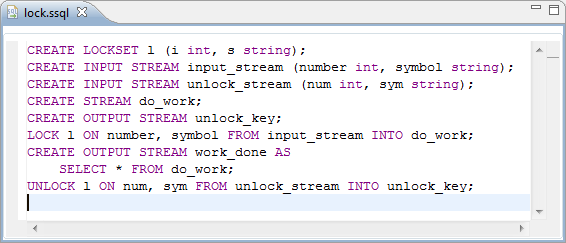
The SB Authoring perspective includes a StreamSQL editor that facilitates writing StreamSQL queries. The editor's Content Assist feature makes entering keywords easy, and StreamBase checks your syntax as you work.
-
StreamBase Studio views make it easy to combine StreamSQL applications and other StreamBase components. For example, you might want to reference a StreamSQL application within a StreamBase EventFlow application. Or, going the other way, you might embed existing StreamBase applications as modules within a StreamSQL query.
The following image shows the StreamSQL Editor in the SB Authoring perspective:
As we mentioned earlier, an EventFlow or StreamSQL application can be used as a module in another application. For example, you can create an application that performs a common task, and include it in any number of other applications. This reuse can save time in both development and maintenance. Obviously, the functionality in the module must make sense for the application that uses it. For example, both must use compatible data.
If you are working on an EventFlow application, StreamBase Studio lets you simply drag an existing application from the Package Explorer to the canvas of the EventFlow Editor. In the following figure, a StreamSQL module has been added:
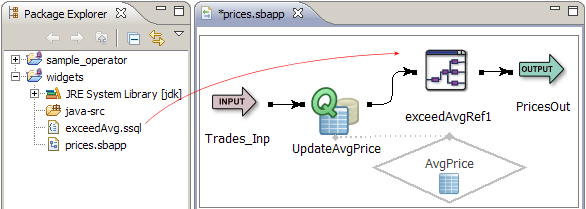
If you are writing a StreamSQL application, you can include an existing application as a module.
We have covered some of the key StreamBase components and terms, and the ways in which you can create applications. It's time to start using the tool. You can learn much more about the product by following the remaining topics in this guide, where you will have an opportunity to build your first StreamBase application.
To get started, click .