LDA Predictor
Uses both the model trained by the LDA Trainer and a tabular data set to output topic prediction for the new documents in various formats.

Information at a Glance
| Category | NLP |
| Data source type | HD |
| Sends output to other operators | Yes1 |
| Data processing tool | Spark |
This operator also stores in HDFS the Featurized data set used as input for LDA Prediction (and created from the featurization parameters specified in the LDA Trainer). You can drag this data set onto the canvas for further analysis.
For more information about using LDA, see Unsupervised Text Mining and LDA Training and Model Evaluation Tips.
Input
The LDA Predictor requires the following 2 inputs.
- The output model from an LDA Trainer.
- A tabular data set with at least a unique document ID column and a text content column (for example, output of the Text Extractor operator).
- Bad or Missing Values
- If a row contains a null value in at least one of the Doc ID column or Text column, the row is removed from the data set. The number of null values removed can be listed in the Summary section of the output (depending on the chosen option for Write Rows Removed Due to Null Data To File).
Configuration
| Parameter | Description |
|---|---|
| Notes | Any notes or helpful information about this operator's parameter settings. When you enter content in the Notes field, a yellow asterisk is displayed on the operator. |
| Document ID Column
*required |
Column that contains the document unique ID (String, Int, or Long). |
| Text Column
*required |
Column that contains the document text content (that is featurized based on N-Gram Dictionary Builder and Featurization input parameters). |
| Other Columns to Keep | Columns to keep in the output data set. |
| Write Rows Removed Due to Null Data To File
*required |
Rows with null values (in
Doc ID Column or
Text Column) are removed from the analysis. This parameter allows you to specify that the data with null values be written to a file.
The file is written to the same directory as the rest of the output. The filename is bad_data.
|
| Compression | Select the type of compression for the output.
Available Avro compression options are the following. |
| Output Directory | The location to store the output files. |
| Output Name | The name to contain the results. |
| Overwrite Output | Specifies whether to delete existing data at that path. |
| Advanced Spark Settings Automatic Optimization |
|
Outputs
- Visual Output
-
- A tabular data set output with the following columns (which can be further filtered, depending on the columns needed for the user's specific use case):
- Doc ID Column and Pass Through columns selected
- top_topics_summary column with the top topics and their corresponding weights in a dictionary format (the number of top topics displayed corresponds to the Max Topics to Describe Documents parameter set in the LDA Trainer).
- Full topic distribution weights (weight_topic_X columns)
- Top topic distribution as pairs of columns topic_ranked_X, weight_topic_ranked_X). The number of top topics displayed corresponds to the Max Topics to Describe Documents parameter set in the LDA Trainer)
- Featurized data set (stored in HDFS): featurized data set used as input for LDA prediction:
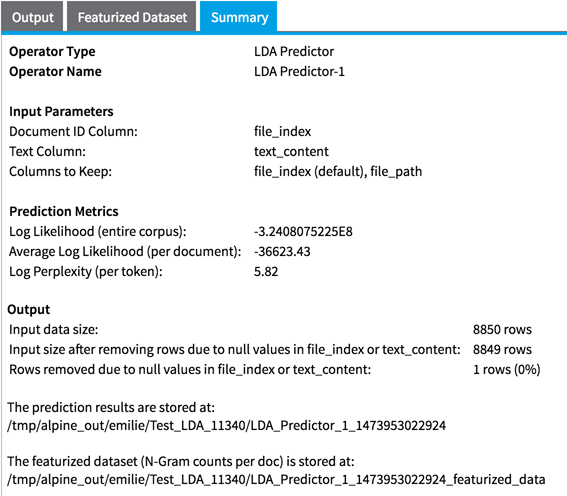
- Summary tab that describes the parameters selected, model prediction results, output location of the results, and the number of rows processed
Training data Log Likelihood (entire corpus): Lower bound on the log likelihood of the entire corpus.
Training data Average Log Likelihood (per document): Log Likelihood/Total Number of Documents
Training data Log Perplexity (per token): Upper bound on the log perplexity per token of the provided documents, given the inferred topics (lower is better). In information theory, perplexity is a measurement of how well a probability distribution (or probability model) predicts a sample, and is a common measure of model performance in topic modeling. More specifically, it measures how well the word counts of the documents are represented by the word distributions represented by the topics. A low perplexity indicates the probability distribution is good at predicting the sample.
- A tabular data set output with the following columns (which can be further filtered, depending on the columns needed for the user's specific use case):
- Data Output
- This is a semi-terminal operator. It can be connected to any subsequent operator at design time, but it does not transmit the full output schema until the user runs the operator. The partial output schema at design time is only the first columns of the output(Doc ID Column,
Pass Through columns selected and
top_topics_summary column). After running it, the output schema is automatically updated, and subsequent operators turn red in case the UI parameters selection is no longer valid.
Note: The final output schema of the Transpose operator is cleared you take one of the following actions.
In this case, the output schema transmitted to subsequent operators again becomes the partial schema defined at design time (hence, subsequent operators can turn invalid), and you must run the Transpose operator again to transmit the new output schema.