Working with Data Channels
This page shows us how to configure and deploy data channels.
Contents
Overview
A data channel is a configurable and deployable component that maps between an external protocol and scoring flows. A data sink is a data channel that consumes output data with a known schema and a standard serialization format. It defines the format of the end result. On the other hand, a data source is a data channel that provides input data with a known schema and a standard serialization format.
Adding a Data Channel
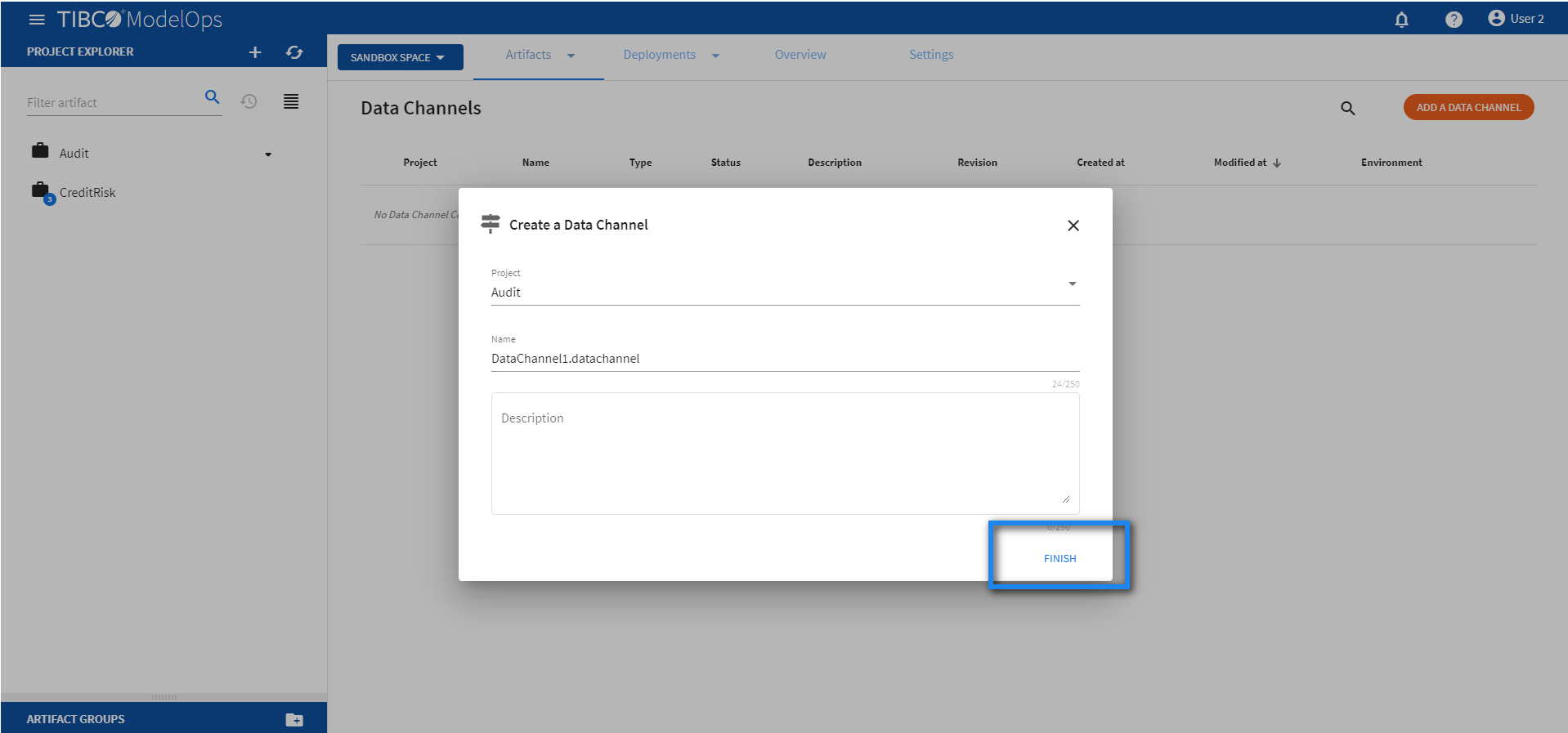
- On the main screen, click the drop down menu for Artifacts tab and select Data Channels.
