Contents
Building applications with capture fields is relatively straightforward, and once data is in a capture field, you can easily pass it between operators and access it in tables. You can access streams that include capture fields from either a client connection or from a Java operator, but doing so requires transforming the capture fields into an accessible format. There are two strategies for transforming capture fields: FLATTEN and NEST, each having different trade-offs.
The next topic illustrates typechecking issues that capture fields can have due to schema conflicts. The example uses the default FLATTEN strategy. For descriptions of how the two strategies work, see Runtime Strategies for Capture Fields.
The following modules illustrate how modules that pass through capture fields can fail to typecheck when they add fields having names that duplicate the names of fields mapped to the capture via the calling module.
Here is an EventFlow application, capture_inner.sbapp, which defines a capture field r of whose data type name is remainder. It adds a field called area that goes to output stream intermediate but is removed prior to output stream outstream.
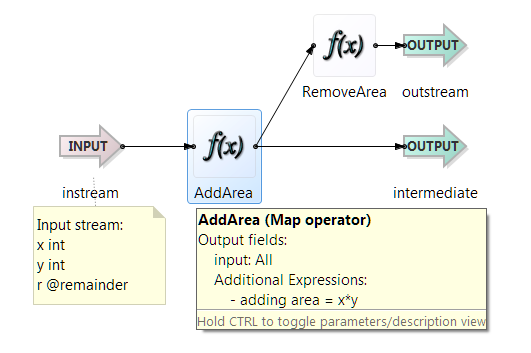
The application capture_inner.sbapp has an input stream instream whose schema consists of two ints, x and y, and a capture, r, containing data which the user has given the data type @remainder. The AddArea Map operator multiples x and y, adding the result as a new field called area. AddArea's output schema is then {x int, y int, r @remainder, area int}. That stream connects directly to output stream intermediate,
and also connects to Map operator RemoveArea, which removes the field area from the stream before passing the tuple to output port outstream. The application has no information about the contents
of capture field r.
Here is the EventFlow application capture_outer_conflict.sbapp, which passes tuples to the module capture_inner.sbapp. The module's output port has been assigned to output stream intermediate in the Port Associations table in the inner module reference's Output Ports tab. As the EventFlow diagram shows,this association creates a typechecking
error.

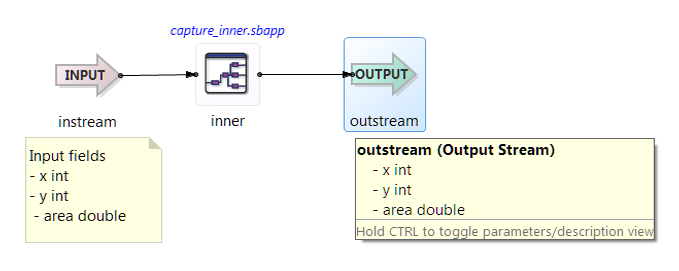
The capture_outer_conflict example illustrates what can happen when an application provides capture_inner with an input stream
whose schema includes fields in addition to x and y. In the example, input stream instream has an additional field, area, which is captured to the r capture field by module inner (capture_inner.sbapp). When the application restores capture field rarea exist in the stream intermediate. By connecting to the inner module reference's intermediate output port, the application
introduces a typecheck error, as shown above.
If instead we assign the module's output port to output stream outstream in the Port Associations table instead of to the stream named intermediate, there is no typechecking error. The conflicting field area added by Map operator AddArea has been deleted by Map operator RemoveArea, enabling the input field area to be reconstituted, as the following diagram illustrates.
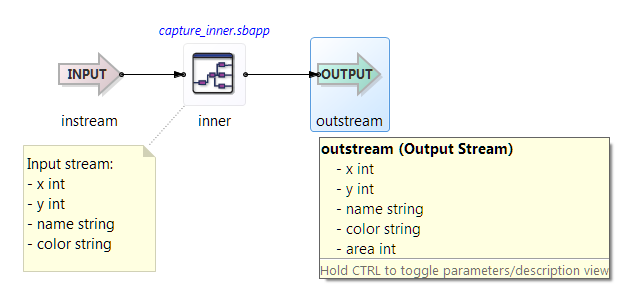
Now consider a slightly different outer module, capture_outer_no_conflict.sbapp, whose input schema includes fields called name and color instead of the field called area: {x int, y int, name string, color
string}. When capture_inner.sbapp is referenced from capture_outer_no_conflict.sbapp, no typechecking error occurs when connecting to inner's output port. The resulting output stream outstream has a schema
{x int,y int, name string, color string, area int}, as illustrated below.
In the Java Client Library, the StreamBaseClient.getStreamProperties method was extended with the argument CaptureTransformStrategy captureStrategy that allows you specify the capture field behavior you want. The default capture strategy is FLATTEN.
In the C++ Client Library, the StreamBaseClient::getStreamProperties method was extended with the captureStrategy argument (of type StreamProperties::CaptureTransformStrategy) that allows you to specify the capture field behavior you want. The default is FLATTEN.
Similarly, the StreamBase Python Client Library includes methods that apply capture strategies: Client.getSchemaForStream(string entity, CaptureTransformStrategy strategy = FLATTEN) returns the runtime schema of a stream using the specified strategy. Also, Client.getStreamProperties(string entity, CaptureTransformStrategy strategy = FLATTEN) returns a description of a stream using the specified strategy.
The Operator base class for all StreamBase operators and adapters was extended with a method setCaptureStrategy(CaptureTransformStrategy captureStrategy). Call this method during the typecheck phase of your operator or adapter to specify your preferred capture field behavior.
