N-gram Dictionary Builder
A sequence of tokens (one or greater) that might appear in a text corpus. The N-gram Dictionary operator parses each document in the corpus into tokens, and then into all possible n-grams (combinations of sequential tokens).

Information at a Glance
For more detailed information about working with N-gram Dictionary Builder, see Test Corpus Parsing.
Input
A corpus of documents represented as a data set with one row per document and at least one column of text. You can select the column with the text to analyze from the Text Column parameter.
Configuration
| Parameter | Description |
|---|---|
| Notes | Any notes or helpful information about this operator's parameter settings. When you enter content in the Notes field, a yellow asterisk is displayed on the operator. |
| Text Column | Select the column with the text of each document. |
| Maximum Size of N-Gram | Must be 1, 2 (the default), or 3 (Unigrams, Bigrams, or Trigrams). |
| Case Insensitive | If yes (the default), all words in corpus are considered lowercase, so "Fish" and "fish" would be considered the same token. |
| Use Sentence Tokenization |
|
| Use Stemming |
Stemming means reducing the forms of a word to a single word. For example: "swims", "swimmer", and "swimming" would all be parsed into the token "swim". Stemming is its own complicated subfield of linguistics, so for simplicity, we use the Porter Stemmer from apache.open.nlp. |
| Filter Stop Words |
Stop words are words that are very common or not useful for the analysis; for example, "a", "the", and "that". You can specify your own list of stop words in the Stop Words File parameter, or use our default list of stop words here. |
| Stop Words File | If left at the default value, a standard set of stop words is used. You can find this list
here.
Otherwise, choose a file that contains a list of stop words. This list must be one word per line and should be small enough to fit in memory. |
| Output Directory | The location to store the output files. |
| Output Name | The name to contain the results. |
| Overwrite Output | Specifies whether to delete existing data at that path. |
| Advanced Spark Settings Automatic Optimization |
|
Outputs
- Visual Output
-
Three sections are displayed after the operator is run:
- Dictionary
- A table that shows the first preview of the n-gram dictionary generated by the operator and passed on to future operators.
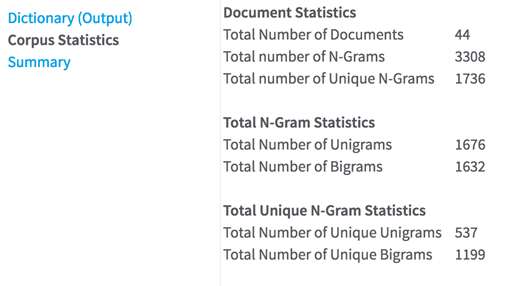
- Corpus Statistics
- Shows aggregate counts for number of documents, n-grams, and unique tokens found, as shown in the following example.
- Summary
- Contains some information about which parameters were selected and where the results were stored. Use this information to navigate to the full results data set.

Additional Notes
The data output of this operator is written to HDFS as a delimited file, but is not recognized by Team Studio as a tabular data set. This is because it is a special n-gram dictionary type that is only recognized by the Text Featurizer operator.
Although you cannot connect a transformation operator such as Summary Statistics to this operator directly, you can go to the location of the results on HDFS (specified in the Summary tab of the results pane), drag the file(s) onto your workflow, and use that as input to other Team Studio operators. However, keep in mind that, if you use this method, the files might be stored in multiple parts.