- Click ADD A DATA CHANNEL to create a new data channel. You can also click the Add one option to add a new data channel if there are none present.
- On the Create a Data Channel page, select the project, for which you wish to create the data channel, from the drop-down list.
- Add data channel name. The extension is added automatically. Also, add the description, if needed.
- Click FINISH.
Configuring Data Channels
This section shows how to configure a data channel.
Configuring Kafka Data Channels
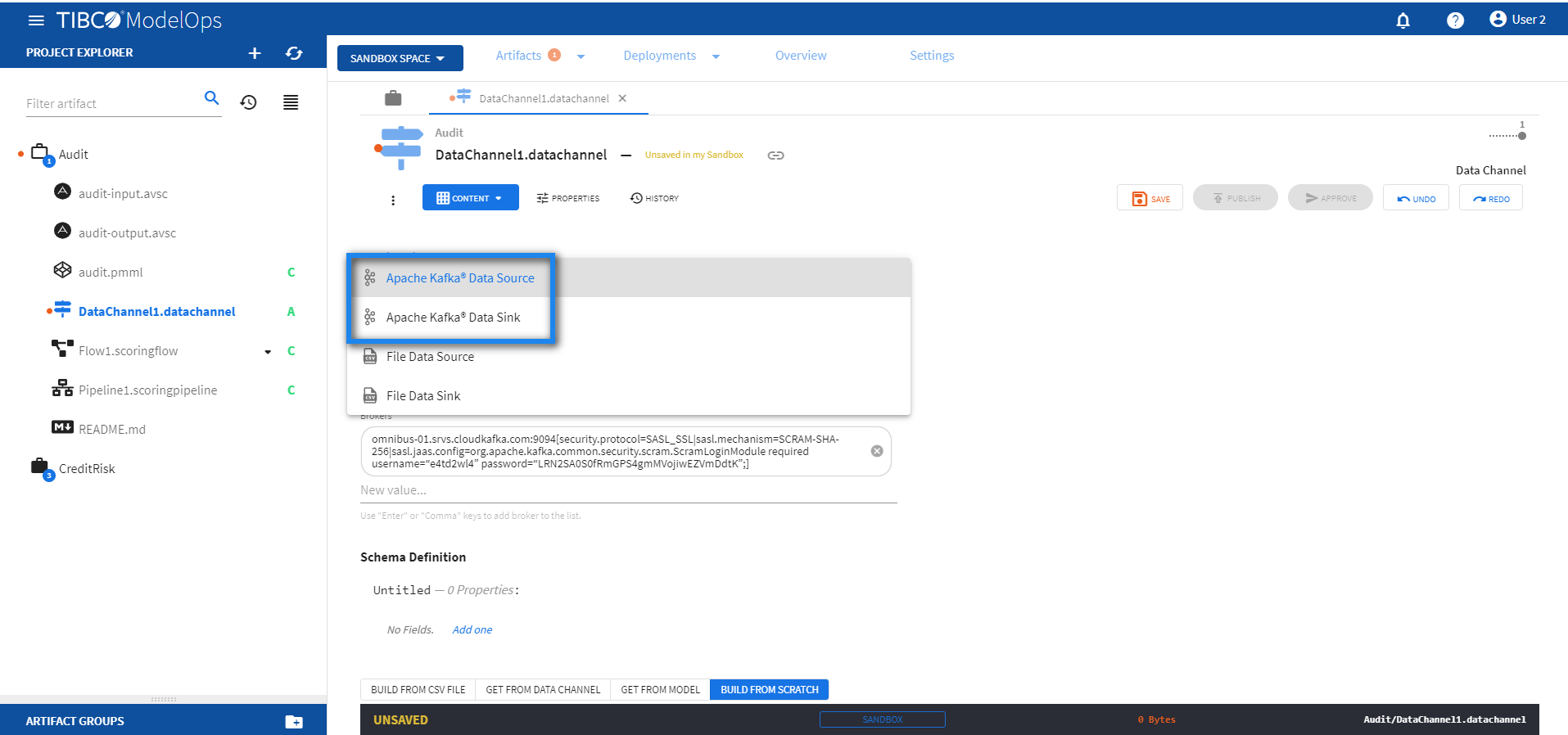
- On the main screen, click the drop down menu for Artifacts tab and select Data Channels.