If you do not call this method, the default FLATTEN strategy is used. In addition, the methods getRuntimeInputSchema, getRuntimeOutputSchema, getTypecheckInputSchema, and getTypecheckOutputSchema were added to the Operator class. The existing methods getInputSchema and getOutputSchema are still present, with new behavior. These methods function as shown in the following table:
| Method | When called before init() | When called after init() |
|---|---|---|
| getTypecheckInputSchema | Returns the input schema used at compile time, without any capture substitutions. | Same |
| getTypecheckOutputSchema | Returns the output schema used at compile time, without any capture substitutions. This is the same as the schema passed to setOutputSchema during typecheck. | Same |
| getRuntimeInputSchema | Error | Returns the input schema for the operator at runtime, with capture fields transformed using the specified CaptureTransformStrategy. This schema is also suitable for creating tuples in their optimized representation. |
| getRuntimeOutputSchema | Error | Returns the output schema for the operator at runtime, with capture fields transformed using the specified CaptureTransformStrategy. This schema is also suitable for creating tuples in their optimized representation. |
| getInputSchema | Equivalent to getTypecheckInputSchema | Equivalent to getRuntimeInputSchema |
| getOutputSchema | Equivalent to getTypecheckOutputSchema | Equivalent to getRuntimeOutputSchema |
The method getSchemaForCapture is still present in the API and still works, but operators and adapters are not likely to need to call it.
Capture fields make modules more reusable by allowing inner modules to accept supersets of their input schemas. However, as the above example illustrates, in some reuse contexts the names of captured fields can conflict with names of fields that sub-modules generate and output. Should applications potentially have this problem, outer modules can further encapsulate fields captured by inner modules at run time by reconstituting them as subfields of a field of type tuple. That is, when they exit an inner module, they are nested within a placeholder field.
Nesting captured fields is a runtime operation that you choose as a capture transform strategy. The default capture transform strategy, called FLATTEN, is not to nest captured tuples in this manner, as nesting is usually unnecessary and complicates schemas. The FLATTEN strategy expands capture fields at the same level as non-captured fields. The other capture transform strategy, NEST, encapsulates and expands captured fields as type Tuple. Use NEST to avoid duplication of field names, at the cost of a more layered schema. The two strategies are also settable properties of binary and CSV input and output file adapters, and several others.
To nest capture fields within an application, you can use the Runtime Schema Cast operator, which casts its input schema to its configured target output schema at run time. The Capture Fields for Generic Data Store sample included with StreamBase uses this Java operator to demonstrate how to use operator API methods to place data from streams into capture fields.
The default strategy for viewing a schema from a client connection or a Java operator is to flatten captured fields into separate fields in the output schema. Logically, this is equivalent to passing the capture field out through each level of module nesting, all the way to the top level module so that the fields in the output schema are the union of the non-capture fields in the schema with all the captured fields. Referring to the example provided above, consider:
In the capture_outer_no_conflict.sbapp module, the capture field @remainder is bound to the schema {name string, color string} at runtime. The stream default.inner.intermediate thus has the schema {x int, y int, name string, color string, area int} at runtime.
The primary advantage of the flatten transform is that it presents the data straightforwardly. Use the flatten strategy for most cases.
Unfortunately, there exist runtime schemas that have no valid flatten representation. In the module capture_outer_conflict.sbapp, the capture field @remainder is bound to the schema {area double} at runtime. Thus, the stream default.inner.intermediate does not have a valid schema, because that would require two different fields named area.
The NEST strategy turns each capture field into a tuple whose type is the runtime type of the capture field.
As before, consider the capture_outer_no_conflict.sbapp module. The stream default.inner.intermediate has the schema {x int, y int, r {name string, color string}, area int}.
Now consider the capture_outer_conflict.sbapp module. The stream default.inner.intermediate has the schema {x int, y int, r {area double}, area int}.
The primary advantage of the NEST strategy is that all streams have a valid representation. The NEST strategy's drawback is
the extra level of nesting you see in the r sub-tuple in this example. Use the NEST strategy for situations where you must access tuples for debugging, or for saving
tuples from internal streams to a file that will then be restored within the same module.
The following table shows the schemas for the capture_outer_no_conflict.sbapp module under different capture field strategies:
| Stream | Compile Time Schema | Runtime FLATTEN Schema | Runtime NEST Schema |
|---|---|---|---|
| default.instream | {x int, y int, name string, color string} | {x int, y int, name string, color string} | {x int, y int, name string, color string} |
| default.inner.instream | {x int, y int, r @remainder} | {x int, y int, name string, color string} | {x int, y int, r {name string, color string}} |
| default.inner.intermediate | {x int, y int, r @remainder, area int} | {x int, y int, name string, color string, area int} | {x int, y int, r {name string, color string}, area int} |
| default.inner.outstream | {x int, y int, r @remainder} | {x int, y int, name string, color | {x int, y int, r {name string, color string}} |
| default.outstream | {x int, y int, name string, color string} | {x int, y int, name string, color string} | {x int, y int, name string, color string} |
The following table shows the schemas for the capture_outer_conflict.sbapp module:
| Stream | Compile Time Schema | Runtime FLATTEN Schema | Runtime NEST Schema |
|---|---|---|---|
| default.instream | {x int, y int, area double} | {x int, y int, area double} | {x int, y int, area double} |
| default.inner.instream | {x int, y int, r @remainder} | {x int, y int, area double} | {x int, y int, r {area double}} |
| default.inner.intermediate | {x int, y int, r @remainder, area int} | Error, multiple fields named area | {x int, y int, r {area double}, area int} |
| default.inner.outstream | {x int, y int, r @remainder} | {x int, y int, area double} | {x int, y int, r {area double}} |
| default.outstream | {x int, y int, area double | {x int, y int, area double} | {x int, y int, area double} |