注册数据函数
可以使用数据函数将用 R 或其他语言编写的计算添加到分析中,从而增强 Spotfire 的功能。数据函数使用统计引擎来执行,例如 Spotfire® Enterprise Runtime for R(又名 TERR™)引擎、开源 R 引擎或 Python 解释器。注册了函数并将其保存到库中后,便可在任何分析中使用该函数,而且脚本作者以外的其他用户也可以使用该函数。
关于此任务
此示例显示了如何注册 TERR 数据函数,但您可以通过相同过程注册使用其他计算引擎的数据函数。
开始之前
过程
结果
“注册数据函数”对话框
在“注册数据函数”对话框中,不仅可以注册全新的数据函数,还可以“打开”之前保存在库中的数据函数以便进行进一步的配置,“导入”您之前已导出到磁盘的脚本函数定义 (*.sfd),或使用其他脚本编辑工具创建的 Python 脚本文件 (*.py) 或 R 脚本文件 (*.r),而且可以将脚本函数定义“导出”到磁盘,这样便可以进行共享或在其他脚本编辑环境中进一步编辑。
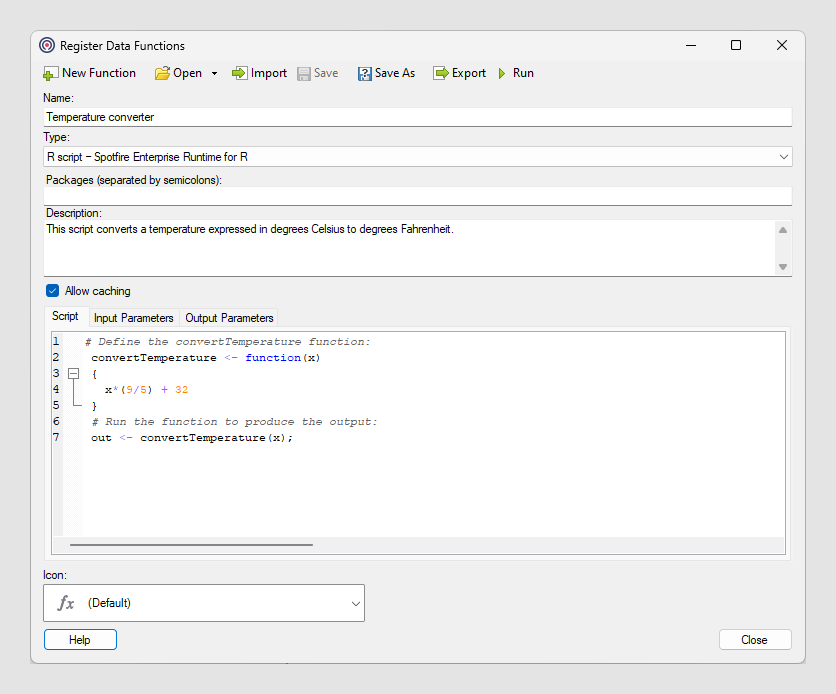
如果单击“运行”,则可以指定输入和输出参数的设置,并执行当前数据函数。这主要是用作在将数据函数保存到库之前测试数据函数的快捷方式,并且在完成测试时应从分析中删除在测试时添加的嵌入式实例,以避免在分析中保存不必要的实例。
保存分析前,改为使用“f(x) - 分析工具”或“文件和数据”或者使用“数据函数属性”(仅限已安装的客户端)中的“插入”来运行已保存的数据函数,以使数据函数能与日后库中出现的任何更新保持同步。
“允许缓存”指定在之前曾计算过输入值的相同子集时重复使用计算。如果某些输入数据来自当前分析之外的其他位置,并且您希望每次输入数据发生更改时(即使是对之前已计算的内容进行更改)都执行新计算,则清除此复选框。当输入取决于筛选值、已标记值或属性值时,输入数据可能会发生更改。
例如,如果数据函数包括随机数生成程序,您可能不希望缓存之前生成的随机数。相反,您可能希望在数据函数每次刷新时计算新的随机数。另一个关于何时清除复选框的示例是当数据函数包含当前日期或时间时。