- Select the data channel, which you wish to configure, from the list.
- On the Data Channel Type tab, select Apache Kafka® Data Source/Sink from the down-list.
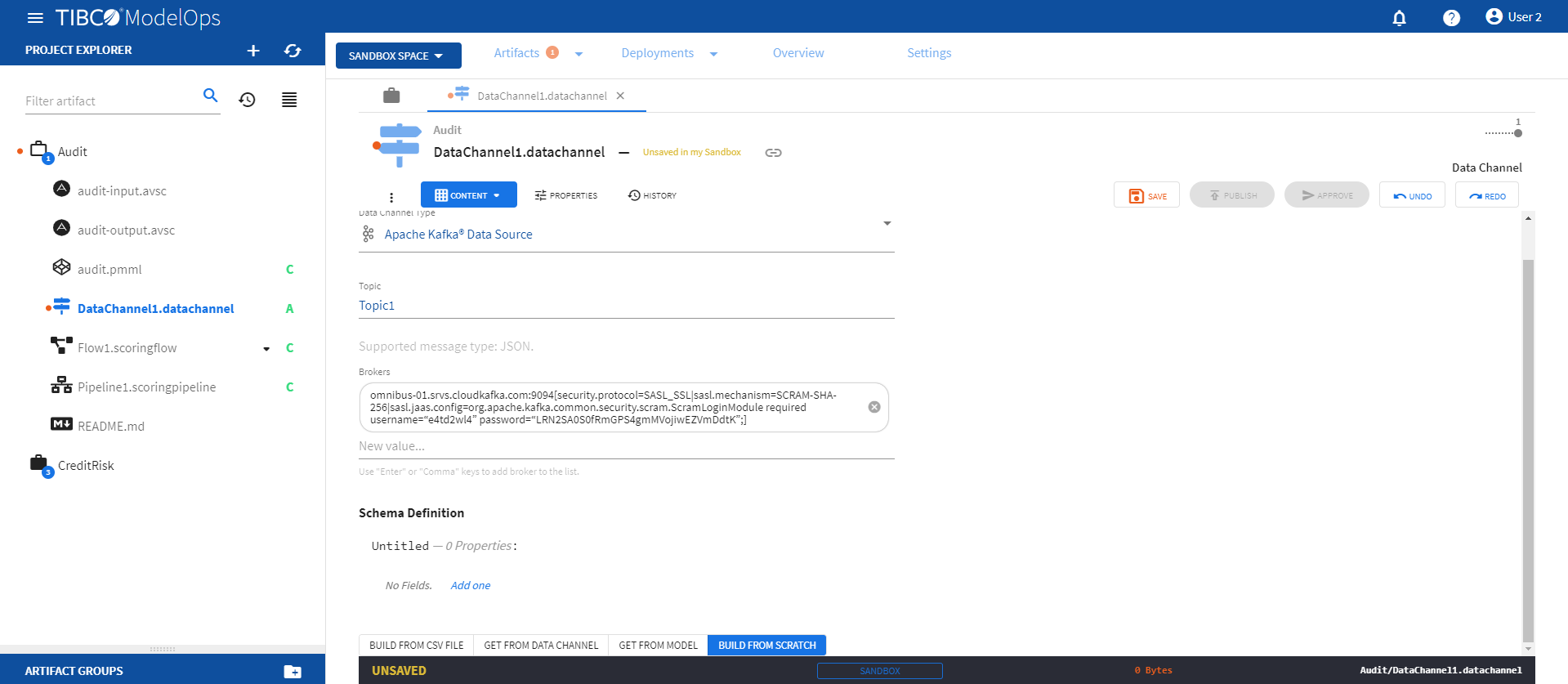
-
Add topic under the respective field.
- Next, add brokers in the respective fields.
- A broker is comma-separated list of address:port[config=value|config=value] Kafka brokers. The default value is
localhost:9092. This value can also be an Azure Event Hubs connection string. The config=value section of the broker list allows you to specify advance configuration directly in the broker list. - For example, if you require a security.protocol and security.mechanism, you can specify a broker list:
test.com:9093[security.protocol=SASL_SSL,sasl.mechanism=PLAIN|sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username=“admin” password=“********”;]test2.com:9093[security.protocol=SASL_SSL|sasl.mechanism=SCRAM-SHA-256|sasl.jaas.config=org.apache.kafka.common.security.scram.ScramLoginModule required username=“admin” password=“********”;]
- A broker is comma-separated list of address:port[config=value|config=value] Kafka brokers. The default value is
- On the Schema definition tab, you get the following option to add a schema definition.
