Funzioni statistiche
L'elenco mostra le funzioni statistiche utilizzabili nelle espressioni.
| Funzione | Descrizione |
|---|---|
Avg(Arg1, ...)
|
Restituisce la media (media aritmetica) degli argomenti. Gli argomenti e il risultato sono di tipo real. Se viene fornito un argomento, il risultato è la media di tutte le righe. Se vengono forniti più argomenti, il risultato è la media di ogni riga. Gli argomenti null sono ignorati e non contribuiscono alla media. Esempi:
|
ChiDist(Arg1)
|
Restituisce il valore P del chi-quadro (maggiore) dell'argomento. Esempio:
|
ChiInv(Arg1)
|
Restituisce il valore del quantile del chi-quadro (maggiore) dell'argomento. Esempio:
|
Count(Arg1)
|
Calcola il numero di valori non vuoti nella colonna dell'argomento oppure, se non sono specificati argomenti, il numero totale di righe. Esempio:
|
CountBig(Arg1)
|
Calcola il numero di valori non vuoti nella colonna dell'argomento oppure, se non sono specificati argomenti, il numero totale di righe. Questa funzione restituisce un LongInteger. Esempio:
|
Covariance(Arg1, Arg2)
|
Calcola la covarianza di due colonne fornite come argomenti. Esempio:
|
FDist(Arg1)
|
Restituisce il valore p F (maggiore) dell'argomento. Esempio:
|
FInv(Arg1)
|
Restituisce il valore del quantile di F (maggiore) dell'argomento. Esempio:
|
First(Arg1)
|
Restituisce il primo valore valido in base all'ordine fisico delle righe di dati nella colonna dell'argomento. Esempio:
|
GeometricMean()
|
Calcola il valore della media geometrica. Se uno dei valori di input è negativo, il risultato è "Vuoto". Se uno dei valori di input è uguale a zero, il risultato è zero. Esempio:
|
IQR(Arg1)
|
Calcola la differenza di valore Q3-Q1 o il 75° percentile meno il 25° percentile. IQR chiamato anche scarto H. Esempio:
|
L95(Arg1)
|
Calcola l'endpoint inferiore del 95% dell'intervallo di certezza. Nota: il valore t statico 1,959964, utilizzato da questa funzione, viene adattato a dimensioni ampie del campione ( n >= 40). Per dimensioni più ridotte del campione, utilizzare invece la seguente espressione:
Esempio:
|
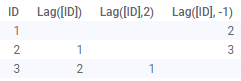
Lag(Arg1, Arg2)
|
Sposta i valori in una colonna verso il basso per il numero di passi specificato. Il primo argomento è la colonna in cui effettuare lo spostamento. Il secondo argomento (opzionale) è il numero di passi. L'impostazione predefinita è 1. Se viene utilizzato un numero di passi negativo, i valori vengono spostati nella direzione opposta (vedere l'immagine seguente). Esempi:
Si noti che la funzione Lag è applicata ai dati nell'ordine in cui questi sono stati caricati. La funzione non tiene conto dell'ordinamento nelle visualizzazioni e qualsiasi modifica ai dati (ad esempio durante il ricaricamento) potrebbe comportare valori diversi per le varie righe. |
Last(Arg1)
|
Restituisce l'ultimo valore valido in base all'ordine fisico delle righe di dati nella colonna dell'argomento. Esempio:
|
LastValueForMax(Arg1, Arg2)
|
Restituisce il valore della colonna 2 per il valore massimo della colonna 1. In presenza di più valori massimi della colonna 1, il risultato è il valore dell'ultima riga massima. Vedere anche Esempio:
|
LastValueForMin(Arg1, Arg2)
|
Restituisce il valore della colonna 2 per il valore minimo della colonna 1. In presenza di più valori minimi della colonna 1, il risultato è il valore dell'ultima riga minima. Vedere anche Esempio:
|
LAV(Arg1)
|
Calcola il valore adiacente inferiore. Esempio:
|
Lead(Arg1, Arg2)
|
Sposta i valori in una colonna verso l'alto per il numero di passi specificato. Il primo argomento è la colonna in cui effettuare lo spostamento. Il secondo argomento (opzionale) è il numero di passi. L'impostazione predefinita è 1. Se viene utilizzato un numero di passi negativo, i valori vengono spostati nella direzione opposta (vedere l'immagine seguente). Esempi:
Si noti che la funzione Lead è applicata ai dati nell'ordine in cui questi sono stati caricati. La funzione non tiene conto dell'ordinamento nelle visualizzazioni e qualsiasi modifica ai dati (ad esempio durante il ricaricamento) potrebbe comportare valori diversi per le varie righe. |
LIF(Arg1)
|
Calcola la partizione interna inferiore. Si tratta della soglia localizzata in corrispondenza di Q1 - (1,5*IQR). Esempio:
|
LOF(Arg1)
|
Calcola la partizione esterna inferiore. Si tratta della soglia localizzata in corrispondenza di Q1 - (3*IQR). Esempio:
|
Max(Arg1, ...)
