数据关系斯皮尔曼等级算法
“斯皮尔曼等级”选项用于在假设数据表中不存在空值的前提下计算 p 值。
注: 如果数据表中存在空值,则首先要减少数据表行数,仅保留第一列和第二列均包含值的行。
斯皮尔曼等级计算是基于观察值等级(而非值本身)的非参数比较。如果不满足正态或方差齐性假设,则可以使用这种检验方法替代线性回归。例如,如果离群值在非参数检验的计算中占有过大比重,则此方法非常有用。
根据数据表中的相同秩(即如果多个值相同,则属于相同等级)是否常见,可以采用多种不同方法计算斯皮尔曼等级。由于在常规数据分析中相同秩非常常见,因此 Spotfire 使用可以处理这些情况的算法。如果出现相同秩,则假设等级并不完全相同,取平均值作为所有相同秩的等级(请参见排名函数,"ties.method=average")。
相关值计算公式如下所示:
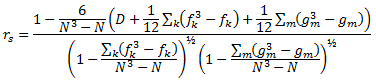
其中
N = 有效度量值对 (xi, yi) 的数目;
fk= Y 列值中第 k 个相同秩组的相同秩数
并且
gm = X 列值中第 m 个相同秩组的相同秩数。
检验统计量 FStat 计算公式如下所示:
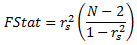
其中
rs2 = RSq = 相关值的平方。
在 Spotfire 中,应用斯皮尔曼 t 方法计算 p 值。之所以选择这种方法,是为了能够始终采用同种计算方法,并获得可接受的效果。如果数据中存在大量相同秩,则斯皮尔曼精确检验方法不适用。斯皮尔曼蒙特卡罗方法适用于任何类型的数据,但是如果要计算大量 p 值,此方法效果很差。
参考
Lehmann, E. L.,Nonparametrics:Statistical Methods based on Ranks (1975), p. 297-303.
Kendall, M.,Rank Correlation Methods (1948),p. 37-54。