- Build from CSV file: Extracts schema from a CSV file. You need to select a csv file if you choose this option.
- Get from data channel: Adds schema from an existing data channel. You need to select a data channel if you choose this option.
- Build from model: Extracts schema from a model. You need to select a model if you choose this option.
- Build from scratch: Builds schema from scratch.
- Once done, click SAVE and then PUBLISH.
- This publishes your data channel to Published Space.
Configuring File Data Channels
- On the main screen, click the drop down menu for Artifacts tab and select Data Channels.
- Select the data channel, which you wish to configure, from the list.
- On the Data Channel Type tab, select File Data Source/Sink from the down-list.
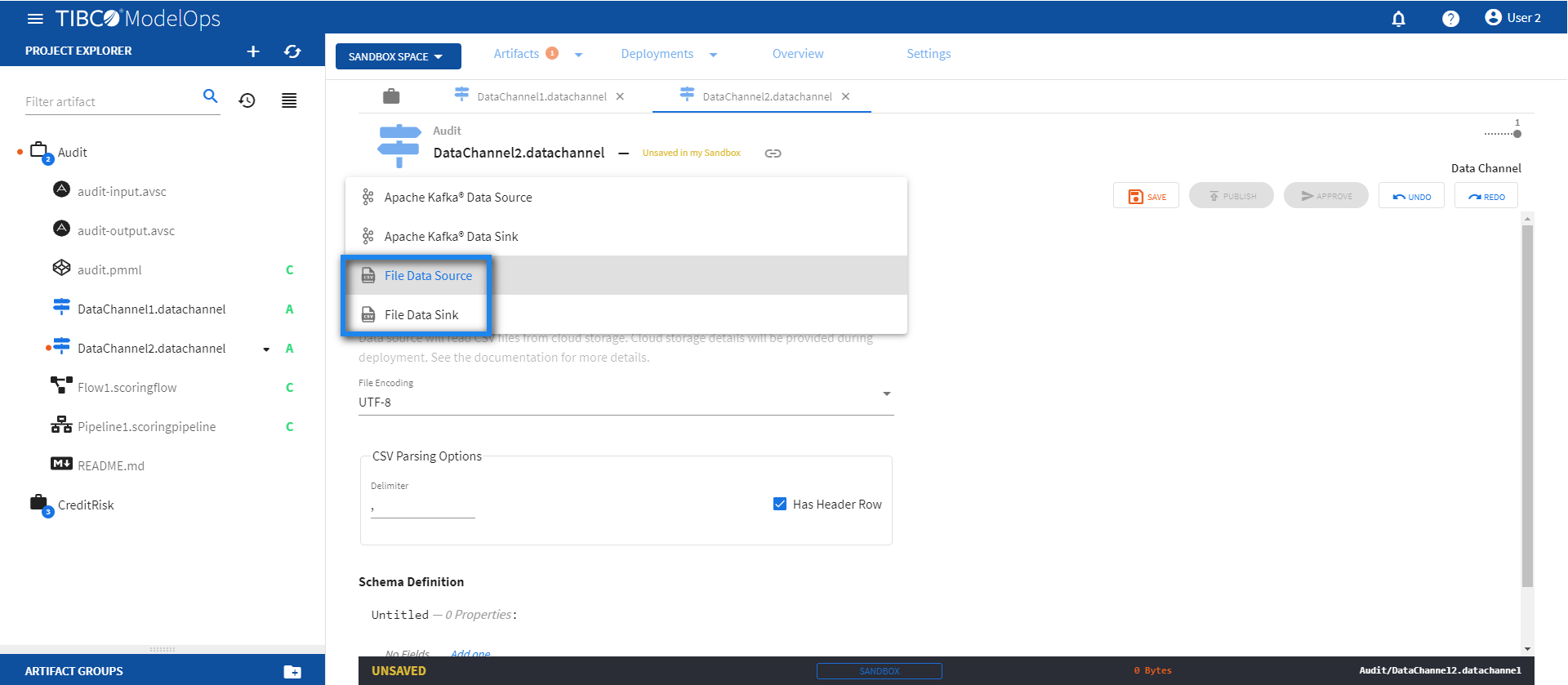
-
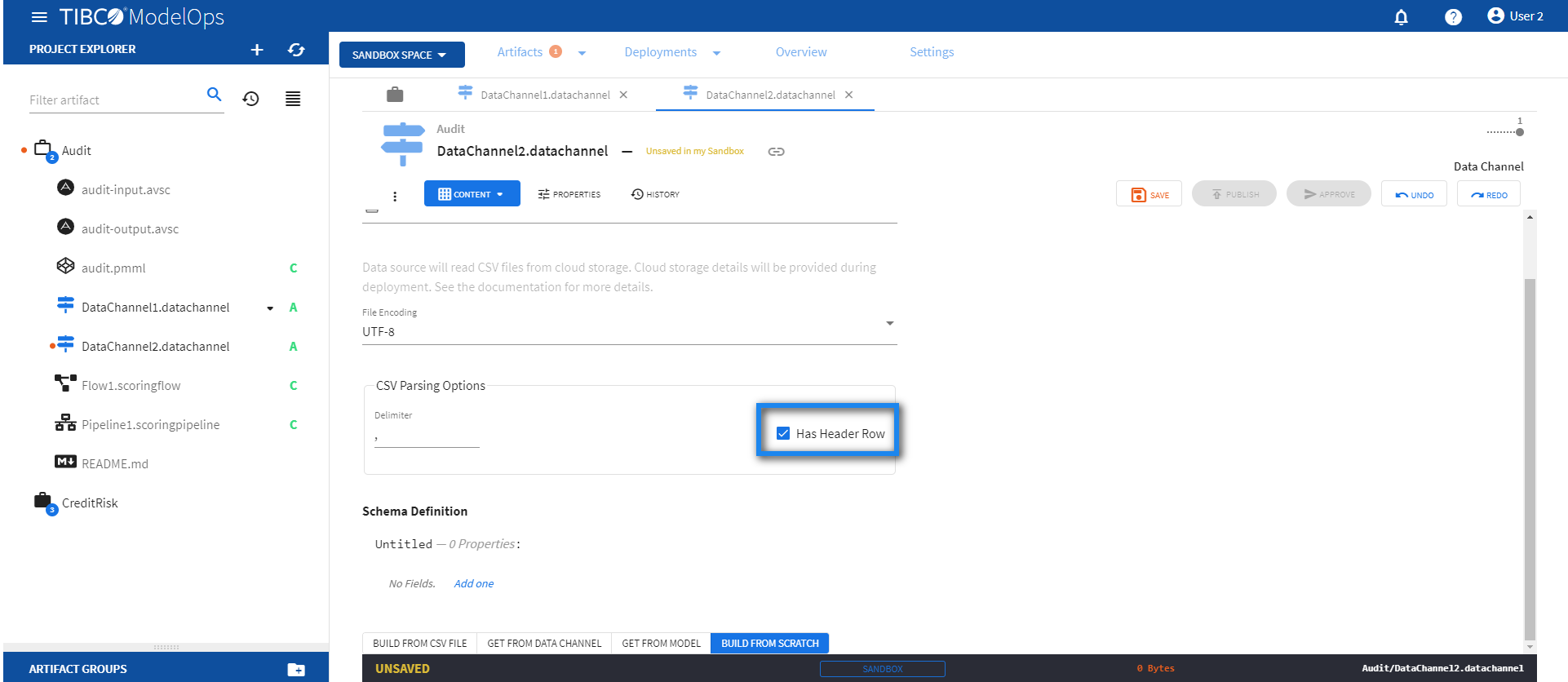
Under File Encoding, select an encoding value from the drop down list.
- For CSV Parsing Options, enter the value in the Delimiter field. You also get the option to check off the Has Header Row option.
- On the Schema definition tab, you get the following option to add a schema definition.
- Build from CSV file: Extracts schema from a CSV file. You need to select a csv file if you choose this option.
- Get from data channel: Adds schema from an existing data channel. You need to select a data channel if you choose this option.
