LDA Trainer
LDA (Latent Dirichlet Allocation) is an unsupervised text-mining algorithm used to analyze collections of unstructured documents.

Information at a Glance
For more information about using LDA, see Unsupervised Text Mining and LDA Training and Model Evaluation Tips.
Input
The LDA trainer requires two inputs:
- An HDFS tabular data set with at least a unique document ID column and a text content column (for example, the output of the Text Extractor operator). Note: The Text Featurization of 'Text Column' that converts raw text to N-Grams features is included in the LDA Trainer operator.
- An N-Gram Dictionary Builder (most likely created from the same tabular input connected to the LDA Trainer).
- Bad or Missing Values
- If a row contains a null value in at least one of the Doc ID column or Text Column, the row is removed from the data set. The number of null values removed can be listed in the Summary section of the output (depending on the chosen option for Write Rows Removed Due to Null Data To File).
Configuration
| Parameter | Description |
|---|---|
| Notes | Any notes or helpful information about this operator's parameter settings. When you enter content in the Notes field, a yellow asterisk is displayed on the operator. |
| Document ID Column | The column that contains the document unique ID (String, Int, or Long). This column must contain unique IDs. If duplicate values are found, the job fails with a meaningful error message. |
| Text Column | The column that contains the document text content (that is featurized based on N-Gram Dictionary Builder and Featurization input parameters). |
| N-Gram Selection Method |
The criteria used to choose the n-grams to pull out as word count features for the LDA (the criteria is applied to the training corpus; that is, the corpus used to create the N-Gram Dictionary).
Choose from the following options.
Note: If "Feature Hashing" option is selected:
|
| Maximum Number of Unique N-Grams to Select (Feature Hashing Size) |
The number of n-grams to select from the dictionary to use as features. If you selected Feature Hashing for the
N-Gram Selection Method parameter, this represents the size of the hash set. In either case, the total number of features in the featurized data set (used as input for LDA) is no greater than this number.
Default value: 500. |
| Number of Topics (k) | Select the number of topics to train the LDA. |
| Maximum Terms to Describe Topics | Select the maximum number of n-grams to describe topics. This parameter sets the number of top n-grams (= n-grams with highest weights for each topic) to use in the Topic Description data set output. |
| Maximum Topics to Describe Documents | Select the maximum number of topics to describe documents. This parameter sets the number of top topics (= topics with highest weights for each document) to use in the Top Topic Distribution data set output. |
| Document Concentration (α) (enter -1 for default) |
Dirichlet parameter for prior over documents' distributions over topics. Only symmetric priors are supported, which is the most commonly used configuration in LDA ( = uniform k-dimensional vector with value α).
Larger values of α encourage smoother inferred distributions (that is, each document is likely to contain a mixture of most of the topics), whereas lower values encourage sparse distributions. Values should be positive. Entering -1 results in default behavior for Online optimizer (=uniformkdimensional vector with value 1.0 / k). |
| Topic Concentration (β) (enter -1 for default) |
Dirichlet parameter for prior over topics' distributions over terms. Larger values encourage smoother inferred distributions (that is, each topic is likely to contain a mixture of most of the words), whereas lower values encourage sparse distributions.
Values should be positive. Entering -1 results in default behavior for Online optimizer (=uniformvector with value 1.0 / k). |
| Maximum Number of Iterations | Limit on the number of iterations. Default value is 30. |
| Automatic Optimization of α | Indicates whether Doc Concentration (α) - Dirichlet parameter for document-topic distribution - is optimized during training. |
| Mini-Batch Fraction | The fraction of the corpus sampled and used at each iteration. This parameter should be set in synch with Maximum Number of Iterations to ensure the entire corpus is used. Maximum Number of Iterations * Mini-Batch Fraction must be >=1, or a meaningful error occurs at design time. |
| Learning Rate (κ) |
The learning parameter for exponential decay rate. It should be set between [0.5, 1] to guarantee asymptotic convergence. The learning rate at each iteration number (t) is computed with the formula
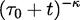
The default value for κ is 0.51, based on the original Online LDA paper. |
| Learning Parameter (τ0) | A (positive) learning parameter that down-weights early iterations. Larger values make early iterations count less. The default value is 1024, following the original Online LDA paper. |
| Use Checkpointing | Select Yes (the default) or No. Checkpointing helps with recovery when nodes fail, and also helps with eliminating temporary shuffle files on disk, which can be important when LDA is run for many iterations. |
| Write Rows Removed Due to Null Data To File |
Rows with null values (in the Doc ID Column or the Text Column) are removed from the analysis. This parameter allows you to specify that the data with null values be written to a file.
The file is written to the same directory as the rest of the output. The filename is bad_data.
|
| Output Directory | The location to store the output files. |
| Overwrite Output | Specifies whether to delete existing data at that path. |
| Advanced Spark Settings Automatic Optimization |
|
Output
- Visual Output
-
- A
Model Training Summary, which describes the parameters selected, model training results, output location of the results, and the number of rows processed.
Training data Log Likelihood (entire corpus): Lower bound on the log likelihood of the entire corpus.
Training data Average Log Likelihood (per document): Log likelihood/total number of documents
Training data Log Perplexity (per token): Upper bound on the log perplexity per token of the provided documents given the inferred topics (lower is better). In information theory, perplexity is a measurement of how well a probability distribution (or probability model) predicts a sample, and is a common measure of model performance in topic modeling. More specifically, it measures how well the word counts of the documents are represented by the word distributions that the topics represent. A low perplexity indicates the probability distribution is good at predicting the sample.
- Topic Description (top X terms) data set (stored in HDFS): top X terms per topic with their associated weights:
- Full Topic Distribution data set (stored in HDFS): full documents' distribution over topics (not ordered, all topics displayed):
- Topic Distribution (top X topics) data set (stored in HDFS): top X topics per document with their associated weights:
- Featurized data set (stored in HDFS): featurized data set used as input for LDA algorithm:
(Only if Feature Hashing option is selected for N-Gram Selection Method)
- N-Grams from Feature Hashing data set (stored in HDFS): list of n-grams included in each feature used in LDA (from hashing):
- A
Model Training Summary, which describes the parameters selected, model training results, output location of the results, and the number of rows processed.
- Data Output
- The main output of the LDA Trainer is an LDA model that can be connected to the LDA Predictor operator to predict topics on new documents. Several HDFS tabular data sets created from the training documents (Topic Description, Full Topic Distribution, Top Topic Distribution, Featurized data set) also are stored in HDFS and can be dragged onto the canvas for further analysis.






Additional Notes
- Extra Resources
-
- https://en.wikipedia.org/wiki/Latent_Dirichlet_allocation
- https://github.com/thvasilo/spark/blob/master/docs/mllib-clustering.md
- https://databricks.com/blog/2015/03/25/topic-modeling-with-lda-mllib-meets-graphx.html
- https://www.quora.com/What-are-good-ways-of-evaluating-the-topics-generated-by-running-LDA-on-a-corpus