As described above Managed Objects are backed by shared memory. They can also be distributed and replicated.
Managed Objects are stored in shared memory, outside of the JVM heap. StreamBase supports two types of shared memory:
-
Memory Mapped File — uses a memory-mapped file that stores the shared memory contents on a file system.
-
System V — uses real memory that is not backed to a file system.
Managed Objects continue to exist if the engine containing a JVM is stopped. When the engine restarts all of the Managed Objects are still available for access by the application.
Managed Objects also continue to exist if an entire node is shut down. When the node is restarted all of the Managed Objects are still available for access by the application.
Since Memory Mapped File shared memory is backed to the file system, this shared memory exists after a normal machine shutdown. This means that all Managed Objects are still available when the node is restarted on the machine. System V shared memory does not survive machine restarts, so if System V shared memory is being used the Managed Objects are lost.
For Managed Objects to survive a node or machine failure they must be replicated to another machine using the High Availability services described in High Availability in Depth or be backed by a secondary store that stores the data off of the machine.
Durability summary provides a summary Managed Object durability with the different supported storage types.
Durability summary
| Storage Type | Engine Restart | Node Restart | Machine Restart | Node Failure | Machine Failure |
| Memory Mapped File | Survive | Survive | Survive | Replication required | Replication required |
| System V | Survive | Survive | Replication required | Replication required | Replication required |
| Memory Mapped File or System V + Secondary Store | Survive | Survive | Survive | Survive | Survive |
An extent is a collection of all Managed Objects that have been accessed on the local node. All Managed Objects have extents automatically maintained. Extents contain references to objects created on the local node and remote references for objects that were pushed (replicated) or pulled to the local node.
Managed Objects optionally support triggers. A trigger provides a mechanism to be notified when a Managed Object is updated, deleted, or a conflict detected while restoring a node following a multi-master scenario.
Managed Objects can optionally have one or more keys defined using annotations. When a key is defined on a Managed Object, an index is maintained in shared memory as Managed Objects are created and deleted. An index associated with a replicated or distributed Managed Object is maintained on all nodes to which the object exists.
By default key values are immutable — they cannot be changed after an object is created. Mutable keys are also allowed if explicitly specified in the key annotation.
You can specify explicit transaction locking when doing a query via one of these lock types:
-
None — no transaction lock is taken on the objects returned by the query.
-
Read — a transaction read lock is taken on all objects returned by the query.
-
Write — a transaction write lock is taken on all objects returned by the query.
The lock type specified when performing a query only has impact on the query result. It does not affect the standard transaction locking as described in Locking when operating on the objects returned from the query.
A query can be scoped to the local node only, a user defined subset of the nodes in a cluster, or all nodes in a cluster. This allows object instances to be located on any node in a cluster. When a query executes on remote nodes it is called a distributed query.
When a query is executed on multiple remote nodes, the query executes in parallel and the result set is combined into a single result set returned to the caller. The returned result set is guaranteed to contain only a single instance of an object if an object exists on multiple nodes (replicated or distributed).
A query scoped to a local node only returns objects that are already on the local node. These objects may have been created on the local node, returned from a remote node using a distributed query, or replicated to the local node.
If an object is returned from a remote node that does not already exist on the local node, it is implicitly created on the local node. This causes a write lock to be taken for this object. The lock type specified when performing the query is ignored in this case. The caching of objects returned from remote nodes is controlled using Named Caches as described in Named Caches.
When a user-defined query scope is used, the nodes in the query scope can be audited when the query is executed. The possible audit modes are:
-
Verify that the query scope contains at least one node. No other auditing is performed.
-
Verify that the query scope contains at least one node and that distribution is enabled. Any inactive nodes are skipped when a query is performed.
-
Verify that the query scope contains at least one node and that distribution is enabled. Any inactive nodes cause a query to fail with an exception.
Query support is provided for:
-
Unique and non-unique queries
-
Ordered and unordered queries
-
Range queries
-
Cardinality
-
Atomic selection of an object that is created if it does not exist
Methods on managed objects can be defined as asynchronous. Asynchronous methods are not queued for execution until the current transaction commits. When the current transaction commits, a new transaction is started and the method is executed in the new transaction. If a deadlock is detected while executing an asynchronous method, the transaction aborts, a new transaction is started, and the method is re-executed.
The default transaction isolation of the transaction started to execute an asynchronous method is Serializable. The default isolation level can be changed to Read Committed — Snapshot using an annotation.
Asynchronous methods are queued to the target object and are executed one at a time, in the same order in which they were queued. Only one asynchronous method can be executed by a particular object at a time. The following ordering guarantees are made:
-
An object executes asynchronous methods from a single sender object in the same order that they are sent.
-
An object executes asynchronous methods from multiple senders in an indeterminate order. This order may or may not be the same order in which they were sent.
-
An asynchronous method sent from an object to itself is processed before any other queued asynchronous methods to that object.
Asynchronous methods can be called on a distributed object. The method will be executed on the master node for the object. However, the method is always queued on the local node — it is not sent to the remote target node until after the current transaction commits.
If the target object of an asynchronous method is deleted before the method executes, the method execution is discarded.
When a JVM is shut down, any queued asynchronous methods that have not executed are executed when the JVM restarts.
Named caches provide a mechanism to control the amount of memory used to cache managed objects. Named caches can be dynamically defined, and managed objects added, at runtime without affecting a running application. Named caches support configurable cache policies and support for automatic, and explicit managed object flushing.
The default caching policies for managed objects when they are not associated with a named cache are:
-
Distributed objects (see Distributed Computing in Depth) are never cached.
-
Replica objects (see High Availability in Depth) are always cached, and cannot be flushed.
Named caches are defined using an API or administrative commands.
Named caches support these cache policies:
-
Always — object data is always accessed from shared memory on the local node. These objects are never flushed from shared memory.
-
Never — object data is never accessed from shared memory on the local node. These objects are always flushed from shared memory. This cache policy is defined by setting the cache size to zero.
-
Sized — object data is always accessed from shared memory on the local node. These objects are automatically flushed from shared memory when they exceed a configurable maximum memory consumption size.
You specify cache policies per named cache; they can be dynamically changed at runtime.
The implications of caching a distributed object are described in Reading and Writing Object Fields.
Managed objects are associated with a named cache by class name at runtime. When a class is associated with a named cache, all objects of that type are moved into the cache, along with any objects that extend the parent class (that are not already associated with a cache).
Named caches support inheritance. If a class is associated with a named cache all objects with that class as their parent are moved into the named cache. If another named cache is defined and a child class of the parent is associated with it, only the child objects (and any of its children) are moved into the named cache. All other objects are left in the parent's named cache.
You can flush all managed objects from shared memory, except for replica objects.
Cached objects are flushed from shared memory:
-
Explicitly using an API.
-
Automatically at the end of the current transaction (only distributed objects not in a named cache).
-
Using a background flusher when associated with a named cache.
Regardless of how an object is flushed, it has this behavior:
-
flushing a local managed object, including partitioned objects on the active node, is equivalent to deleting the object. Any installed delete triggers are executed.
-
flushing a distributed object removes the object data from local shared memory, including any key data.
-
flushing a replica object is a no-op. Replica objects cannot be flushed since that would break the redundancy guarantee made in the partition definition.
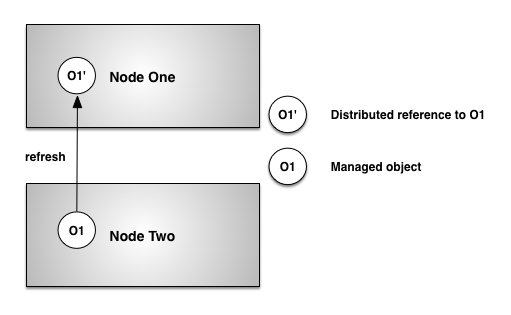
Figure 1, “Object refresh” shows how a distributed object is refreshed after it was flushed from memory. O1` is a distributed reference to O1 that was stored in an object field on Node One. Accessing the field containing the O1` distributed reference on Node causes the object data to be refreshed from OneNode.
Two
Distributed objects not in a named cache are automatically flushed from shared memory at the end of the transaction in which they were accessed. These objects are never in shared memory longer than a single transaction.
A background flusher evicts objects from shared memory in named caches. Objects are flushed from shared memory when the total bytes in shared memory exceeds the configured maximum size. Objects are flushed from shared memory using a Least Recently Used algorithm. The background flusher operates asynchronously, so the maximum memory utilization may be temporarily exceeded.
Objects are also automatically flushed from shared memory when memory throttling is in effect (for example when a distributed query fetches a large number of remote objects that cause local cache limits to be exceeded).
When calculating the size of shared memory required for a node, cached objects must be included in the sizing. See the TIBCO StreamBase Sizing Guide.
Optionally, applications can install a flush notifier to control whether an object is flushed or not. When a flush notifier is installed it is called in the same transaction in which the flush occurs. The notifier is passed the object that is being flushed, and the notifier can either accept the flush or reject it. If the notifier rejects the flush, the object is not flushed from shared memory. The flush notifier is called no matter how an object flush was initiated.