N-gram Dictionary Loader
Creates an N-gram dictionary object from a dictionary data set input (with the exact same columns as the output dictionary data set created by the N-gram Dictionary Builder operator), and the location of the N-gram dictionary builder configuration file (which is always stored in HDFS when training an N-gram Dictionary Builder operator and has the output suffix _dictInfo).

Information at a Glance
For more information, see N-gram Dictionary Builder.
With this operator, you can reuse an N-gram dictionary without having to retrain the N-Gram Dictionary Builder operator each time. You can filter a dictionary created by an N-Gram Dictionary Builder operator in a custom way, and then use it as the new dictionary data set to create an N-gram dictionary object that can be used with Text Featurizer or LDA Trainer operators.
Input
A tabular data set that represents an N-Gram dictionary (most commonly the output dictionary of an N-Gram Dictionary Builder operator, which has been filtered out), with the exact same column names and types as the N-Gram Dictionary Builder data set output.

Restrictions
This operator requires an input with the exact same column names and types as the N-Gram Dictionary Builder data set output; otherwise, an error occurs.
Configuration
Output
- Visual Output
- Visual output includes
Dictionary,
Corpus Statistics, and
Summary sections.
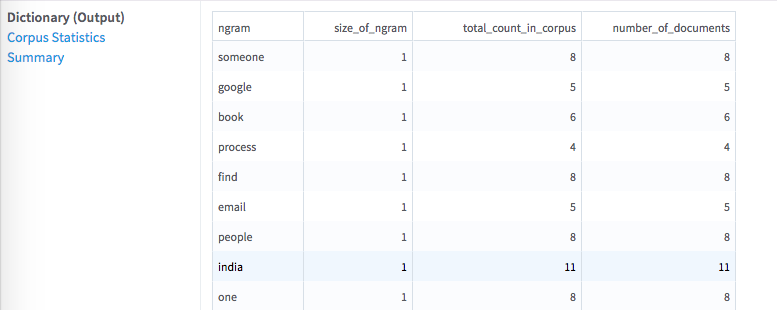
- Dictionary
- A table that shows the first preview of the n-gram dictionary loaded by the operator and passed on to future operators.
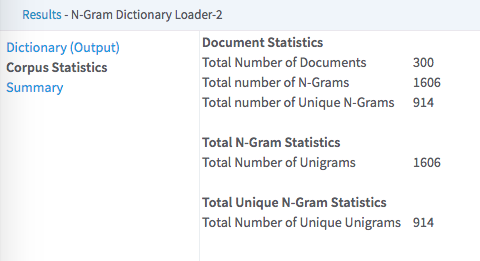
- Corpus Statistics
- Shows aggregate counts for number of documents, n-grams, and unique tokens found.
- Summary
- Contains some information about which parameters were selected and where the results were stored. Use this information to navigate to the full results data set.

- Data Output
- The N-gram dictionary object that can be connected to a Text Featurizer or LDA Trainer operator (in combination to a data set input).