- Build from model: Extracts schema from a model. You need to select a model if you choose this option.
- Build from scratch: Builds schema from scratch.
- Once done, click SAVE and then PUBLISH.
- This publishes your data channel to the Published Space.
Approving a Data Channels
- On the main screen, click the drop down menu for Artifacts tab and select Data Channels.
- Select the data channel that needs to be promoted by clicking on the check box next to the project name.
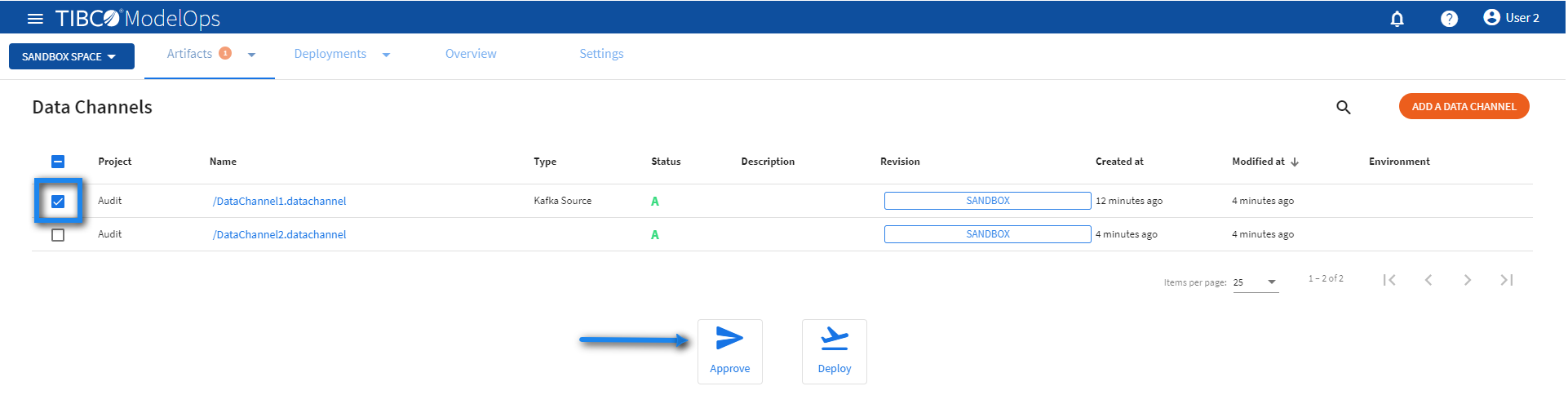
-
Click Approve present at the bottom of the screen.
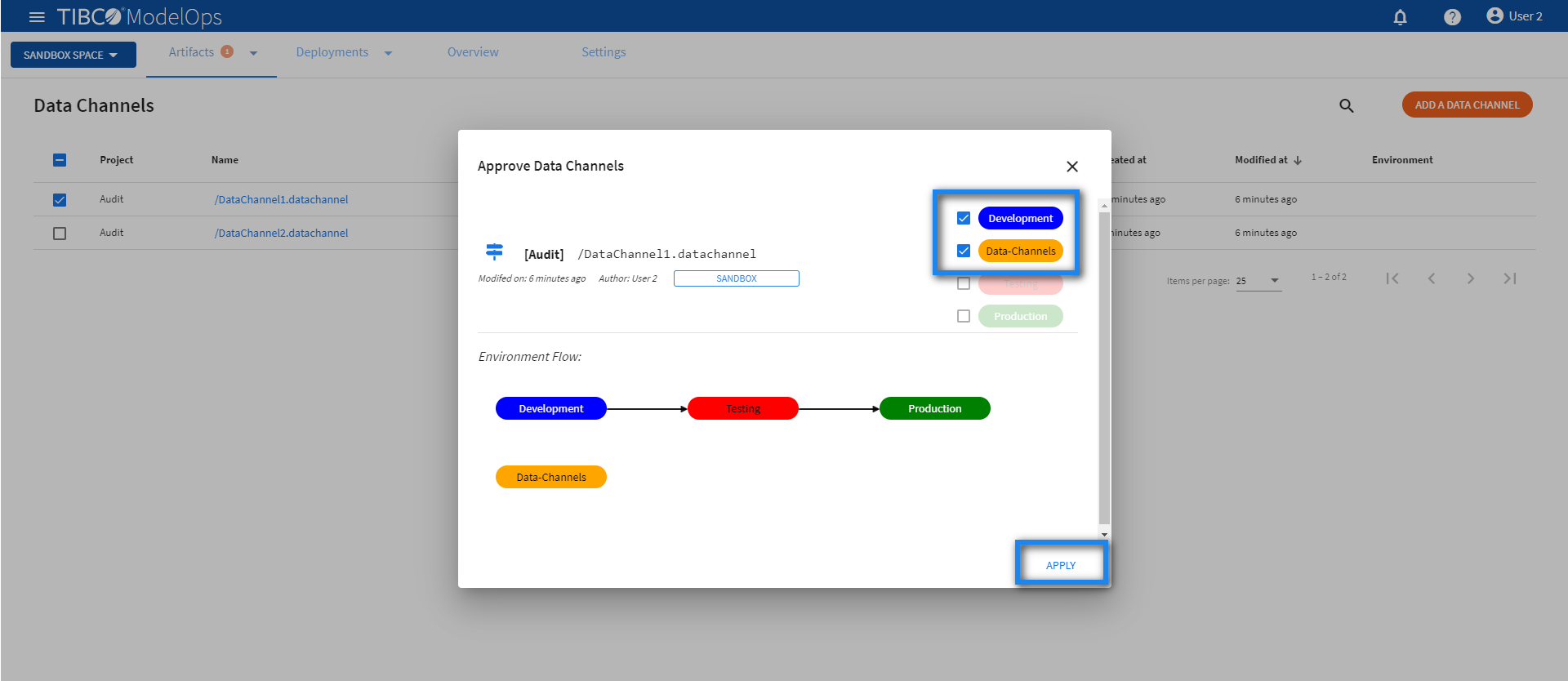
- Select the desired environments and click APPLY.
Deploying Data Channels
- On the main screen, click the drop down menu on Deployments tab and select Data Channels.
- Select the DEPLOY A DATA CHANNEL option.
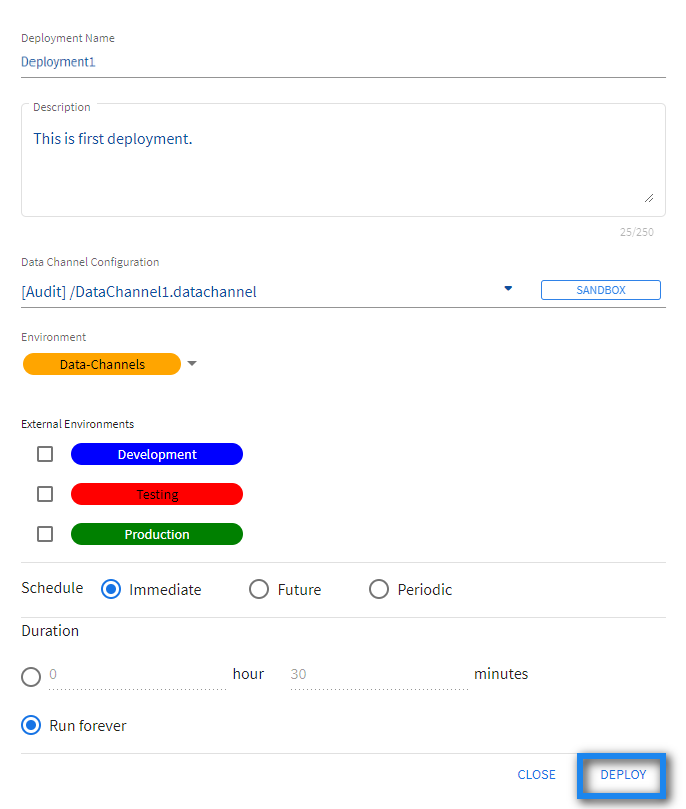
- Add deployment name and description in the respective field.
- Select Data-Channels environment from the drop down list.
- Select when you need to schedule the job from the given options (Immediate, Future, or Periodic).
- Select the duration for which you need to run the job. You can run the job forever or add the duration as per your needs.
- Click DEPLOY.
Note: You might see failure in pipeline deployment if the data channel is not accessible from the environment in which the scoring pipeline is being deployed.
- Consider a scenario where a Data channel is deployed to Data-Channels environment with Test and Production as external environments.
- Now, when you attempt to deploy pipeline to the Development environment, you might encounter a Pipeline deployment failure, since its data channel is not accessible from the Development environment (only Data-Channels, Test, and Production)
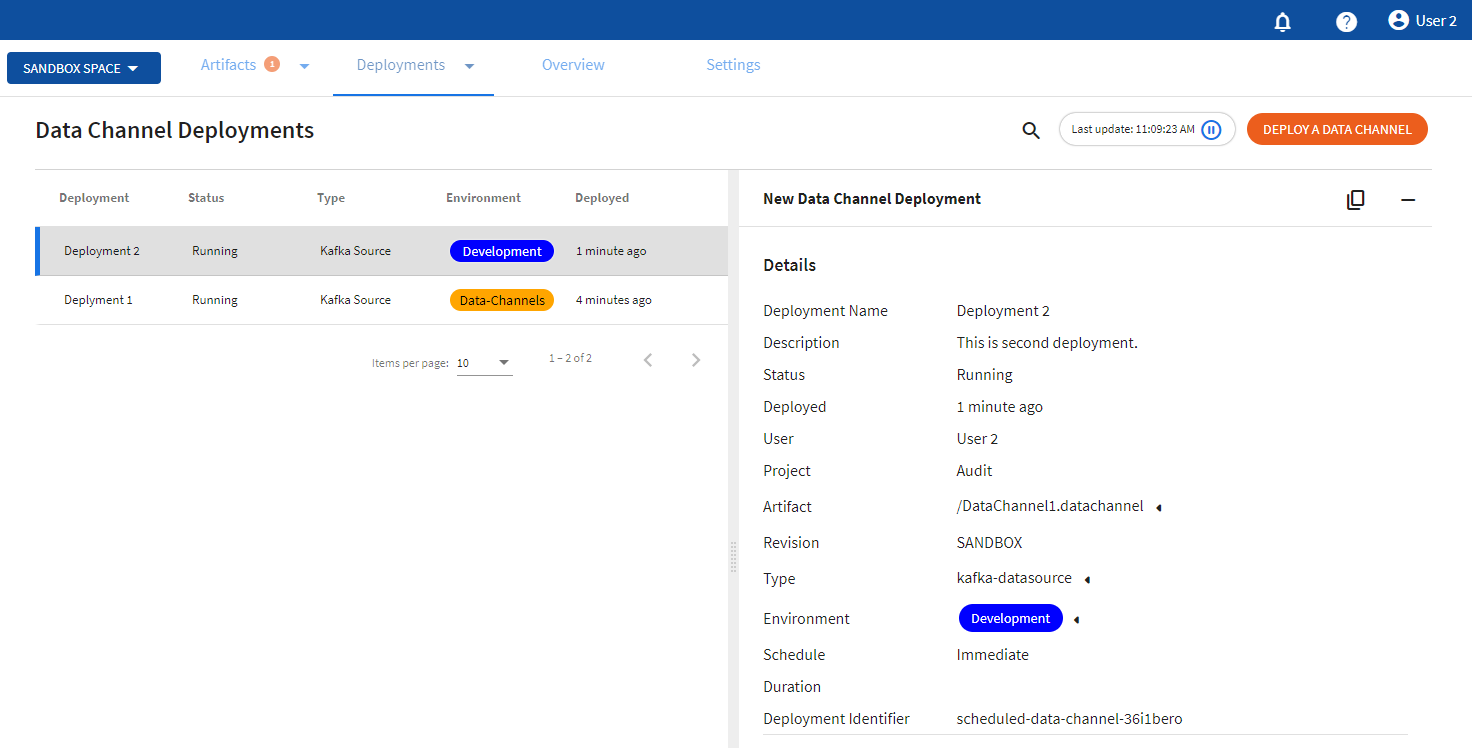
Viewing Data Channels
You can view status for deployed data channels by:
- Click the drop down menu on Deployments tab and select Data Channels.
- A list of deployed data channels appears here.
- The list is sorted based on the deployed time in ascending order.
- The list shows information such as Deployment name, status of the deployed data channel, type of data channel, environment, and time of deployment.
- Additional information is displayed on the right pane after clicking on the individual pipeline instance.