在“脚本”选项卡上,可以键入或粘贴使用指定脚本类型语言编写的脚本。也可以编辑导入的脚本。可以使用并选择“表达式和脚本编辑器”来更改“脚本”选项卡的字体设置。脚本编辑器可突出显示语法以及对语法自动着色,从而让脚本更易于编写和阅读。
“输入参数”选项卡上列出并定义脚本中使用的所有输入参数。此列表中输入参数的顺序决定了输入参数的检索顺序。
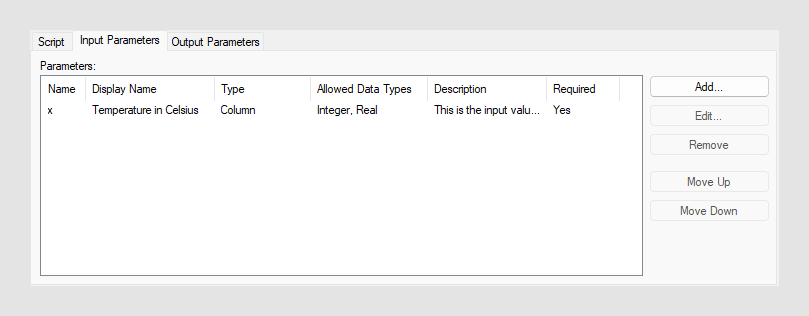
- “输入参数名称”或“名称”是在函数或脚本中引用的参数的名称。
- “显示名称”是希望参数显示给最终用户时使用的参数名称。
- “类型”决定输入类型,可以是“值”、“列”或“表”(数据表)。该类型定义了输入参数是一个或多个列,还是仅为单一值。
- “允许的数据类型”指定此输入参数支持的数据类型。可以选择在定义输入参数时想要支持的所有数据类型。必须为每个输入参数选择至少一个数据类型。
- “说明”可以选择性地包含有输入参数的详细信息,以帮助最终用户了解要提供的内容。
- “所需参数”指定调用函数时所必需的参数。如果某参数不是必需的,则函数应在不使用该参数时仍可发挥作用。
“输出参数”选项卡上列出并定义脚本中使用的所有输出参数。
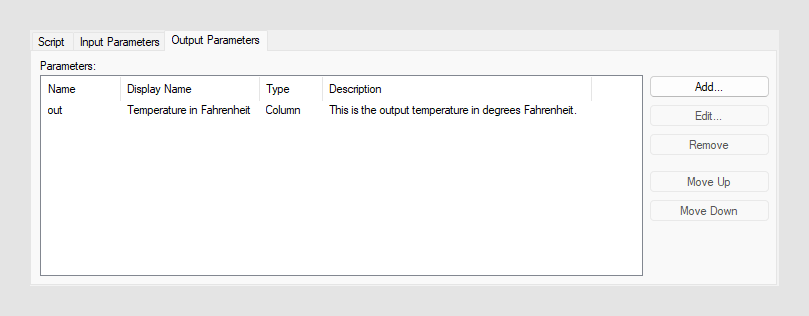
- “结果参数名称”或“名称”是在函数或脚本中引用的参数的名称。
- “显示名称”是希望参数显示给最终用户时使用的参数名称。
- “类型”决定输出类型,可以是“值”、“列”或“表”(数据表)。此项定义输出参数是一个或多个列,还是只是一个。
- “说明”可以选择性地包含有输出参数的详细信息,以帮助最终用户了解将获得的内容。
提示: 如果要添加简单计算,可以按照创建表达式函数中所述,使用统计函数下提供的
TERR_* 函数直接采用表达式语言来添加 TERR 脚本。然后可以在计算的列和自定义函数中将这些脚本用作采用表达式语言的任何其他函数。但是,请注意,表达式函数不能在不同的分析之间共享。