利用回归模型,您可以使用 Spotfire Enterprise Runtime for R 引擎创建回归模型,而无需亲自编写任何脚本。
开始之前
必须在已安装的客户端中创建回归模型。注: 预测模型工具使用基于 Spotfire Enterprise Runtime for R(又名 TERR)的数据函数来执行计算。Spotfire 环境必须支持 TERR 数据函数才能使用这些工具。有关详细信息,请参见
脚本和数据函数的使用。
过程
-
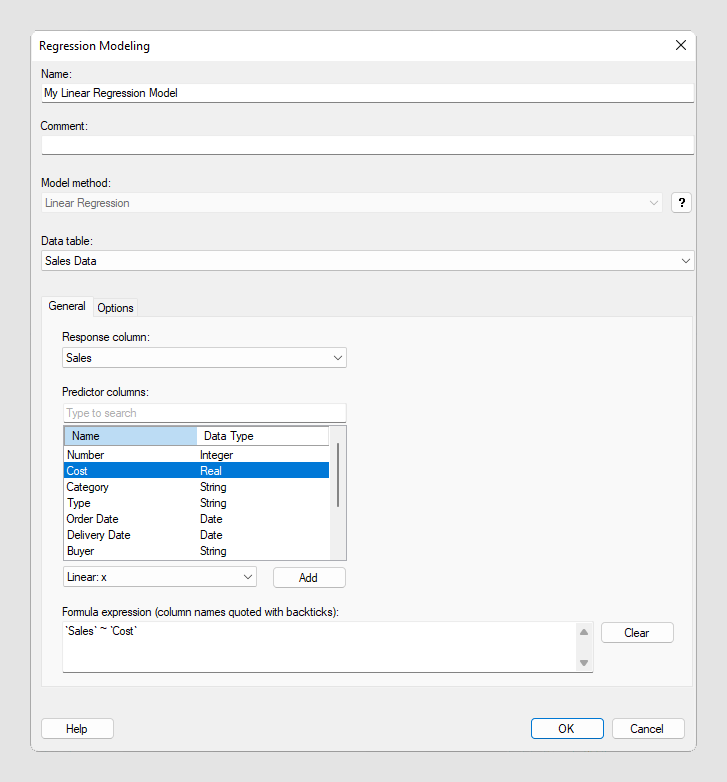
在菜单栏上,选择。
-
添加您希望在“分析模型”面板中引用的模型的“名称”。
-
在模型上添加“注释”以描述应将此模型用于哪种类型的数据。
-
选择要使用的“模型方法”。
-
选择计算模型所依据的“数据表”。
-
在“常规”选项卡上,指定“反应列”。
反应列指定您尝试预测的内容。
选定数据表中的数值列均可供选择。
注: 数据类型为 Currency 的列转换为 Real 时会导致模型精确度下降。
选定反应列会自动添加到“公式表达式”字段。
-
在“预测器列”下,选择您认为对您尝试预测的值(选定的反应列)可能会有影响的一个或多个变量,为变量指定合适的转换(如果需要),然后单击“添加”。重复上述操作添加更多变量。
列出选定数据表中可用作预测器列的所有列。
注: 数据类型为 Currency 的列转换为 Real 时会导致模型精确度下降。
选定转换方法应能反映出反应列和选定预测器列之间的预期关系。例如,如果反应列预期与其他列有线性关系,那么应使用 Linear: x 方法将此列添加为预测器列。如果两列之间的关系为对数,那么可以使用 Log: log(x) 方法添加预测器列。
“公式表达式”字段将更新以显示反应列和选定预测器列之间的关系。
提示: 如果您要创建更高级的表达式,也可以手动编辑公式表达式字段。单击“清除”以清除公式表达式字段。
-
或者,您可以在“选项”选项卡上为模型提供更多输入。线性回归模型和回归树模型都允许您“使用权重列”。
权重列用于通过按权重列中的数字倍增来增大或减小特定行中值的重要性。
对于
“回归树”模型,您还可以定义以下参数:
- 最小分割 – 指定节点中可进行拆分的观察值的最小数目。
- 复杂度参数 – 用于控制回归树的大小以及选择最佳树大小。如果向当前节点的回归树添加其他变量与复杂性参数的价值相比耗费更高的成本,则树的构建将会停止。仅当总体失拟随复杂性参数的某一因素降低时,树的构建才会继续。如果复杂性参数设置为零,那么树将构建至其最大深度,可能会非常大。
- 最大深度 – 指定树中任何节点的最大深度。
- 交叉验证组大小 – 指定交叉验证组大小。
-
完成配置后,单击“确定”。
简单的回归模型
在此示例中,我们添加了一个非常简单的模型,其中假设销售数字与购买成本线性相关: