Example 2: Predicting Redemption of Coupons
In this example, an alternative way of setting up data files for a probit or logit analysis will be demonstrated. Note that Logistic (Logit) and Probit regression models can also be fit using the Generalized Linear/Nonlinear Models (GLZ) facilities of STATISTICA; GLZ contains options for fitting ANOVA and ANCOVA-like designs to binomial and multinomial response variables, and provides methods for stepwise and best-subset selection of predictors.
The data set to be analyzed is reported in Neter, Wasserman, and Kutner (1985, page 365) and describes the results of a study of coupon redemption. Specifically, coupons were sent to 1000 randomly selected homes. These coupons differed in their value, that is, with regard to the price reduction offered (either 5, 10, 15, 20, or 30 cents off). Each type of coupon was sent to 200 households. The dependent variable of interest was how many coupons of each type were redeemed. These data are recorded in the file Coupons.sta. Open this data file by selecting Open Examples from the File menu (classic toolbar) or by selecting Open Examples from the Open menu on the Home tab (ribbon bar); it is in the Datasets folder.
An alternative way of setting up data files for a probit or logit analysis is demonstrated in this example. The Logistic (Logit) and Probit regression models can also be fit using the Generalized Linear/Nonlinear Models (GLZ) facilities of STATISTICA : GLZ contains options for fitting ANOVA and ANCOVA-like designs to binomial and multinomial response variables, and provides methods for stepwise and best-subset selection of predictors.
The data set to be analyzed is reported in Neter, Wasserman, and Kutner (1985, page 365) and describes the reults of a study of coupon redemption.
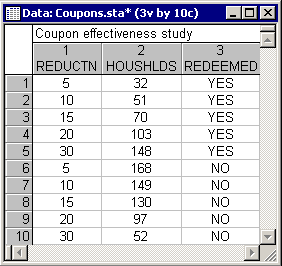
- Data file
- In this data file, the number of households that did and did not redeem the coupons were recorded. Thus, the dependent variable (likelihood of coupon redemption) really consists of two variables; namely the variable Redeemed, which contains the codes to indicate whether or not coupons were redeemed, and the variable Houshlds, which contains the counts, that is, information about how many households did or did not redeem the coupon. In a sense, you can think of this data file setup as a crosstabulation table of price reduction by redemption, where the variable Houshlds contains the frequencies. In this manner, even very large studies can be summarized in a relatively small file.
- Specifying the analysis
- Neter et al. (1985) fit a logit model to these data (using weighted least squares estimation). Select Nonlinear Estimation from the Statistics - Advanced Linear/Nonlinear Models menu to display the Nonlinear Estimation Startup Panel.
Double-click Quick Logit regression on the Quick tab of the Startup Panel. In the Logistic Regression (Logit) dialog, select Codes and counts in the Input file contains box. Now, click the Variables button and specify Redeemed as the Dep. variable, Reductn as the Indep. variable(s), Houshlds as the Count variable (variable containing the frequency counts), and then click the OK button.
Logit and probit regression models, in a sense, predict probabilities underlying the dichotomous dependent variable, and these methods will produce predicted (expected) values in the range between 0 and 1 (for details, see Common Nonlinear Regression Models). If the dependent variable is not coded in this way, that is, as 0 and 1, then you must specify the respective codes in the Codes for dep. var. boxes. As the data are read, the dependent variable will then be transformed so that all values that match the first code become 0 (zero), and all values that match the second code become 1
In our data file, No is already assigned a numeric value of 0, while Yes is assigned a value of 1. Therefore, we need to specify No as the first code and Yes as the second code. To do so, double-click on the respective Codes for dep. var. fields and enter No and Yes (as shown below).
Click the OK button in the Logistic Regression (Logit) dialog to display the Model Estimation dialog where you select the Asymptotic Standard Errors check box (if it is not already selected) on the Advanced tab. Now, click the OK button to briefly display a window containing the values of the loss function and the current estimate for each parameter at each iteration. After a few iterations the estimation procedure will converge, that is, arrive at the final parameter estimates and the Results dialog is displayed.
- Reviewing results
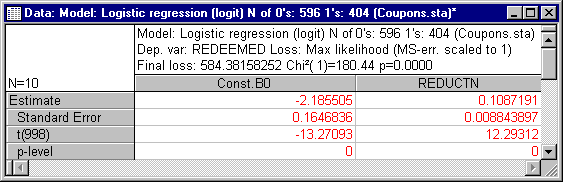
- The Chi-square value for the difference between the intercept-only model and the current model is highly significant. Thus, we can conclude that variable Reductn is a significant predictor of the likelihood of coupon redemption. Next click the Summary: Parameters & standard errors button on the
Quick tab.
In this particular example, these parameter estimates are useful for predicting the rate of redemption for coupons offering an intermediate price reduction. For example, suppose you want to estimate the expected proportion of coupons worth 25 cents that will be redeemed. Following the logit model, you could compute:
Logit = -2.186 + .109*25 = .539
Now remember that logits are computed as log[p/(1-p)]; thus, you can compute p as:
p = exp(logit)/[1+exp(Logit)]
= .632
Therefore, you can expect that roughly 63% of the 25-cent coupons would be redeemed.


Data file
In a sense, you can think of this data file setup as a crosstabulation table of price reduction by redemption, where the variable Households contains the frequencies. In this manner, even very large studies can be summarized in relatively small file.
In this data file, the number of households that did and did not redeem the coupons were recorded. Thus, the dependent variable (likelihood of coupon redemption) really consists of two variables; namely the variable Redeemed, which contains the codes to indicate whether or not coupons were redeemed, and the variable Houshlds, which contains the counts, that is, information about how many households did or did not redeem the coupon. In a sense, you can think of this data file setup as a crosstabulation table of price reduction by redemption, where the variable Houshlds contains the frequencies. In this manner, even very large studies can be summarized in a relatively small file.