|
Calcola il valore massimo. Se viene fornito un argomento, il risultato è il massimo per l'intera colonna. Se vengono forniti più argomenti, il risultato è il massimo per ogni riga. L’argomento e il risultato sono di tipo real. Gli argomenti null sono ignorati. Esempi:
|
MeanDeviation(Arg1, ...)
|
Calcola il valore della deviazione della media (AAD, Average Absolute Deviation). Se viene fornito un argomento, il risultato è la deviazione della media di tutte le righe. Se vengono forniti più argomenti, il risultato è la deviazione della media per ogni riga. Esempi:
|
Median(Arg1)
|
Calcola la mediana dell'argomento. Se viene fornito un argomento, il risultato è la mediana di tutte le righe. Se vengono forniti più argomenti, il risultato è la mediana per ogni riga. Esempi:
|
MedianAbsoluteDeviation(Arg1, ...)
|
Calcola la deviazione assoluta della mediana (MAD, Median Absolute Deviation). Se viene fornito un argomento, il risultato è la deviazione assoluta della mediana di tutte le righe. Se vengono forniti più argomenti, il risultato è la deviazione assoluta della mediana per ogni riga. Esempi:
|
Min(Arg1, ...)
|
Calcola il valore minimo. Se viene fornito un argomento, il risultato è il minimo per l'intera colonna. Se vengono forniti più argomenti, il risultato è il minimo per ogni riga. L’argomento e il risultato sono di tipo real. Gli argomenti null sono ignorati. Esempi:
|
NormDist(Arg1)
|
Restituisce il valore p normale (maggiore) dell'argomento. Se non specificati, i valori predefiniti sono media=0 e deviazione standard=1. Esempio:
|
NormInv(Arg1)
|
Restituisce il valore del quantile normale (maggiore) dell'argomento. Se non specificati, i valori predefiniti sono media=0 e deviazione standard=1. Esempio:
|
NthLargest(Arg1, Arg2)
|
L'n-esimo valore più grande. Il primo argomento è la colonna da analizzare e il secondo è il valore di n. Se n è maggiore del numero di valori nella colonna, viene restituito il valore più piccolo. Esempio:
|
NthSmallest(Arg1, Arg2)
|
L'n-esimo valore più piccolo. Il primo argomento è la colonna da analizzare e il secondo è il valore di n. Se n è maggiore del numero di valori nella colonna, viene restituito il valore più grande. Esempio:
|
Outliers(Arg1)
|
Conteggio dei valori esterni. Calcola il numero di valori maggiori del valore adiacente superiore o minori del valore adiacente inferiore. Esempio:
|
P10(Arg1)
|
Il 10° percentile è il valore al quale il 10 percento dei valori dati è minore o uguale al valore. Esempio:
|
P90(Arg1)
|
Il 90° percentile è il valore al quale il 90 percento dei valori dati è minore o uguale al valore. Esempio:
|
PctOutliers(Arg1)
|
Percentile dei valori esterni. Calcola la percentuale di valori maggiori del valore adiacente superiore o minori del valore adiacente inferiore. Esempio:
|
Percentile(Arg1, Arg2)
|
La percentuale è il valore calcolato per una certa percentuale oltre il valore minimo all'interno dell'intervallo di valori (valore max - valore min). Il primo argomento è la colonna da analizzare e il secondo è la percentuale. Esempio:
|
Percentile(Arg1, Arg2)
|
Il percentile è il valore al quale una certa percentuale dei valori dati è minore o uguale al valore. Il primo argomento è la colonna da analizzare e il secondo è la percentuale. Esempio:
|
Q1(Arg1)
|
Calcola il primo quartile. Esempio:
|
Q3(Arg1)
|
Calcola il terzo quartile. Esempio:
|
Range(Arg1)
|
Intervallo tra il valore più grande e il valore più piccolo nella colonna. Il risultato è un real o un TimeSpan, a seconda del tipo di dati dell'argomento. Esempio:
|
StdDev(Arg1)
|
Calcola la deviazione standard. Esempio:
|
StdErr(Arg1)
|
Calcola l'errore standard. Esempio:
|
TDist(Arg1)
