Adding a Hadoop Data Source from the User Interface
To add an HDFS data source, first make sure the Team Studio server can connect to the hosts, and then use the Add Data Source dialog box to add it to Team Studio.
Prerequisites
You must have data administrator or higher privileges to add a data source. Ensure that you have the correct permissions before continuing.
Procedure
-
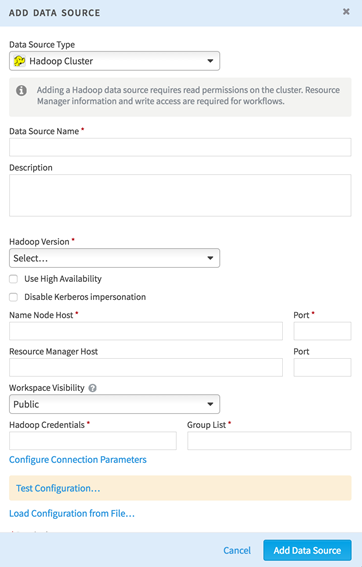
Choose
Hadoop Cluster as the data source type.
-
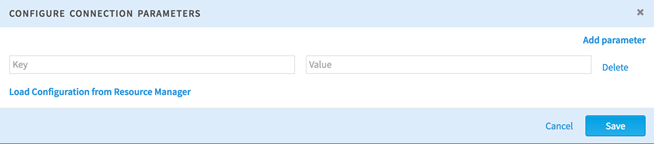
Specify key-value pairs for YARN on the
Team Studio server. Selecting
Load Configuration from Resource Manager attempts to populate configuration values automatically.
Note: Be sure the directory specified above in the staging-dir variable is writable by the Team Studio user. Spark jobs produce errors if the user cannot write to this directory.Required if different from default:-
yarn.application.classpath
- The yarn.application.classpath does not need to be updated if the Hadoop cluster is installed in a default location.
- If the Hadoop cluster is installed in a non-default location, and the yarn.application.classpath has a value different from the default, the YARN job might fail with a "cannot find the class AppMaster" error. In this case, check the yarn-site.xml file in the cluster configuration folder. Configure these key:value pairs in the UI using the Configure Connection Parameters option.
- yarn.app.mapreduce.job.client.port-range
Recommended:- mapreduce.jobhistory.address = FQDN:10020
- yarn.resourcemanager.hostname = FQDN
- yarn.resourcemanager.address = FQDN
- yarn.resourcemanager.scheduler.address = FQDN:8030
- yarn.resourcemanager.resource-tracker.address = FQDN:8031
- yarn.resourcemanager.admin.address = FQDN:8033
- yarn.resourcemanager.webapp.address = FQDN:8088
- mapreduce.jobhistory.webapp.address = FQDN:19888
-
yarn.application.classpath
-
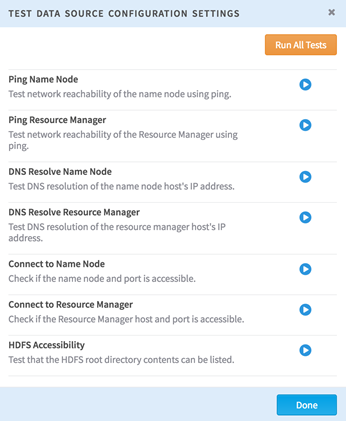
To perform a series of automated tests on the data source, click
Test Connection.
Copyright © 2021. Cloud Software Group, Inc. All Rights Reserved.