|
Restituisce il valore p t (maggiore) dell'argomento. Esempio:
|
TERR_Binary
|
Chiama Spotfire® Enterprise Runtime for R (chiamato anche TERR™) e restituisce un output del tipo di dati specificato, contenente lo stesso numero di righe dell'input. Il primo argomento è uno script e gli argomenti successivi sono gli argomenti dello script. La colonna restituita deve contenere lo stesso numero di righe dell'input. Oltre allo script, è necessario che sia presente almeno un altro argomento. Gli input saranno sostituiti nelle variabili denominate Esempi:
|
TERR_Boolean
|
Vedere TERR_Binary sopra. |
TERR_DateTime
|
Vedere TERR_Binary sopra. |
TERR_Integer
|
Vedere TERR_Binary sopra. |
TERR_Real
|
Vedere TERR_Binary sopra. |
TERR_String
|
Vedere TERR_Binary sopra. |
TERRAggregation_Binary
|
Chiama il motore TERR e restituisce un output del tipo di dati specificato. Il primo argomento è uno script e gli argomenti successivi sono gli argomenti dello script. Lo script deve restituire un valore aggregato singolo. Oltre allo script, è necessario che sia presente almeno un altro argomento. Gli input saranno sostituiti nelle variabili denominate Esempi:
|
TERRAggregation_Boolean
|
Vedere TERRAggregation_Binary sopra. |
TERRAggregation_DateTime
|
Vedere TERRAggregation_Binary sopra. |
TERRAggregation_Integer
|
Vedere TERRAggregation_Binary sopra. |
TERRAggregation_Real
|
Vedere TERRAggregation_Binary sopra. |
TERRAggregation_String
|
Vedere TERRAggregation_Binary sopra. |
TInv(Arg1)
|
Restituisce il valore del quantile t (maggiore) dell'argomento. Esempi:
|
TrimmedMean(Arg1, Arg2)
|
Calcola il valore medio troncato (media troncata). Il primo argomento è la colonna da analizzare e il secondo corrisponde al numero di valori da escludere dal calcolo in percentuale. Se il valore di troncamento è impostato al 10%, il 5% massimo e il 5% minimo dei valori sono esclusi dalla media calcolata. Esempio:
|
U95(Arg1)
|
Calcola l'endpoint superiore del 95% dell'intervallo di certezza. Nota: il valore t statico 1,959964, utilizzato da questa funzione, viene adattato a dimensioni ampie del campione ( n >= 40). Per dimensioni più ridotte del campione, utilizzare invece la seguente espressione:
Esempio:
|
UAV(Arg1)
|
Calcola il valore adiacente superiore. Esempio:
|
UIF(Arg1)
|
Calcola la partizione interna superiore. Si tratta della soglia localizzata in corrispondenza di Q3 + (1.5*IQR). Esempio:
|
UniqueCount(Arg1)
|
Calcola il numero di valori univoci non vuoti nella colonna degli argomenti. Esempio:
|
UOF(Arg1)
|
Calcola la partizione esterna superiore. Si tratta della soglia localizzata in corrispondenza di Q3 + (3*IQR). Esempio:
|
ValueForMax(Arg1, Arg2)
|
Restituisce il valore della colonna 2 per il valore massimo della colonna 1. In presenza di più valori massimi della colonna 1, il risultato è il valore della prima riga massima. Vedere anche Esempio:
|
ValueForMin(Arg1, Arg2)
|
Restituisce il valore della colonna 2 per il valore minimo della colonna 1. In presenza di più di uno dei valori minimi della colonna 1, il risultato è il valore per la prima riga minima. Vedere anche Esempio:
|
Var(Arg1)
|
Calcola la varianza. Esempio:
|
WeightedAverage(Arg1, Arg2)
|
Calcola la media ponderata di due colonne. Arg1 è la colonna della ponderazione e Arg2 è la colonna del valore. Esempio:
|

Suggerimento: è possibile utilizzare la parola chiave DISTINCT per restituire un risultato che utilizzi esclusivamente valori univoci. Ad esempio, Avg(DISTINCT[Column]) restituirebbe la media dei valori univoci invece della media di tutti i valori nella colonna specificata. UniqueCount([Column]) è l'equivalente di Count(DISTINCT[Column]).
Vedere anche Funzioni.